
轉載 深度學習---ResNet
一、
ResNet在2015年被提出,在ImageNet比賽classification任務上獲得第一名,因為它“簡單與實用”並存,之後很多方法都建立在ResNet50或者ResNet101的基礎上完成的,檢測,分割,識別等領域都紛紛使用ResNet,Alpha zero也使用了ResNet,所以可見ResNet確實很好用。 下面我們從實用的角度去看看ResNet。
1.ResNet意義
隨著網路的加深,出現了訓練集準確率下降的現象,我們可以確定這不是由於Overfit過擬合造成的(過擬合的情況訓練集應該準確率很高);所以作者針對這個問題提出了一種全新的網路,叫深度殘差網路,它允許網路儘可能的加深,其中引入了全新的結構如圖1; 這裡問大家一個問題 殘差指的是什麼
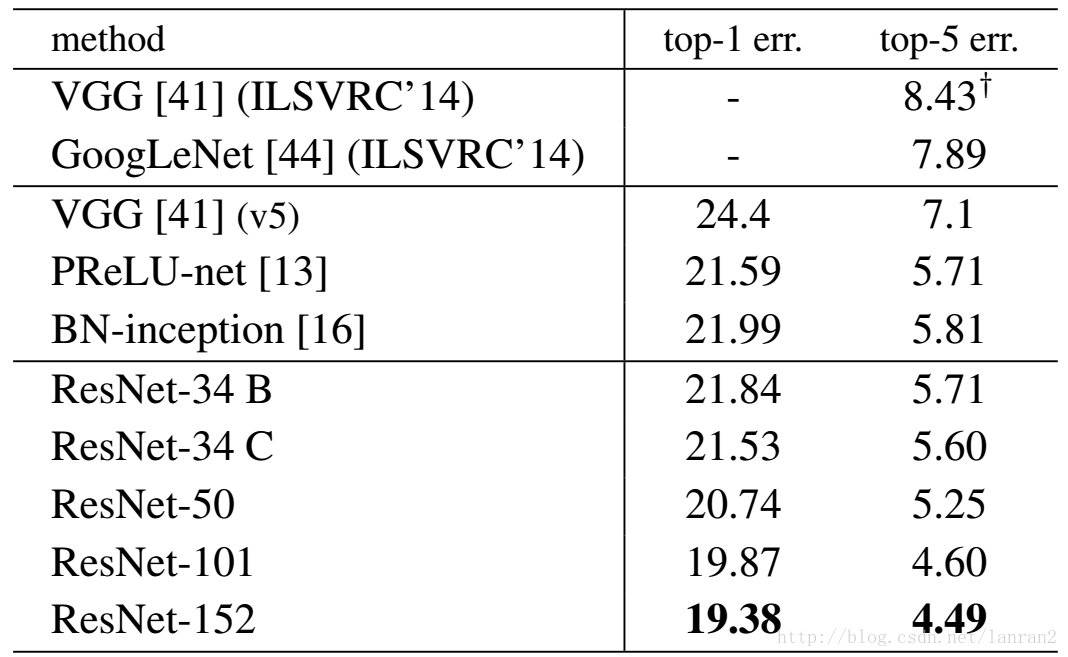 表1,Resnet在ImageNet上的結果
理論上,對於“隨著網路加深,準確率下降”的問題,Resnet提供了兩種選擇方式,也就是identity mapping和residual mapping,如果網路已經到達最優,繼續加深網路,residual mapping將被push為0,只剩下identity mapping,這樣理論上網路一直處於最優狀態了
表1,Resnet在ImageNet上的結果
理論上,對於“隨著網路加深,準確率下降”的問題,Resnet提供了兩種選擇方式,也就是identity mapping和residual mapping,如果網路已經到達最優,繼續加深網路,residual mapping將被push為0,只剩下identity mapping,這樣理論上網路一直處於最優狀態了2.ResNet結構
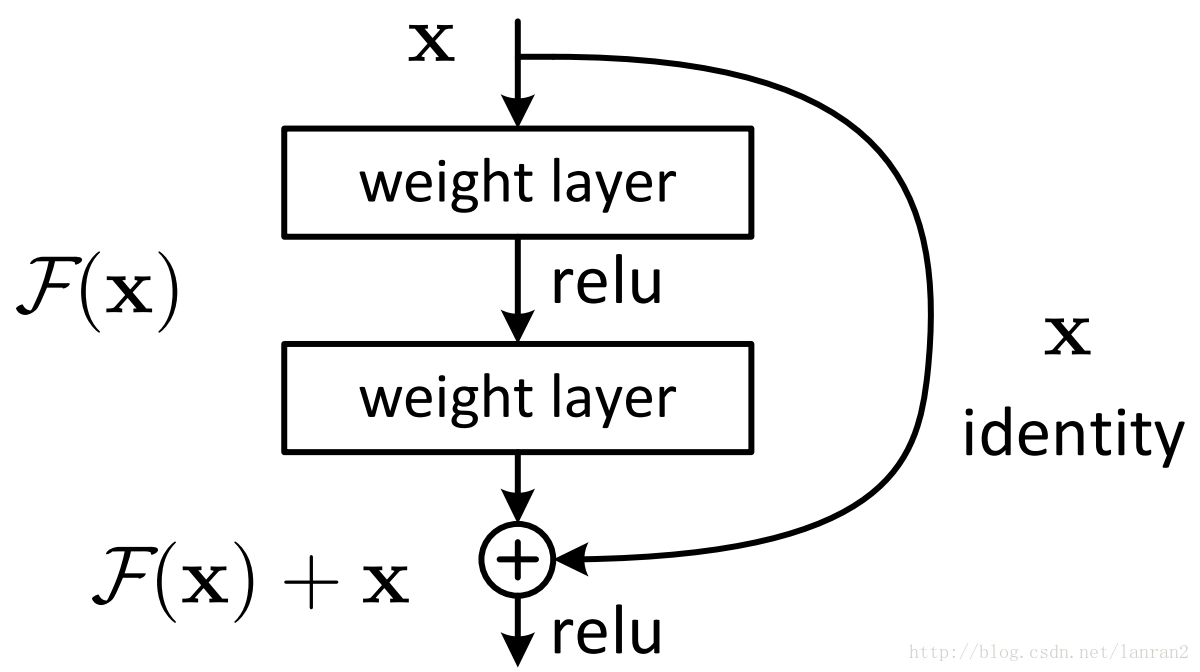
它使用了一種連線方式叫做“shortcut connection”,顧名思義,shortcut就是“抄近道”的意思,看下圖我們就能大致理解:
問大家一個問題:
如圖1所示,如果F(x)和x的channel個數不同怎麼辦,因為F(x)和x是按照channel維度相加的,channel不同怎麼相加呢?
