
《Binary Multi-View Clustering》論文閱讀
出自:IEEE Trans. on Pattern Analysis and Machine Intelligence, 2018.
一、主要解決的問題
1、多視角的大尺度的資料集聚類效能表現欠佳;
2、實值聚類消耗較大的記憶體資源和計算資源;
2、編碼和聚類是獨立的,不能相互作用。
二、創新點
1、BMVC是第一個使用二進位制編碼技術解決大規模多檢視聚類問題的方法,BMVC同時從多個檢視和聯合優化二進位制編碼和聚類。
2、提出了一種交替優化演算法用於解決離散的優化問題,。針對二值聚類中心學習的關鍵子問題,還提出了一種自適應離散近似線性方法(ADPLM)。
3、BMVC具有較好的聚類效能,還明顯更少的計算時間和記憶體開銷,記憶體和時間上快的不止一點,這一點真的很好。
三、文章概要:
文章是編碼的多視角聚類問題。首先說明什麼是多視角和如何編碼,然後從雜湊編碼聯合聚類模型、優化以及實驗分析三個方面簡述文章主要思想和實驗設計。
所謂多視角,引用原文:1. Different to single-view clustering using singular data descriptor, in this paper, we first describe each data point (e.g., an image) by various features (e.g., different image descriptors, such as HOG, Color Histogram and GIST) and then feed these features from multiple descriptors into our clustering. It is noteworthy that the “Multiview” in our paper indicates multiple image descriptors of features rather than multiple modalities. 簡單來說:本文多視角就是多種特徵。
1、雜湊編碼
為什麼要進行編碼呢?
第一,針對實值聚類需要較大的記憶體資源,尤其是譜聚類方法,對較大尺度的影象資料集需要佔用很大的記憶體,編碼能夠對資料特徵進行降維處理,儘可能的保留了樣本的自身特徵。第二、計算機能夠更容易處理編碼資料,降低計算複雜度。
如何編碼:對於任意一個視角(一種特徵),n為資料集中影象的數目,m是選取的錨點數。具體或稱如下圖。

怎麼樣讓編碼更好的體現特徵,設計瞭如下代價函式:
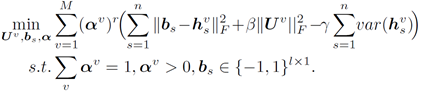
- 希望多視角學習得到的 M 個雜湊向量與 二值編碼B 能夠相似,最小化編碼和雜湊向量的L2正規化;
- 希望得到的投影轉換矩陣約簡單越好,最小化U的L2正規化;
- 希望資料點的二值碼分佈均衡,最大化其方差;
- 不同視角扮演的分量不同,不同視角優化不同權重。
2、雜湊編碼聯合聚類模型
聚類模型使用的是矩陣分解的方法,希望每個編碼b可以用一個聚類中心C和指示向量g(權重)的乘積來表示,希望分解的誤差最小。方法化較為常見,話不多說代價函式詳見下式:
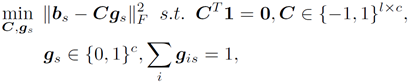
文章的一個主要創新點體現再此,作者將編碼和聚類同時進行優化,將兩者目標方程結合在一起,在學習過程中,相對於pipeline的方法更能將編碼和聚類相互作用體現出來。於是總的代價函式:
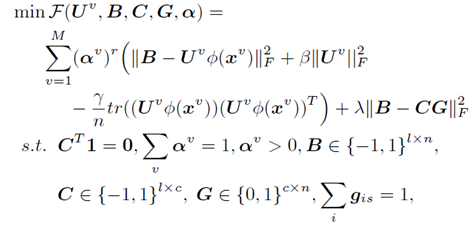
3、 優化
面對如此複雜的代價函式( 涉及到離散約束條件的np hard問題),如何進行優化訓練?
作者,使用了一個交替優化策略,即更新某個變數時,固定其它變數不變的迴圈更新方法。
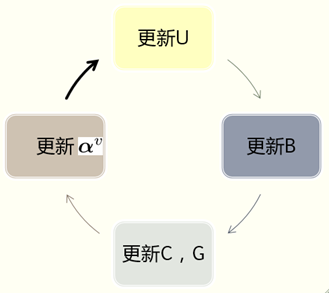
更新U ,固定其它量不變,總代價函式變為:
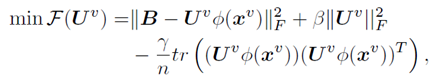
可見該項不含約束項,直接求導,令其倒數為0,得到此時最優U;
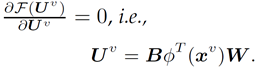
其中,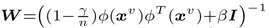
更新B , 總代價函式變為:
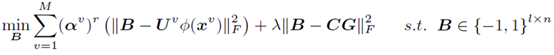
包含有離散約束量,怎麼辦呢,先化簡看看啦:
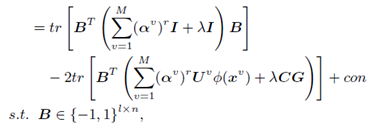
化簡到此,是不是有種“柳暗花明又一村“的感覺,第一項是常數,因為B轉置和B之間的項是一常數乘以單位陣,又因B轉置乘以B為常數,故第一項為常數。於是就變為求第二項的最小值,前面有(-)符號,使得B轉置乘以一項的值最大,這一項就為B。因為B為編碼,所以取符號操作,B為:
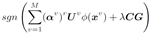

