Residual Network Research
DenseNet: Densely Connected Residual Network
解決的問題:
- 隨著網路層數加深梯度消失的問題:
As information about the input or gradient passes through many layers, it can vanish and “wash out” by the time it reaches the end (or beginning) of the network.
- 原來ResNet中有很多層的貢獻很少,在訓練的時候可以隨機去掉:
Recent variations of ResNets show that many layers contribute very little and can in fact be randomly dropped during training.
新的結構:
一個L層傳統的卷積神經網路只有L個連線——每一層和它的下一層之間有一個連線。而這篇文章提出的Dense Convolutional Network (DenseNet) 有個連線。對每一層來說前面所有層的feature map都是它的輸入,而它的輸出的feature map又是後面所有層的輸入。
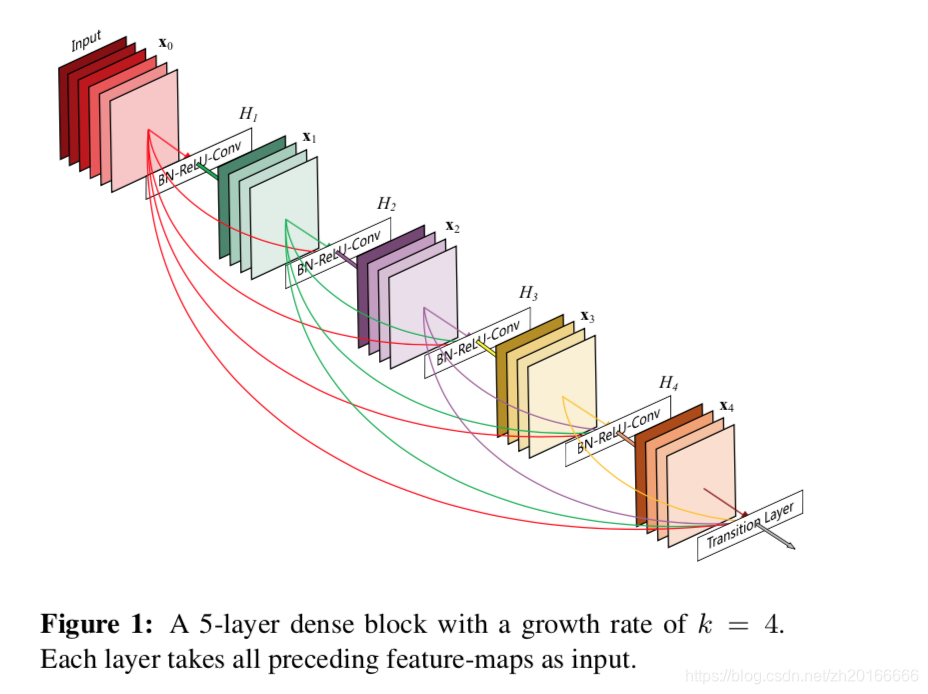 為什麼有很好的效果? 文章中是這樣解釋的:
為什麼有很好的效果? 文章中是這樣解釋的:
Each layer has direct access to the gradients from the loss function and the original input signal, leading to an implicit deep supervision.
這句話大概就是在說每一層都能獲得來次損失函式的梯度資訊以及輸入的原始資訊,可以看成是一個隱式的監督的網路。 優點:
- 減輕了梯度消失 (alleviate the vanishing-gradient problem)
- 增強了特徵的傳遞 (strength feature propagation)
- 更有效的利用了特徵資訊 (encourage feature reuse)
- 一定程度上減少了引數數量 (substantially reduce number of parameters)
DenseNet
一個L層的神經網路,每一層都可以看做是一個非線性的對映,可以是一系列函式的組合例如BN、ReLU、Pooling、Convolution,用表示層的輸出,則可以用下面三個式子分別表示傳統的卷積神經網路,原始的ResNet和DenseNet: 傳統的卷積神經網路: ResNet: DenseNet: 表示層的拼接。從上面的式子還可以看出ResNet和DenseNet的一個區別:ResNet是將不同層的輸出加和作為下一層的輸入,而DenseNet是拼接。至於為什麼,文章中是這麼說的:
However, the identity function and output of are combined by summation, which may impede the information flow in the network.