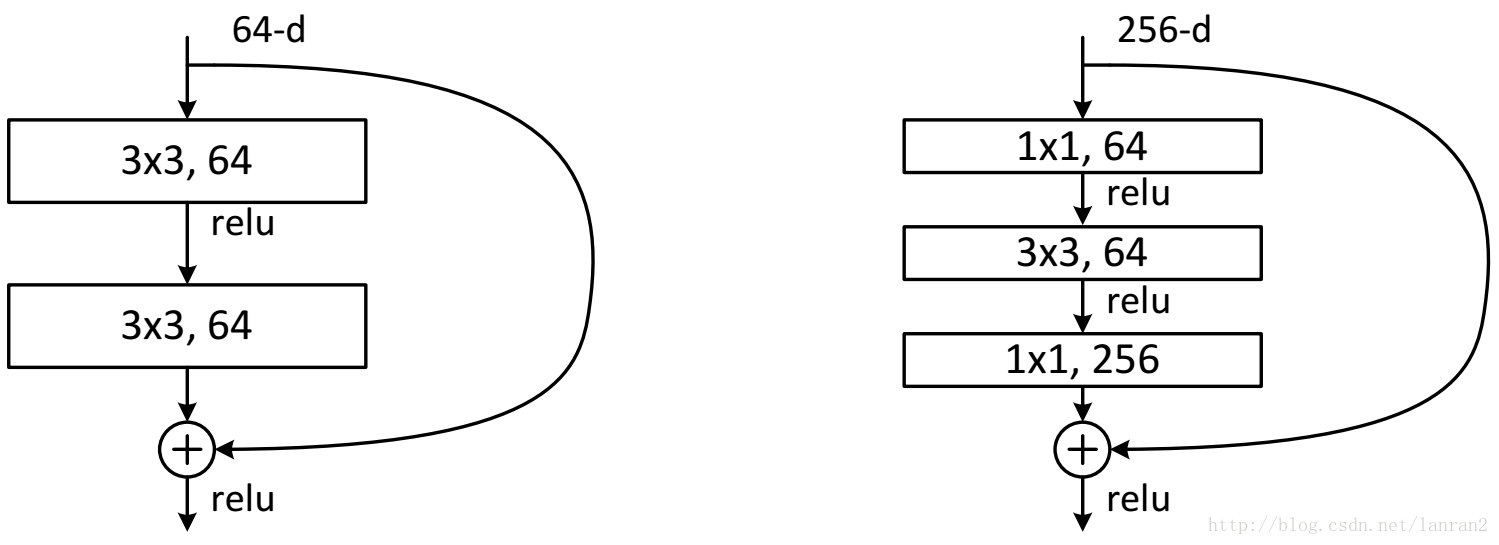
針對channel個數是否相同,要分成兩種情況考慮,如下圖:
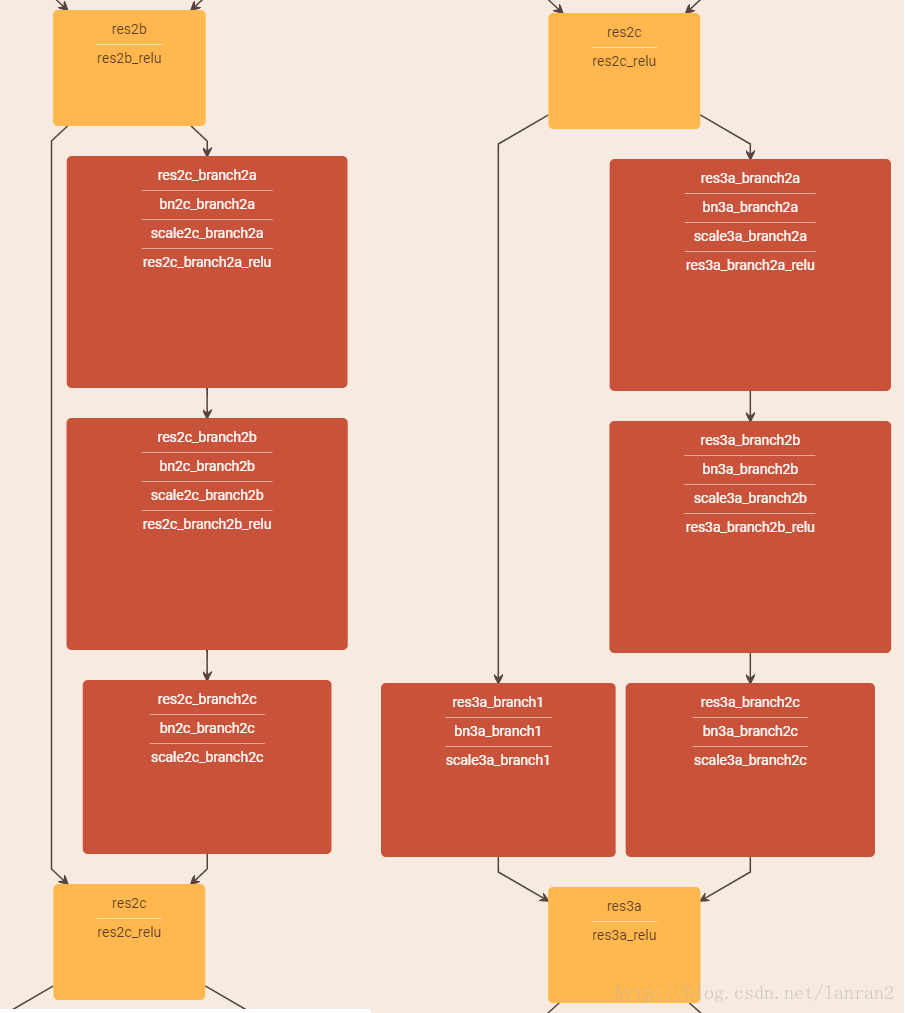
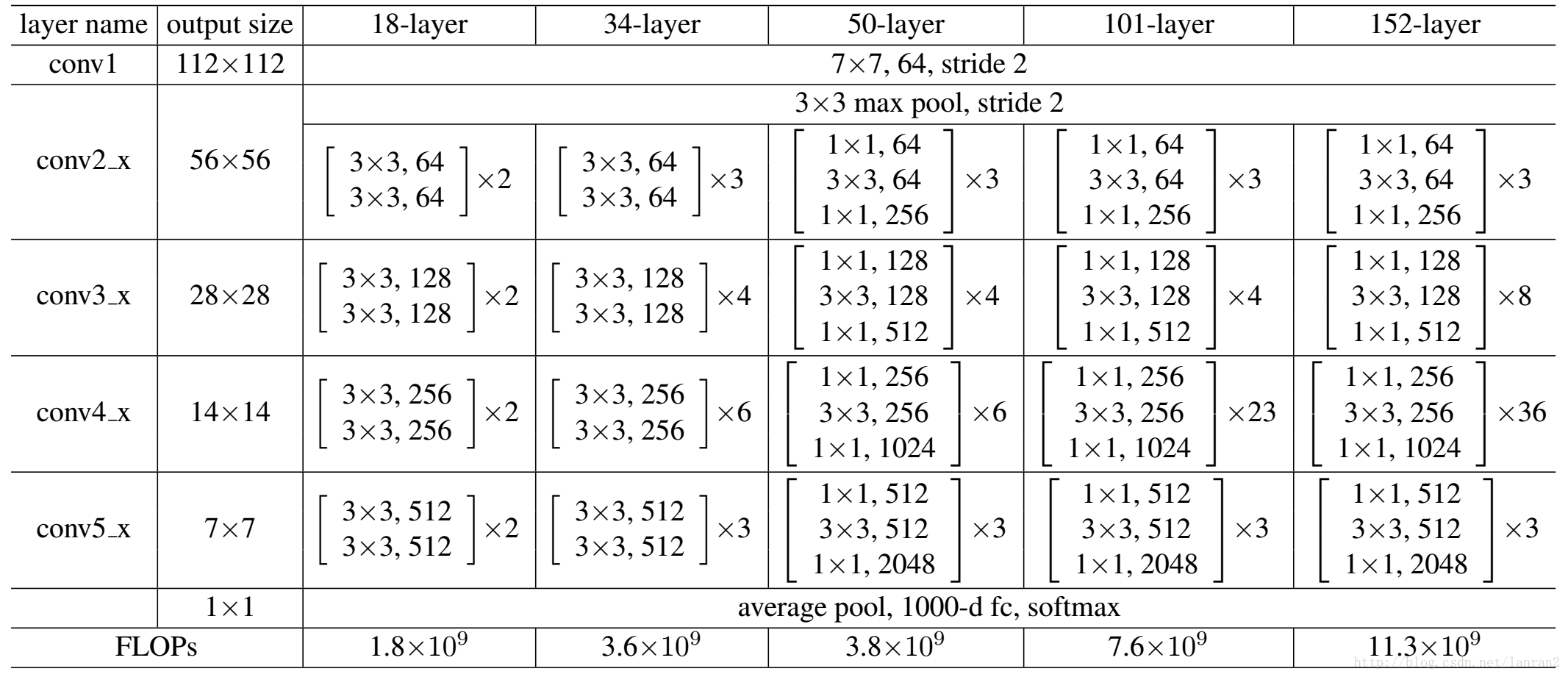
3.ResNet50和ResNet101
這裡把ResNet50和ResNet101特別提出,主要因為它們的出鏡率很高,所以需要做特別的說明。給出了它們具體的結構:
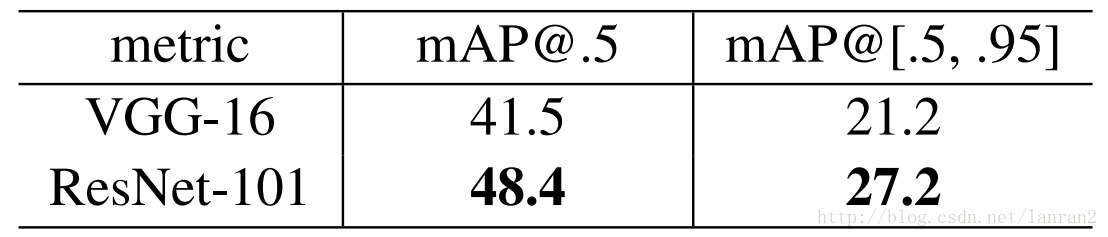
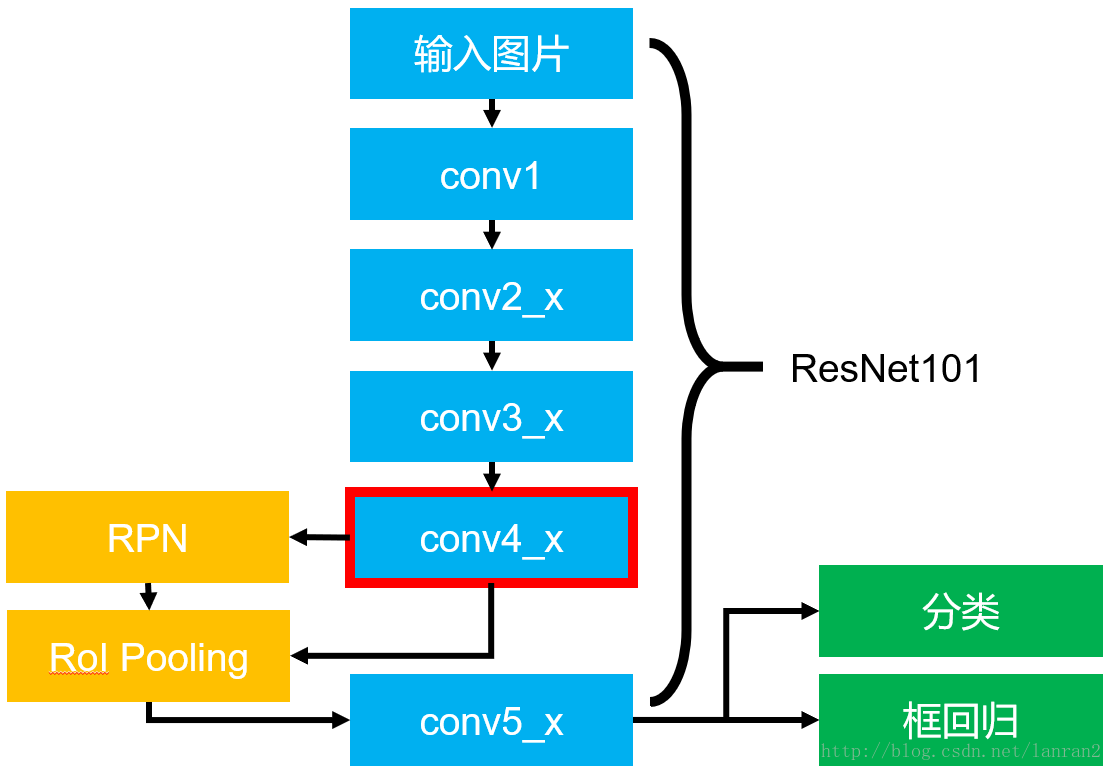
4.基於ResNet101的Faster RCNN
文章中把ResNet101應用在Faster RCNN上取得了更好的結果,結果如下:

本文結構:
我的閱讀筆記 1.ResNet之Building block 2.ResNet之CIFAR-10實驗結構 其他資料 1.ResNet作者何凱明博士在ICML2016上的tutorial演講 2.Bottleneck 3.diss ResNet的論文 論文翻譯 ---------------------------------------------------------------------------------------------------------------------我的閱讀筆記
1.ResNet之Building block
以下內容為我的理解,如有不正確的地方,還望各位大神指導!

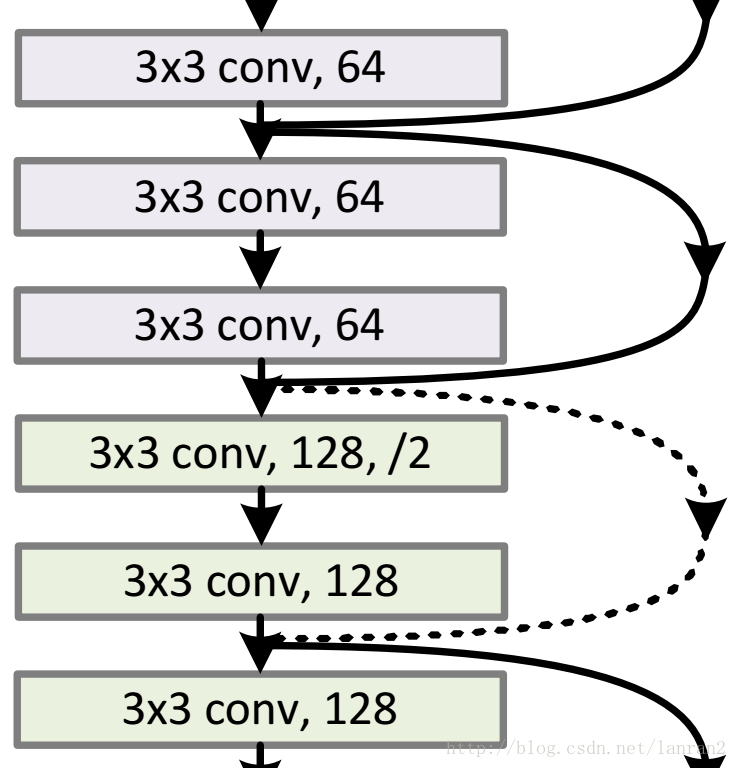
如圖所示為截選自ResNet-34的部分Buildingblock,論文作者對於identiy shortcut和projection shortcut的兩種options的描述,讓我困惑了很久,一直在糾結到底為什麼經過了3×3的卷積層以後,仍然能夠保持輸入輸出的一致?
以下是我對這個問題的理解:
首先,為了方便,我將buildingblock區分為兩類:
a. 第一類Building block(BB1)如上圖中實線部分的building block所示,特點為輸入輸出的維度一致,特徵圖個數也一致;
b. 第二類Building block(BB2)如上圖虛線部分的building block所示,特點為輸出是輸入維度的1/2,輸出特徵圖個數是輸入特徵圖個數的2倍(即執行了/2操作)。
區分了兩類Building block後,來來來跟我一起仔細讀一下論文:
1. “The identity shortcuts (Eqn.(1)) can be directly used when theinput and output are of the same dimensions (solid line shortcuts in Fig. 3).”
What?對於BB1,讓我直接相加?輸入都經過兩次3×3的卷積操作了啊喂,維度不一樣怎麼相加!好吧,經過查閱資料,作者可能委婉的表達了中間過程,但是我沒有發現吧。我琢磨著中間過程應該如下所示:

好啦,這下可以“can bedirectly used”了。接著讀論文:
