物體姿態估計——DeepIM
- 《DeepIM: Deep Iterative Matching for 6D Pose Estimation》 2018,Yi Li et al. DeepIM
1.引言: 本文,作者提出了一種新的深度神經網路對物體的6D姿態(3D位置和3D方向)進行估計,命名為DeepIM。採用對影象進行直接回歸物體姿態的方式,準確率是有限的,通過匹配物體的渲染影象可以進一步提高準確率。即給定初始姿態估計,對合成RGB影象進行渲染來和目標輸入影象進行匹配,然後在計算出新的更準的姿態估計。 1)Depth資訊侷限性: 最新的技術已經使用深度相機(depth cameras)為物體的姿態估計,但這種相機在幀速率、視場、解析度和深度範圍等方面還存在相當大的侷限性,一些小的、薄的、透明的或快速移動的物體檢測起來還非常困難。 2)RGB資訊侷限性:
傳統的6D姿態估計:將2D影象中提取的區域性特徵與待檢測物體3D基準模型中的特徵相匹配來求解R和T,也就是基於2D-3D對應關係求解PnP問題。但是,這種方法對區域性特徵依賴太強,不能很好地處理無紋理的目標。 為了處理無紋理目標,目前的文獻有兩類方法: 1) 學習估計輸入影象中的目標關鍵點或畫素的3D模型座標。 2) 通過離散化姿態空間將6D姿態估計問題轉化為姿態分類問題,或轉化為姿態迴歸問題。 這些方法雖然能夠處理無紋理目標,但是精度不夠高。
2.DeepIM迭代結構:
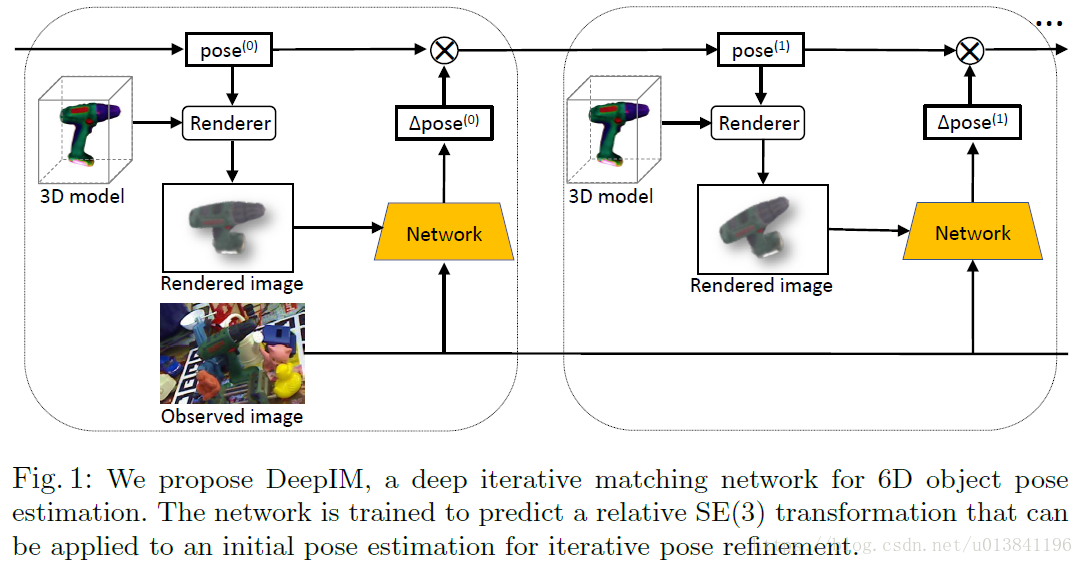
3.演算法流程
如果目標在輸入影象上是非常小的,它是困難的去提取有用的特徵。如下圖所示,作者為了獲得足夠的資訊進行姿態匹配,對觀測影象進行放大,並在輸入網路前進行渲染。要注意的是,在每次迭代過程中,都會根據上一次得到的姿態估計來重新渲染,這樣才能通過迭代來增加姿態估計的準確度。
