
機器學習部分關鍵詞解釋
1. 概述
(1)機器學習功能:從已有的資料中通過一定的方式方法學習產生一個能適應相同分佈的新資料的模型。
(2)解決的主要問題:分類(離散值)、迴歸(連續值)。分類的應用場景:比如蘋果、香蕉和梨子,無法量化,那麼對它們採取一定的編碼方式進行分類。迴歸的應用場景:標籤具有具體的連續值,比如預測一個人身高與年齡的關係,身高就是連續值,這個過程就是迴歸。
(3)過程:通過對已有的資料特徵矩陣分析,然後用一種方法去產生隱含的模型引數。(狹義地講:可以看做用一個模型去擬合(擬合屬於迴歸)已有的資料的過程,比如用函式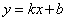 擬合二位資料點)
擬合二位資料點)
1. 關鍵詞解釋
關鍵詞:模型、凸優化、特徵矩陣、標籤、訓練集、測試集、損失函式(loss)、求解器(solver)、啟用函式(Activation)、懲罰項、欠擬合、過擬合、正則化。
模型:通俗地講就是函式與操作的疊加,一個將輸入進行操作,然後得到一個或一組輸出值。
凸優化(重要):雖然本身單獨已經是一個內容,但是機器學習的過程是建立在凸優化基礎上的。優化理論三要素:目標函式、約束條件、自變數。舉個簡單的例子,二維線性規劃,目標函式和約束條件都是二元線性方程,自變數即x。而凸優化簡單來講就是保證這個求解在這個約束範圍內不存在駐點解(多極值點)。
特徵矩陣:資料的存在形式,一般以一個矩陣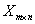 形式存在,m為資料的個數,n為資料的特徵維度(個數)。
形式存在,m為資料的個數,n為資料的特徵維度(個數)。
標籤:一般以一個向量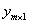 表示,表示一組特徵對應的值,這個y如果是離散值(類別),那麼一般稱其為標籤。
表示,表示一組特徵對應的值,這個y如果是離散值(類別),那麼一般稱其為標籤。
訓練集:需要訓練的資料,通常情況下即上文提到的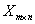
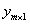 組成的m*(n+1)的矩陣。
組成的m*(n+1)的矩陣。
測試集:模型經過訓練集訓練,已經得到了模型引數,需要進行驗證的資料集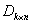 資料。
資料。
損失函式:由於機器學習的資料矩陣形式基本很固定,然後需要確定一個模型函式假定為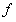 ,訓練的目標是這個
,訓練的目標是這個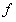 擬合得到的
擬合得到的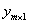 和訓練集資料對應的
和訓練集資料對應的 差距儘可能小,所以目標函式即是
差距儘可能小,所以目標函式即是

也可以寫作
這裡是一行資料的偏差,平法之後求和起來求和就是全部資料的偏差,這裡使用的是最小二乘的形式,當然損失函式不止一種形式,還有交叉熵,均方差等等,需根據實際情況選取。
求解器:得到了目標函式和約束條件之後,也得知了求解的物件之後,就成為了典型的有約束優化問題,這種問題往往沒有辦法直接得到符號解,通常採用數值方法來求解。求解器就是求解方法,一般指的就是梯度下降法、座標下降法、擬牛頓法等等方法。經過一定次數的迭代之後會得到一個極值點(不一定是最值點)。
啟用函式:主要在神經網路模型裡面出現,因為神經網路發展出了深度學習,所以單獨拿出來提一下,用來判斷神經節點是否啟用的函式,一般來講,0為死,1為啟用。啟用函式的樣式有很多,不具體展開。
懲罰項:主要用在目標函式中,常見於優化理論裡,通俗地講就是修正係數/函式,原始函式存在著各種不足,需要在原始函式後加/乘/取對數/指數/等等操作來修正這個目標函式的準確性。
欠擬合:指的是模型非線性表達能力不足時產生的現象,也表明模型的線性程度較高,通俗地講就是不能很好擬合原始資料集。
過擬合:指的是模型非線性表達能力過強時產生的現象,具體表現為模型在訓練集上表現非常好,但是在測試集上表現很差。
正則化:屬於資料預處理的範疇,很多時候,因為有了一些先驗經驗,人們希望對資料進行一定的預處理得到一些結果,於是用已有的模型正則式直接套在資料集上,看看效果如何。此外機器學習的懲罰項往往和求解的引數直接相關,故懲罰項也經常叫做正則項。