2. “When the dimensions increase (dotted line shortcuts in Fig. 3),we consider two options: (A) The shortcut still performs identity mapping, withextra zero entries padded for increasing dimensions. This option introduces noextra parameter; (B) The projection shortcut in Eqn.(2) is used to matchdimensions (done by 1×1 convolutions). For both options, when the shortcuts goacross feature maps of two sizes, they are performed with a stride of 2.”
對於BB2,作者提供了兩種選擇:(A)如BB1的處理一樣,0填充技術,只是要填充好多0啊,這也是為什麼得到實驗4.1中的ResidualNetworks部分的“B is slightly better than A. We argue that this is because thezero-padded dimensions in A indeed have no residual learning.”的結論(P6右側中間)。(B)採用公式(2)的projectionshortcut,讓Ws與輸入做步長為2的1×1的卷積操作,這樣,輸入和輸出就具有相同的維數,接下來在進行相加操作就OK啦!過程如下圖所示:
 2.ResNet之CIFAR-10實驗結構
2.ResNet之CIFAR-10實驗結構
哎呀,對於我的理解能力來說,作者對基於ResNet的CIFAR-10的實驗網路結構描述的太混亂了!好不容易才搞清楚的。以n=3,20層的ResNet為例,具體結構如下表所示:
|
Output map size |
Output_size |
20-layer ResNet |
|
Conv1 |
32×32 |
{3×3,16} |
|
Conv2_x |
32×32 |
{3×3,16; 3×3,16}×3 |
|
Conv3_x |
16×16 |
{3×3,32; 3×3,32}×3 |
|
Conv4_x |
8×8 |
{3×3,64; 3×3,64}×3 |
|
InnerProduct |
1×1 |
Average pooling 10-d fc |
其他資料
1.ResNet作者何凱明博士在ICML2016上的tutorial演講
本文為何凱明博士在ICML2016上的tutorial演講以及相關PPT整理。裡面的翻譯有少量的錯誤,例如solution 應翻譯為“解”,plain net應翻譯為“普通網路”。
Resnet在ILSVRC 和COCO 2015上的五個主要任務軌跡中都獲得了第一名的成績,而且遠超過第二名。

大多數網路模型隨著網路深度的增加,準確率會趨於飽和,並且快速下降。但作者認為這並不僅僅是overfitting的原因,也是由於某些模型加深本身會導致增加訓練誤差。
ResNet的核心思想是:計算層到層的殘差,即F(x),以F(x)+x作為輸出。其特點為:A simple and clean framework of training “very” deep nets。
簡單介紹一下RestNet的細節:
① 在許多資料集中都能夠觀察到的普遍現象就是過深的普通網路具有更高的訓練誤差。但是,一個較深的模型理應具有更高的準確率。關於普通網路和Residual Net如下圖所示:

② Residual Net:H(x)是輸出,希望2層權重能夠擬合F(x),使得:
H(x)=F(x)+x
F(x)是一個關於恆等式殘差的對映。
a. If identity were optimal, easyto set weights as 0;
b. If optimal mapping is closer toidentity, easier to find small fluctuations.