Zoom in:

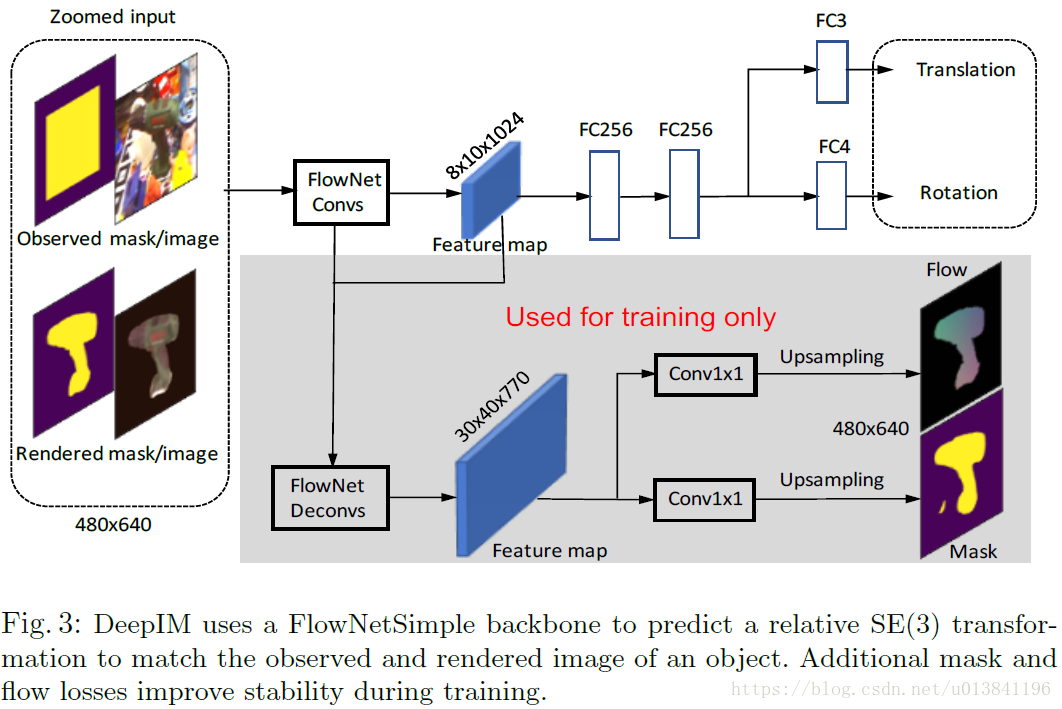
4.Untangled Transformation Representation
通常使用四元數或尤拉角來表示旋轉矩陣和一個向量表示平移,因此一個完成的轉換矩陣可以寫成,給予一個原始目標姿態。
通常目標從初始位置到新位置的旋轉與平移變換關係如下所示:
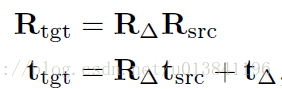
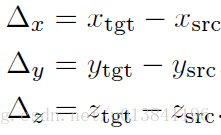
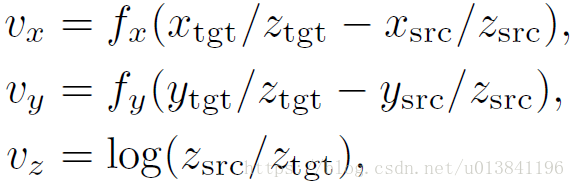
5.Matching Loss
模型訓練的損失函式,通常直接的方法是將旋轉和平移分開計算,比如用角度距離表示旋轉誤差,L1距離表示平移誤差,但這種分離的方法很容易讓旋轉和平移兩種損失在訓練時失衡。本文作者提出了一種同時計算旋轉和平移的Point Matching Loss 函式,來表示姿態真值和估計值之間的損失。其中,xj表示目標模型上的三維點,n表示總共用來計算損失函式的點個數,本文中n=3000。
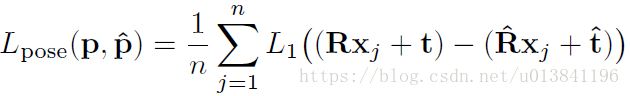
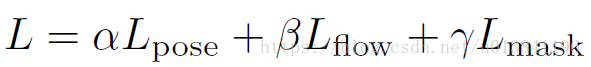
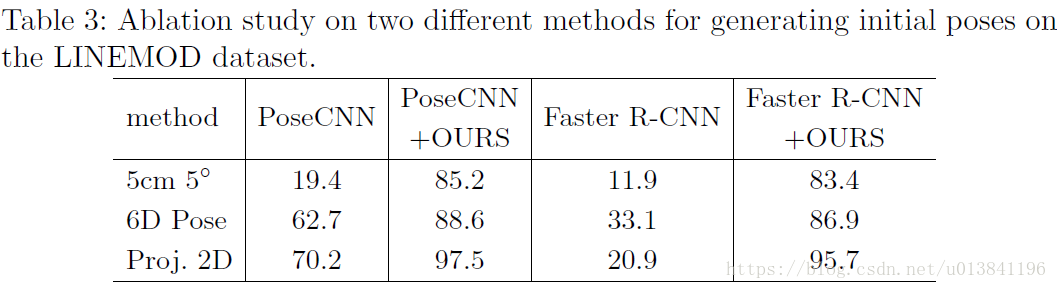
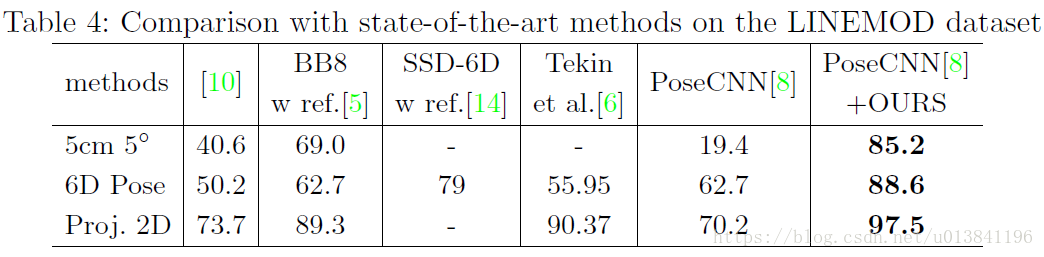
6.實驗結果:
作者主要使用了LINEMOD和OCCLUSION資料集。
在LINEMOD資料集上作者分別使用了PoseCNN和Faster R-CNN初始化DeepIM網路,發現即使兩個網路效能差異很大,但是經過DeepIM之後仍能得到差不多的結果。