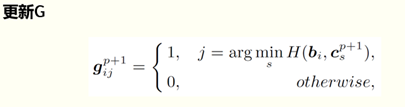
找出每個b到任何聚類中心的hamming距離,最近的給權值g為1,其它置為0。
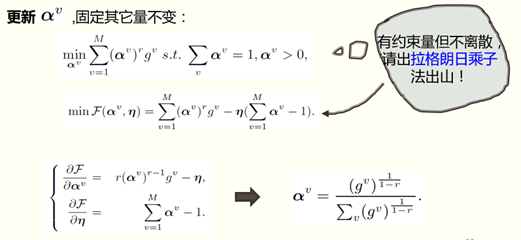
4、實驗分析
作者在Caltech101, NUS-WIDE-Obj, Cifar-10, Sun-397 YouTube Faces 實驗驗證。
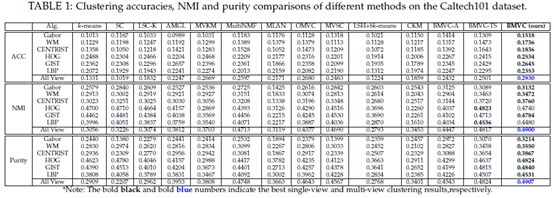
以Caltech101為例,精度上對比如圖,在多view上作者演算法是最高的,並且提升幅度較大。
效率上的對比,作者演算法相對於K-means時間上提升了60倍的速度,是不是相當驚人!

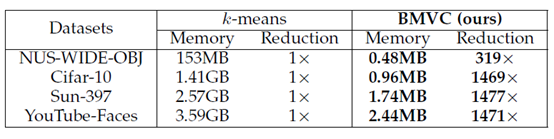
記憶體資源佔用對比,記憶體降低近1500倍,是不是更加驚人!
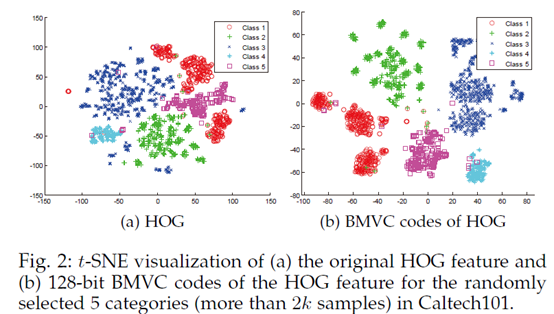
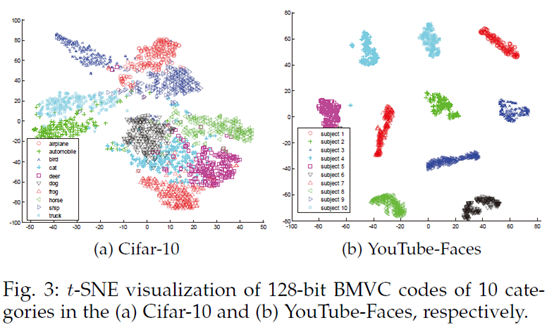
有人可能會有疑問,為什麼編碼後聚類效能能夠提升??來看編碼後的特徵分佈,如下兩圖,相同簇用同種顏色表示,編碼後的特徵簇間分佈更加分散,簇內分佈更加緊密,這就更容易對其進行聚類。以至於效果能夠提升。
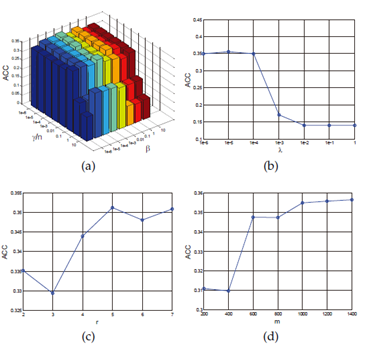
引數靈敏度分析:
手動調整引數較多,作者實驗分析了這些引數對效能的影響,好在模型對這些引數不敏感。引數在一定大範圍內能夠保持穩定的聚類效能!
四、總結
Contributions:
1. 提出了一種能夠降低計算複雜度和記憶體開銷的多視角聚類演算法;
2. 提供了一種編碼和聚類同時優化的思想;
Limitations:
1. 文章中所提,手動調整引數太多(源於太多的約束項)。
張亞超
2018年10月22日