③ 網路設計:
a. 全部採用3×3 conv操作(或者大部分採用)
b. Spatial size /2 -> # filter×2
c. 沒有FC層和Dropout層
④ 實驗結果表明,ResNet能夠在沒有任何困難的情況下得到訓練,並且實現更深的網路結構使其達到更低的訓練誤差和測試誤差。
⑤ 受裝置計算能力限制,作者也提出了另一個與原始ResNet複雜度相同的BottleNeck模型,它是一個逐層深入且實際可行的方案。詳細細節參考2.的連結及內容。
⑥ 作者分析了學習深度學習模型存在的問題和本文提出的對策:
a. 表徵能力:ResNet在表徵能力上不存在明顯優勢(只是重複的引數化),但是,能夠使加深模型變得切實可行;
b. 優化能力:能夠使前向/反向傳播演算法更加平穩,極大程度簡化/減輕(DBA)優化深度模型;
c. 一般化(Generalization)能力:ResNet未直接處理一般化問題,但是更深+更薄是一種很好的一般化手段。
以上對ResNet做了簡要介紹,瞭解到ResNet在加深網路模型,提高學習任務準確率等方面都有很大的優勢,不過也剛巧在學習本論文的當天就閱讀到推送的一篇論文,對ResNet提出質疑並進行了證明,詳細資訊參考連結3.
2.Bottleneck
作者主要介紹了ResNet的DeeperBottleneck Architectures(DBA),一個DBA共3×3=9層。如下圖:

本文作者參考Ryan Dahl的原始碼(https://github.com/ry/tensorflow-resnet),畫出了DBA內部網路的前三層,如下圖所示:

注意,56*56的map經過3*3的卷積核後輸出仍然是56*56的原因是兩邊是有補零的,來保證尺寸大小不變。
3.diss ResNet的論文
作者介紹,CornellUniversity的幾個人研究了ResNet,發現它所謂的“超深網路”只是個噱頭,並在NIPS上發表論文《Residual Networks are Exponential Ensembles of Relatively ShallowNetworks》,表明ResNet並不深,它本質上是一堆淺層網路的集合。

一個擁有三個block的ResNet可以展開為上右圖的形式,類似於多個網路的ensemble形態,所以精度很高。
① 論文作者證明,少個block情況下,對ResNet影響甚微,與之相比,VGGNet識別率慘不忍睹。因為,多線網路少個block,網路仍然是通的,單線網路少個block,網路斷開。

② 繼網路的“深度”和“寬度”兩項指標之後,作者根據網路包含的“子網路”數量,提出了一個新指標——multiplicity。
摘要
越深層次的神經網路越難以訓練。我們提供了一個殘差學習框架,以減輕對網路的訓練,這些網路的深度比以前的要大得多。我們明確地將這些層重新規劃為通過參考輸入層x,學習殘差函式,來代替沒有參考的學習函式。
我們提供了綜合的經驗證據,表明殘差網路更容易優化,並且可以從顯著增加的深度中獲得準確性。在ImageNet資料集上,我們對剩餘的網進行評估,其深度為152層,比VGG網41層更深,但仍可以保證有較低的複雜度。結合這些殘差網路在ImageNet測試集上獲得了3.57%的誤差,這一結果在ILSVRC2015分類任務中獲得了第一名。我們還對cifar 10進行了100和1000層的分析。
對於許多視覺識別任務來說,特徵表達的深度是至關重要的。僅僅由於我們的極深的表示,我們在COCO目標檢測資料集上獲得了28%的相對改進。深度殘差網路是我們參加LSVRC&COCO 2015比賽的基礎,我們還贏得了ImageNet檢測、ImageNet本地化、可可檢測和可可分割等任務的第1個位置。
1. 引言
深度卷積神經網路已經為影象分類帶來了一系列突破。網路深度是至關重要的。
在深度重要性的驅使下,一個問題出現了:學習更好的網路是否像堆更多的層一樣簡單?回答這個問題的一個障礙是眾所周知的“梯度消失/爆炸”,這阻礙了從一開始就收斂。然而,這個問題主要通過規範化的初始化和中間的標準化層(Batch Normalization)來解決,這使得具有數十層的網路通過隨機梯度下降(SGD)方法可以開始收斂。
當更深的網路能夠開始收斂時,退化問題就暴露出來了:隨著網路深度的增加,準確度就會飽和(這可能不足為奇),然後就會迅速下降。出乎意料的是,這種退化不是由過度擬合造成的,並且在適當的深度模型中加入更多的層會導致更高的訓練錯誤,正如我們的實驗所證實的那樣。
(訓練精度的)退化表明不是所有的系統都同樣易於優化。讓我們考慮一個較淺的架構,以及在它上面添加了更多的層的深層的架構。有一種解決方案可以通過構建到更深層次的模型(解決優化問題):增加的層是恆等對映,而其他層則是從學習的淺模型中複製出來的。這種構造方法表明,一個較深的模型不應產生比較淺的模型更高的訓練誤差。但實驗表明,我們現有的解決方案無法找到比這個構建方案好或更好的解決方案(或者在可行的時間內無法做到這一點)。
本文通過引入一個深層殘差學習框架來解決退化問題。我們沒有希望每一層都直接匹配所需的潛在對映,而是明確地讓這些層適合一個殘差對映。在形式上,將所需的潛在對映表示為H(x),我們讓堆疊的非線性層適合另一個對映F(x)=H(x)-x。原來的對映被重新定義為F(x)+x。我們假設優化殘差對映比優化原始的對映更容易。在極端情況下,如果一個標識對映是最優的,那麼將殘差值推到零將比通過一堆非線性層來匹配一個恆等對映更容易。
F(x)+x的表示式可以通過使用“shortcut connections”的前饋神經網路實現(圖2)。“shortcutconnections”是跳過一個或多個層。在我們的例子中,“shortcut connections”簡單地執行恆等,它們的輸出被新增到疊加層的輸出中(圖2)。恆等的“shortcut connections”既不增加額外引數,也不增加計算複雜度。整個網路仍然可以通過SGD對反向傳播進行端到端訓練,並且可以在不修改解決方案的情況下使用公共庫輕鬆實現。
我們對ImageNet進行了全面的實驗,以顯示其退化問題,並對其進行了評價。我們證明:1)我們極深的殘差網路很容易優化,但是當深度增加時,對應的普通網(簡單的疊層)顯示出更高的訓練錯誤;2)我們的深層殘差網可以很容易地從深度的增加中獲得精確的增益,產生的結果比以前的網路要好得多。
2. 相關工作
殘差表達
在影象識別中,VLAD是一種由殘差向量關於字典的編碼表示,而Fisher Vector可以被定義為VLAD的概率版本。它們都是影象檢索和分類的強大的淺層表示。對於向量化,編碼殘差向量比編碼原始向量更有效。
在低層次的視覺和計算機圖形學中,為了解決偏微分方程(PDEs),被廣泛使用的多網格法將系統重新設計成多個尺度下的子問題,每個子問題負責一個較粗的和更細的尺度之間的殘差解。多網格的另一種選擇是分層基礎的預處理,它依賴於在兩個尺度之間表示殘差向量的變數。研究表明,這些(轉化成多個不同尺度的子問題,求殘差解的)解決方案的收斂速度遠遠快於那些不知道殘差的標準解決方案。這些方法表明,良好的重構或預處理可以簡化優化問題。
Shortcut Connections
與我們的工作同時,HighwayNetworks提供了與門控功能的shortcut connection。這些門是資料相關的,並且有引數,這與我們的恆等shortcut connection是無引數的。當一個封閉的shortcut connection被關閉(接近於零)時,highway networks中的層代表了無殘差的函式。相反,我們的公式總是學習殘差函式;我們的恆等shortcut connection永遠不會關閉,在學習其他殘差函式的同時,所有的資訊都會被傳遞。此外,highway networks還沒有顯示出從增加深度而獲得的準確率的增長(例如:,超過100層)。
3. 深度殘差網路學習
3.1殘差學習
我們令H(x)作為需要多層神經網路去擬合的目標函式。如果假設多個非線性層可以逐漸近似一個複雜的函式,那麼等價於假設他們可以逐漸近似殘差函式,即H(x)-x。因此,與其讓期望這些層近似H(x),我們讓這些層直接近似殘差函式F(x)= H(x)-x。原始的函式則變成了H(x) = F(x)+x。儘管這兩種形式都應該能夠逐漸地近似期望的函式,但學習的輕鬆度可能是不同的。
這個重新制定的動機是由於退化問題的反直覺現象(圖一,左圖)。正如我們在引言中所討論的,如果新增的層可以被構造為恆等對映,那麼一個較深的模型的訓練錯誤不應該比相對更淺的模型訓練誤差大。退化問題表明,求解起在通過多個非線性層逼近恆等對映時遇到困難。利用殘差的學習方法,如果恆等對映是最優的,求解器也許只需將多個非線性層的權重簡單的置為零,以近似恆等對映。
在實際情況中,恆等對映不太可能是最優的,但是我們的重製可能有助於解決問題。如果最優函式更接近於標識對映,而不是零對映,相比於將其作為一個新函式的學習,解析器可以更容易地找到與恆等對映相關的擾動(即殘差)。我們通過實驗(圖7)顯示,習得的殘差函式一般都有很小的波動,這表明恆等對映提供了合理的前提條件。
3.2通過Shortcut的恆等對映
我們採取將每一個疊層都應用殘差學習。圖2中顯示了一個building block。正式地,在本文中,我們考慮一個定義為:
其中x和y是層的輸入和輸出向量。函式F(x,{wi})表示要學習的殘差對映。如圖2為兩個層的例子,F=w2(W1x),其中表示ReLU,為了簡化表示,省略了偏差b。F+x的操作是通過一個shortcutconnection將對應元素進行相加來執行的。在加法之後,我們採用了第二次非線性對映。(即(y),見圖2)。
等式(1)中的shortcut connection既沒有引入額外的引數,也沒有增加計算複雜度。這不僅在實踐中很有吸引力,而且在我們對普通的網路和殘差網路的比較中也很重要。我們可以公平地比較同時具有相同數量的引數、深度、寬度和計算成本(除了可以忽略的相對應的元素相加操作之外)的普通網路和殘差網路。
x和F的維數在等式(1)中必須相等。如果不是這樣的話(例如:當改變輸入/輸出通道時),我們可以通過shortcut connection來執行一個線性投影,以匹配維度:
我們也可以在等式(1)中使用一個矩陣Ws。但我們將通過實驗證明,恆等對映對於解決退化問題是足夠的,而且是經濟的,因此只有在匹配維度時才需要使用Ws。
殘差函式F的形式是靈活的。本文的實驗涉及到一個函式F,它有兩個或三個層(圖5),當然更多的層也是可以的。但是,如果F只有一個層,等式(1)與線性層y=W1x+x相似,我們沒有觀察到它的優勢。
我們還注意到,儘管上面的符號是為了簡單起見而使用完全連線的層,但它們適用於卷積層。函式F(x;{wi})可以代表多個卷積層。元素相加是一個通道接著通道,在兩個特徵圖上執行的。
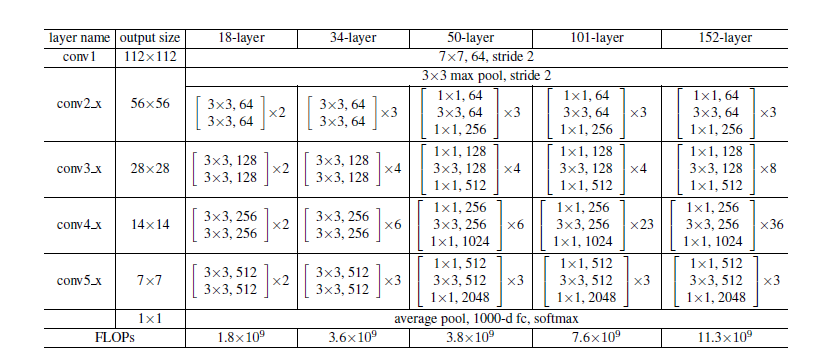
3.3網路結構
我們測試了各種各樣的普通/殘差網網路,並觀察到一致的現象。為了提供討論的例項,我們描述了ImageNet的兩個模型。
普通網路
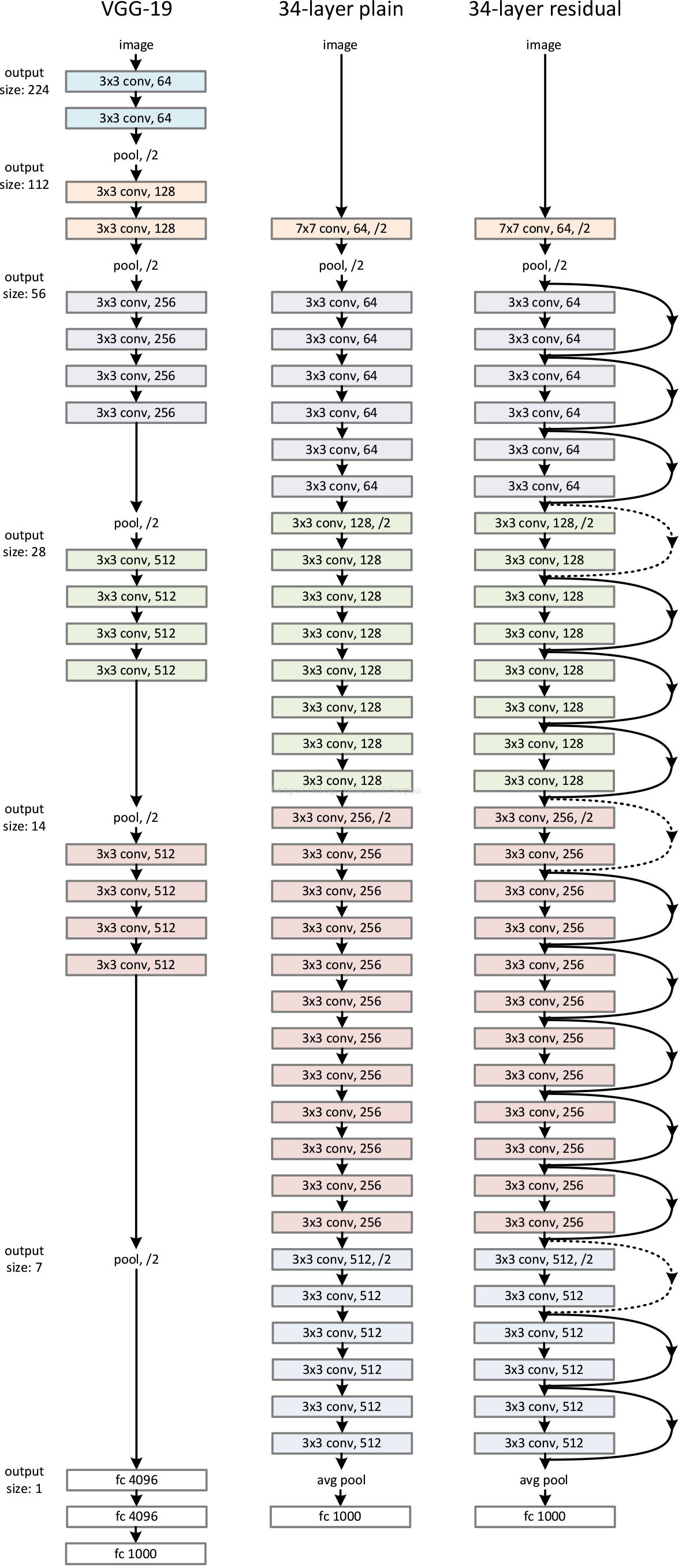
我們的基準線(圖3,中間)主要受VGG網路(圖3左)的啟發。卷積層主要有3×3的過濾器,並遵循兩個簡單的設計規則:(i)相同的輸出特性圖的大小,各層有相同數量的過濾器;(2)如果特徵圖的大小減半,那麼過濾器的數量就增加一倍,以保證每一層的時間複雜度相同。我們直接通過卷積層來進行向下取樣,這些層的步長為2。該網路以一個全域性平均池層和一個1000層的完全連線層和softmax來結束。圖3(中)的權重層數為34。
值得注意的是,我們的模型比VGG網路(圖3左)更少的過濾器和更低的複雜性。我們的具有34層的baseline有36億 FLOPs,只是VGG-19(19.6億FLOPs)的18%。
殘差網路
基於上面的普通網路,我們插入了shortcut connection(圖3,右),將網路轉換為對應的殘差版本。當輸入和輸出是相同的維度時,恆等shortcut(等式(1))可以直接使用(圖3實線)。當維度增加(圖3中虛線),我們提供兩個選擇:(A)short connection仍然執行恆等對映,用額外的零填充增加維度。這個選項不引入額外的引數;(B)等式 (2)中的投影shortcut用於匹配維數(由1×1卷積完成)。對於這兩個選項,當shortcut融合兩個大小的特徵圖時,它們的執行時的步長是2。
3.4實施
我們對ImageNet的實現遵循了[21、41]的實踐。為了擴大規模,[256,480]大小的影象被沿著短邊通過隨機取樣調整大小。從影象或它的水平翻轉中隨機抽取[224,224],每畫素減去平均。[21]中的標準顏色增強技術被使用。我們在每次卷積和啟用前都採取Batch Normalization。我們同[13]一樣初始化權重,從頭開始訓練普通網路和殘差網路。我們使用SGD的批量大小為256。學習率從0.1開始,當誤差停滯時,將學習率除以10,模型被訓練多大60萬次。我們使用0.0001的權重衰減,和0.9的momentum。根據[16],我們不使用Dropout層。
在測試中,為了比較研究,我們採用了標準的十折交叉驗證。為了得到最好的結果,我們採用了全卷積式的形式如[41,13],並在多個尺度上平均得分(影象被調整大小到更短的變,如224,256,384,480,640)。
4. 實驗
4.1ImageNet分類
我們在包含1000類的ImageNet2012分類資料集上評估我們的方法。模型在包含128萬的訓練資料將上訓練,在5玩的驗證影象上評估。我們最終的結果是由測試伺服器在10萬的測試集上獲得的。我們評估了前1和前5的錯誤率。
普通網路
我們首先評估18層和34層的普通網路。34層普通網路如圖3中間的網路所示。18層普通網路是同樣的形式。詳細結構請參考表1。
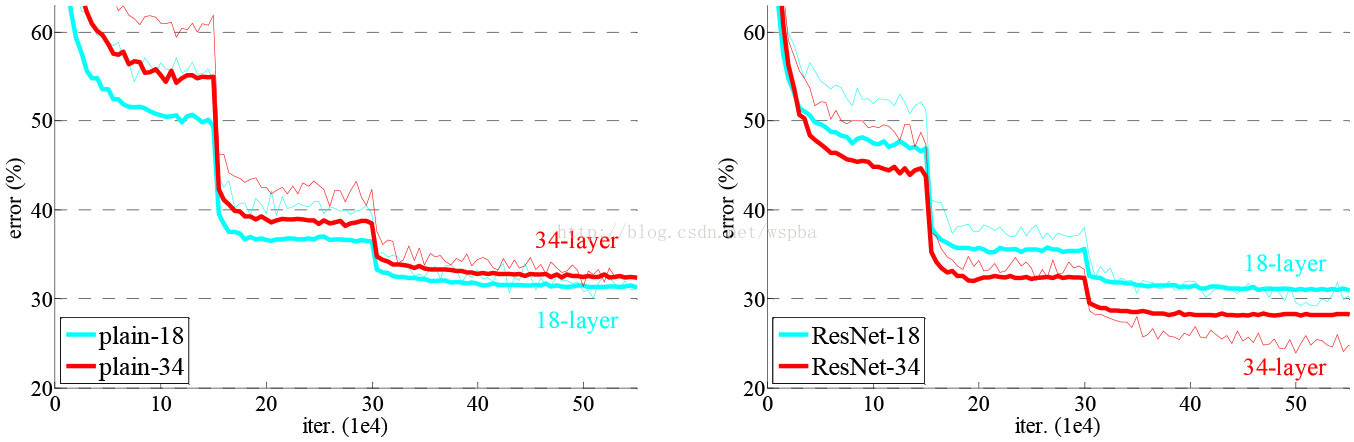
表2所示的結果說明,更深的34層普通網路比較淺的18層網路具有更高的驗證錯誤率。為揭露其原因,如圖4左,我們在訓練過程中比較它們的訓練/驗證誤差。我們觀察到了退化現象—儘管這個18層普通網路的解空間是34層的一個子空間,34層的普通網路在訓練過程中始終具有更高的訓練誤差。
我們認為這種優化問題不太可能是由梯度消失引起的。這個普通網路用BN訓練,這確保了傳播的訊號具有非零的方差。我們還驗證了反向傳播的梯度在BN中表現出了健康的規範。因此,無論是向前還是向後的訊號都不會消失。事實上,34層普通網路仍然能夠達到具有競爭力的準確率,說明求解器在某種程度上是可行的。我們推測,深度普通網路可能具有低指數的收斂速度,這將影響訓練誤差的減少。這種優化問題的原因在未來將會被研究。
殘差網路
接著我們評估了18層和34層的殘差網路。除了每對3×3的filters之間增加了shortcut連線外,基準結構和之前的普通網路相同,如圖3右所示。第一個對比(表2和圖4右),我們使用對所有的shortcut使用恆等對映,並使用0填充技術用於增加維度(操作A)。因此,與相應的普通網路相比,它們沒有增加額外的引數。
我們從表2和圖4中得到了三個主要的觀察結果。第一,在殘差學習中情況是相反的--34層的ResNet比18層的ResNet要好(2.8%)。更重要的是,34層ResNet展現出相當低的訓練誤差並可以概括驗證資料(即驗證資料有相同的實驗結果)。這表明,在這樣的設定下,退化問題得到了很好的解決,並且我們成功的從增加的深度獲得了精度的提高。
第二,與其相對應的普通網路相比,由於成功減少了訓練誤差 (圖4右與左),ResNet將top-1的誤差降低了3.5%(表2)。這一比較驗證了在極深系統中殘差學習的有效性。
最後,我們還注意到,18層的普通/殘差的網是相當精確的(表2),但是18層的ResNet更快速地收斂(圖4右與左)。當網路不太深(這裡有18層)時,當前的SGD求解器仍然能夠找到普通網路的優解。在這種情況下,ResNet通過在早期提供更快的聚合來使優化變得輕鬆。
恆等shorcut vs. 投影shortcut
我們已經證明了,不增加引數的恆等shortcut有助於訓練。接下來我們研究投影快捷方式(等式2)。在表3中,我們比較了三個選項:(A)用於增加維度的零填充shortcut,所有的shortcut都是不增加引數的(與表2和圖4相同);(B)用於增加維度的投影shortcut,其他快shortcut採用恆等shortcut;(ps,我認為他說的維度增加是指featuremap增加的部分)(C)所有的shortcut都採用投影。
表3顯示了這三個選項都比普通網路的要好得多。B比A稍微好一點。我們認為這是因為A的0填充的維度確實沒有殘差學習。C比B略好,我們將其歸因於許多(13)投影shortcut引入的額外引數。但是,a/b/c之間的微小差異表明,投射shortcut對於解決退化問題並不是必需的。因此,在本文的其餘部分中,我們不使用選項C,以減少記憶體/時間複雜度和模型大小。恆等shortcut不增加複雜度對於下面引入的Bottleneck結構的特別重要。
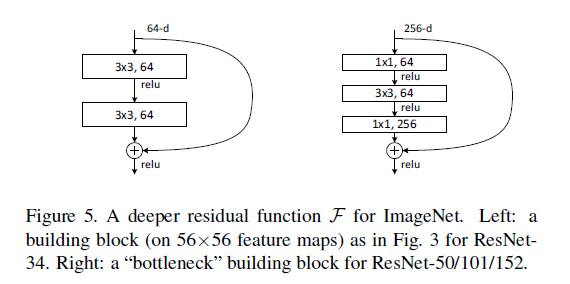
Deeper Bottleneck Architectures
接下來描述的針對ImageNet的深度網路。考慮到我們所能承擔的訓練時間,我們修改building block為bottleneck。對於每個殘差函式F,我們使用一個3層的棧式結構代替2層的結構(圖5)。這三層分別是1×1、3×3和1×1的卷積,1×1的卷積的目的是使維度先減小再增加(復原),讓3×3的卷積層作為一個低維輸入輸出的bottleneck。圖5展示了一個示例,兩種設計有相同的時間複雜度。
恆等的shortcut對bottleneck結構非常重要。如果圖5右的恆等shortcut被投影shortcut代替,時間複雜度和模型大小都被加倍,因為shortcut用於連線兩個高維的端。因此,恆等shortcuts使bottleneck的設計更有效。(注意,bottleneck也有退化現象,所以bottleneck的設計要儘量簡潔)
50層ResNet:我們用這種3層的bottleneck代替34層ResNet中的每個兩層block,構成50層ResNet(表1)。我們使用選項B來增加維度。這個模型有38億FLOPs。
101層和152層ResNet:我們通過使用更多的3層block構建101層和152層ResNet(表1)。儘管深度有了顯著的增加,152層ResNet(113億FLOPs)仍然比VGG-16/19(153億/196億FLOPs)複雜度更低。
50/101/152層的比34層更精確(表3和4),我們沒有觀察到退化問題,並因此從相當高的深度上獲得了顯著的精度增益。在所有評估指標上都可以看到深度的好處(表3和4)。
與優秀演算法的比較
表4中,我們比較累之前最好的單模型結果。我們的基本34層ResNet已經達到具有競爭力的準確度。我們的152層的ResNet有一個單模型top-5驗證驗證誤差為4.49%。這個單模型結果比以前所有的集合結果都要出色(表5)。我們結合六種不同深度的模型形成一個集合(在提交時只用了2個152層ResNet)。在測試集上取得了3.57%的top-5錯誤率。這項贏得了ILSVRC2015的第一名。
4.2CIFAR-10和分析
我們在CIFAR-10上做了更多研究,它由包括10個類別的5萬個訓練圖和1萬個測試圖組成。我們展示在需年紀的訓練和在測試集上的測試實驗。我們主要研究極其深的網路的表現,而不是找出一個優異的實驗結果,因此我們有意使用如下簡單的結構。
普通網路/殘差網路結構如圖3(中/右)所示。網路輸入為32×32的圖片,每個畫素都減去平均值。第一層為一個3×3的卷積層。然後我們使用將6n層3×3的卷積層堆疊在一起,特徵圖大小分別為{32,16,8},每個特徵圖大小對應2n個層。Filter的個數分別為{16,32,64}。下采樣操作通過步長為2的卷積操作執行。網路以一個全域性平均池化層和softmax層結合。一共有6n+2個權重層。下表總結了結構。
當shortcut被使用時,它們被連線到成對的3×3層(3n個shortcut)。在這個資料集上,我們全部使用恆等shortcuts(即選項A),因此,我們的殘差模型和相應的普通網路具有相同的深度、寬度和引數的個數。
我們使用0.0001的權重衰減和0.9的動量,並常用[13]的權重初始化和BN,但是沒有dropout層。這個模型用批量大小為128,在2個GPU上訓練。我們開始時設定學習率為1.1,在32k和48k次迭代時將學習率除以10,並在64k次迭代時結束訓練,這由45k/5k train/val劃分決定。我們根據[24]的簡單資料擴增進行訓練:每一側都填充4個畫素,並且從填充影象或水平翻轉中隨機抽取32×32的corp。為了測試,我們只評估原始32×32影象的單一視角。
我們比較n={3,5,7,9},即20,32,44,56層網路。圖6左展示了普通網路的表現。深度普通網路受到了深度的影響,並且在深的時候表現出了更高的訓練錯誤。這個現象與ImageNet和MNIST相同,說明這樣的優化困難是一個基本問題。
圖6(中間)展示了ResNets的表現。也和ImageNet相同,我們的ResNets成功的克服了優化困難並展示出在深度的時候獲得的準確度。
我們更進一步探索了n=18時,110層的ResNet。在這個試驗中,我們發現0.1的初始學習率有一些太大以至於提早開始收斂。因此我們使用0.01的學習路開始訓練指導訓練誤差地域80%(大約400次迭代),然後變回0.1的學習率繼續訓練。其他的學習任務和前面的實驗一樣。110層的網路能夠很好的收斂(圖6中間)。它具有比其他又深又窄的網路如FitNet和HighWay更少的引數(表6),已經是最優異的結果了(6.43%,表6)。
層響應分析
圖7展示了層響應的方差。這個響應是BN之後,其他非線性操作(ReLU/addition)之前的輸出。對於ResNets,這個分析揭示了殘差函式的響應力度。圖7展示了ResNet一般比相應的普通網路具有更小的響應。這個結果支援了我們的基本動機(3.1節),即殘差函式比非殘差函式更易接近於0。我們也注意到,更深的ResNet比20,56,110層的ResNet有更小量級的響應,如圖7。當有更多的層時,一個單獨的ResNet層往往會更少地修改訊號。
探索1000+層
我們探索了一個超過1000層的深度模型。我們設定n=200,使其產生一個1202層的網路,同如上所述的進行訓練。我們的方法沒有顯示優化困難,這個1000層網路能夠實現訓練誤差小於0.1%(圖6,右)。它的測試錯誤也相當好(7.93%,表6)。
但在這種過分深層的模型上,仍存在一些問題。這個1202層網路的測試結果比我們的110層網路要差,儘管兩者都有相似的訓練誤差。我們認為這是因為過度擬合。對於小資料集來說,1202層的網路也許沒有必要。如Maxout和Dropout等強大的正則化方法在這個資料集上已經取得了很好的結果。在這篇論文中,我們沒有使用maxout/dropout並且只簡單的通過深度和設計薄的結構來實現規範化,而不會分散對優化問題的注意力。但是,結合更強的規範化可能會改善結果,我們將在未來研究。
4.3在PASCAL和MS COCO上的目標檢測
我們的方法已經在其他識別任務上取得了一般化的表現。表7和表8展示在PASCAL VOC 2007和2012以及COCO上的基本結果。我們採取Faster R-CNN作為檢測方法。我們對用resnet-101替換VGG-16的改進感興趣。使用這兩種模型檢測的實現(見附錄)是相同的,因此所得的結果只能歸因於更好的網路。值得注意的是,在COCO資料集的挑戰上,我們在COCO標準度量上獲得了6%的增加([email protected][.5,.95])相對改進了28%。這個進步僅僅是因為特徵的學習。
基於深度殘差網路,我們在ILSVRC&COCO2015年的比賽中獲得了第1名:ImageNet檢測、ImageNet定位、COCO檢測和COCO分割。細節在附錄中。
三、ResNet——MSRA何凱明團隊的Residual Networks,在2015年ImageNet上大放異彩,在ImageNet的classification、detection、localization以及COCO的detection和segmentation上均斬獲了第一名的成績,而且Deep Residual Learning for Image Recognition也獲得了CVPR2016的best paper,實在是實至名歸。就讓我們來觀摩大神的這篇上乘之作。
ResNet最根本的動機就是所謂的“退化”問題,即當模型的層次加深時,錯誤率卻提高了,如下圖:
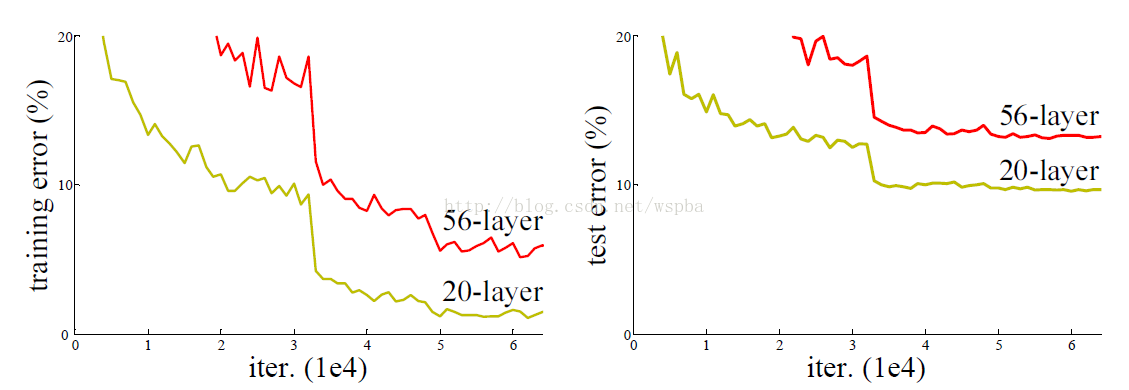
但是模型的深度加深,學習能力增強,因此更深的模型不應當產生比它更淺的模型更高的錯誤率。而這個“退化”問題產生的原因歸結於優化難題,當模型變複雜時,SGD的優化變得更加困難,導致了模型達不到好的學習效果。
針對這個問題,作者提出了一個Residual的結構:
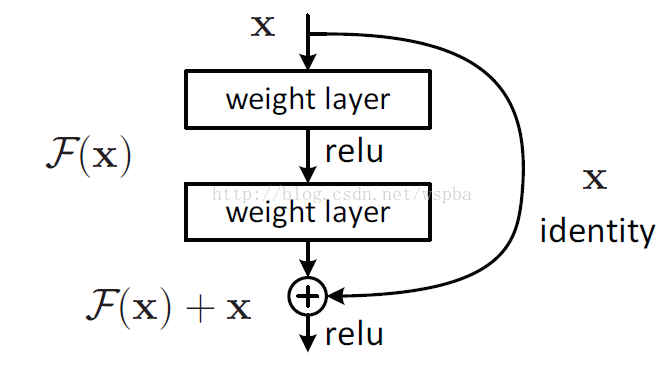
即增加一個identity mapping(恆等對映),將原始所需要學的函式H(x)轉換成F(x)+x,而作者認為這兩種表達的效果相同,但是優化的難度卻並不相同,作者假設F(x)的優化 會比H(x)簡單的多。這一想法也是源於影象處理中的殘差向量編碼,通過一個reformulation,將一個問題分解成多個尺度直接的殘差問題,能夠很好的起到優化訓練的效果。
這個Residual block通過shortcut connection實現,通過shortcut將這個block的輸入和輸出進行一個element-wise的加疊,這個簡單的加法並不會給網路增加額外的引數和計算量,同時卻可以大大增加模型的訓練速度、提高訓練效果,並且當模型的層數加深時,這個簡單的結構能夠很好的解決退化問題。
接下來,作者就設計實驗來證明自己的觀點。
首先構建了一個18層和一個34層的plain網路,即將所有層進行簡單的鋪疊,然後構建了一個18層和一個34層的residual網路,僅僅是在plain上插入了shortcut,而且這兩個網路的引數量、計算量相同,並且和之前有很好效果的VGG-19相比,計算量要小很多。(36億FLOPs VS 196億FLOPs,FLOPs即每秒浮點運算次數。)這也是作者反覆強調的地方,也是這個模型最大的優勢所在。
模型構建好後進行實驗,在plain上觀測到明顯的退化現象,而且ResNet上不僅沒有退化,34層網路的效果反而比18層的更好,而且不僅如此,ResNet的收斂速度比plain的要快得多。
對於shortcut的方式,作者提出了三個選項:
A. 使用恆等對映,如果residual block的輸入輸出維度不一致,對增加的維度用0來填充;
B. 在block輸入輸出維度一致時使用恆等對映,不一致時使用線性投影以保證維度一致;
C. 對於所有的block均使用線性投影。
對這三個選項都進行了實驗,發現雖然C的效果好於B的效果好於A的效果,但是差距很小,因此線性投影並不是必需的,而使用0填充時,可以保證模型的複雜度最低,這對於更深的網路是更加有利的。
進一步實驗,作者又提出了deeper的residual block:
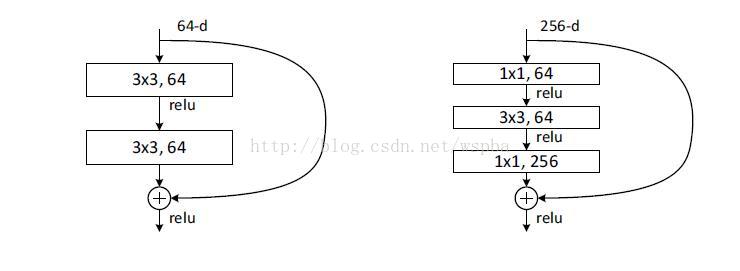
這相當於對於相同數量的層又減少了引數量,因此可以拓展成更深的模型。於是作者提出了50、101、152層的ResNet,而且不僅沒有出現退化問題,錯誤率也大大降低,同時計算複雜度也保持在很低的程度。
這個時候ResNet的錯誤率已經把其他網路落下幾條街了,但是似乎還並不滿足,於是又搭建了更加變態的1202層的網路,對於這麼深的網路,優化依然並不困難,但是出現了過擬合的問題,這是很正常的,作者也說了以後會對這個1202層的模型進行進一步的改進。(想想就可怕。)
在文章的附錄部分,作者又針對ResNet在其他幾個任務的應用進行了解釋,畢竟獲得了第一名的成績,也證明了ResNet強大的泛化能力,感興趣的同學可以好好研究這篇論文,是非常有學習價值的。
四、
《Deep Residual Learning for Image Recognition》是2016年CVPR的最佳論文,也是我Kaiming男神第二次獲得CVPR的最佳論文,簡直強的一批啊!
摘要
resNet主要解決一個問題,就是更深的神經網路如何收斂的問題,為了解決這個問題,論文提出了一個殘差學習的框架。然後簡單跟VGG比較了一下,152層的殘差網路,比VGG深了8倍,但是比VGG複雜度更低,當然在ImageNet上的表現肯定比VGG更好,是2015年ILSVRC分類任務的冠軍。
另外用resNet作為預訓練模型的檢測和分割效果也要更好,這個比較好理解,分類效果提升必然帶來檢測和分割的準確性提升。
介紹
在resNet之前,隨著網路層數的增加,收斂越來越難,大家通常把其原因歸結為梯度消失或者梯度爆炸,這是不對的。另外當訓練網路的時候,也會有這樣一個問題,當網路層數加深的時候,準確率可能會快速的下降,這當然也不是由過擬合導致的。我們可以這樣理解,構造一個深度模型,我們把新加的層叫做identity mapping(這個mapping實在不知道怎麼翻譯好,尷尬……),而其他層從學好的淺層模型複製過來。現在我們需要保證這個構造的深度模型並不會比之前的淺層模型產生更高的訓練錯誤,然而目前並沒有好的比較方法。
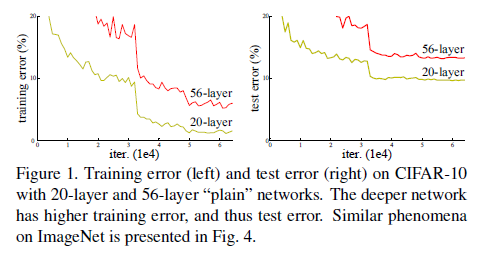
從圖上可以看到,層數越多,收斂越慢,且error更高。
在論文中,kaiming大佬提出了一個深度殘差學習框架來解決網路加深之後準確率下降的問題。用公式來表示,假如我們需要的理想的mapping定義為,那麼我們新加的非線性層就是,原始的mapping就從變成了。也就是說,如果我們之前的是最優的,那麼新加的identity mapping 就應該都是0,而不會是其他的值。
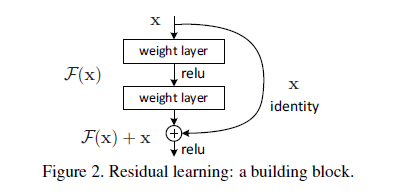
這樣整個殘差網路是端對端(end-to-end)的,可以通過隨機梯度下降反向傳播,而且實現起來很簡單(實際上就是兩層求和,在Caffe中用Eltwise層實現)。至於它為什麼收斂更快,error更低,我是這麼理解的:
我們知道隨機梯度下降就是用的鏈式求導法則,我們對求導,相當於對求導,那麼這個梯度值就會在1附近(x的導數是1),相比之前的plain網路,自然收斂更快。
深度殘差學習
假設多個線性和非線性的組合層可以近似任意複雜函式(這是一個開放性的問題),那麼當然也可以逼近殘差函式(假設輸入和輸出的維度相同)。
論文中殘差模組定義為:
其中,代表輸入,代表輸出,代表需要學習的殘差mapping。像上圖firgure 2有兩層網路,用表示,這裡表示ReLU啟用層。這裡是卷積操作,是線性的,ReLU是非線性的。
其中和的維度一定要相同,如果不同的話,可以通過一個線性對映來匹配維度:
這裡是比較靈活的,可以包含兩層或者三層,甚至更多層。但是如果只有一層的話,就變成了,這就是普通的線性函數了,就沒有意義了。
接下來就是按照這個思路將網路結構加深了,下面列出幾種結構:
最後是一個更深的瓶頸結構問題,論文中用三個1x1,3x3,1x1的卷積層代替前面說的兩個3x3卷積層,第一個1x1用來降低維度,第三個1x1用來增加維度,這樣可以保證中間的3x3卷積層擁有比較小的輸入輸出維度。
好了,resNet讀到這裡基本上差不多了,當然啦,後來又出了resNet的加寬版resNeXt,借鑑了GoogLeNet的思想,以後有機會再細讀!
五、到底Resnet在解決一個什麼問題呢?
既然可以通過初試化和歸一化(BN層)解決梯度彌散或爆炸的問題,那Resnet提出的那條通路是在解決什麼問題呢? 在He的原文中有提到是解決深層網路的一種退化問題,但並明確說明是什麼問題! 解釋1:理論上深層的神經網路一定比淺層的要好,比如深層網路A,淺層網路B,A的前幾層完全複製B,A的後幾層都不再改變B的輸出,那麼效果應該是和B是一樣的。也就是說,A的前幾層就是B,後幾層是線性層。但是實驗發現,超過一定界限之後,深層網路的效果比淺層的還差。一個可能的解釋是:理論上,我們可以讓A的後幾層輸入等於輸出,但實際訓練網路時,這個線性關係很難學到。既然如此,我們把這個線性關係直接加到網路的結構當中去,那麼效果至少不必淺層網路差。也就是說,Resnet讓深層神經網路更容易被訓練了。
實際操作中,加上這個residual,我們一方面可以做的更深,這樣網路表達的能力更好了,一方面訓練的也更快了,至少比VGG快多了。
解釋2:大意是神經網路越來越深的時候,反傳回來的梯度之間的相關性會越來越差,最後接近白噪聲。因為我們知道影象是具備區域性相關性的,那其實可以認為梯度也應該具備類似的相關性,這樣更新的梯度才有意義,如果梯度接近白噪聲,那梯度更新可能根本就是在做隨機擾動。
有了梯度相關性這個指標之後,作者分析了一系列的結構和啟用函式,發現resnet在保持梯度相關性方面很優秀(相關性衰減從
到了
)。這一點其實也很好理解,從梯度流來看,有一路梯度是保持原樣不動地往回傳,這部分的相關性是非常強的。