大意是說加和會影響資訊在神經網路的傳遞(???)。
Composite function
對於上面的複合函式,在這篇文章中是這樣定義的:是三個連續操作的符合,這三個操作依次是BN、ReLU、3x3 convolution。
Pooling layers
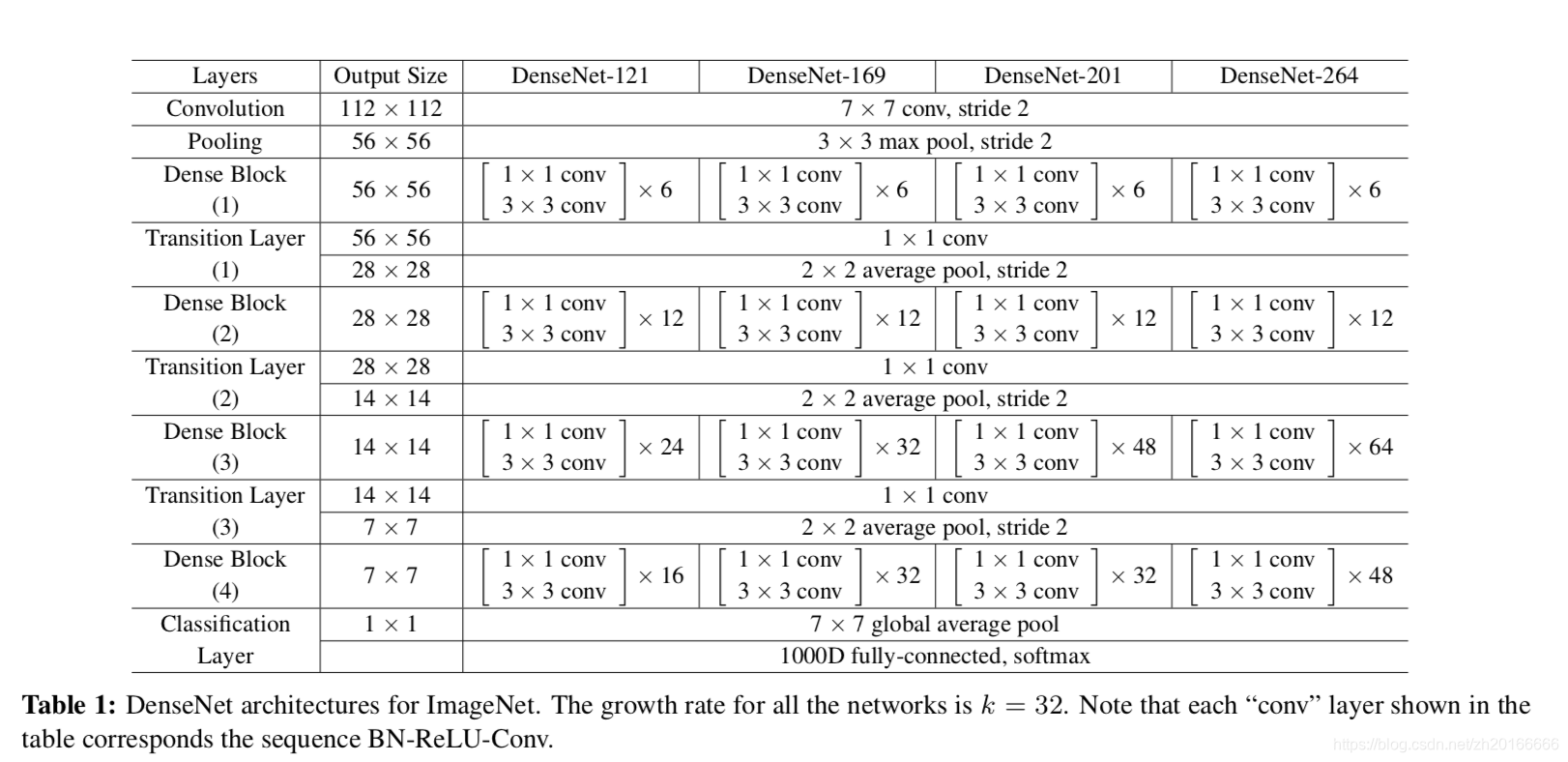
神經網路最重要的一點就是進行下采樣來改變feature-map的大小,在DenseNet並不會改變feature-map的大小。所以,為了實現下采樣作者將這個網路分成多個不同的密集連線的dense block,在dense block之間添加了一個transition layer來做卷積和池化。這篇文章中作者使用的是1x1的卷積層接一個2x2的平均池化。
 Growth rate
如果每個 產生 個feature-maps,那麼第 層就會有 個feature-maps作為輸入。很重要的一點是,與一般的神將網路結構相比,DenseNet的每一層可以很窄,例如讓 。 文章將超引數 稱為 growth rate
Bottleneck layers
儘管每層只輸出 個feature-maps,後面的層還是會有很多的輸入,有文章說到 可以被用作 來減少輸入的feature-maps的數量。所以作者設計了一種新的:,將其稱為DenseNet-B。
Compression
為了進一步壓縮feature-map的數量,作者還用transition layer來減少輸入進dense block的feature-map的數量。作者設計了一個超引數 來控制壓縮的力度:如果一個dense block輸出了m個feature-maps,則可以通過它後面的transition layer把feature-map的數目減少到 。當同時使用了bottleneck 和 的transition layer 時,作者將這樣的模型稱為 DenseNet-BC.
Growth rate
如果每個 產生 個feature-maps,那麼第 層就會有 個feature-maps作為輸入。很重要的一點是,與一般的神將網路結構相比,DenseNet的每一層可以很窄,例如讓 。 文章將超引數 稱為 growth rate
Bottleneck layers
儘管每層只輸出 個feature-maps,後面的層還是會有很多的輸入,有文章說到 可以被用作 來減少輸入的feature-maps的數量。所以作者設計了一種新的:,將其稱為DenseNet-B。
Compression
為了進一步壓縮feature-map的數量,作者還用transition layer來減少輸入進dense block的feature-map的數量。作者設計了一個超引數 來控制壓縮的力度:如果一個dense block輸出了m個feature-maps,則可以通過它後面的transition layer把feature-map的數目減少到 。當同時使用了bottleneck 和 的transition layer 時,作者將這樣的模型稱為 DenseNet-BC.
Experiments
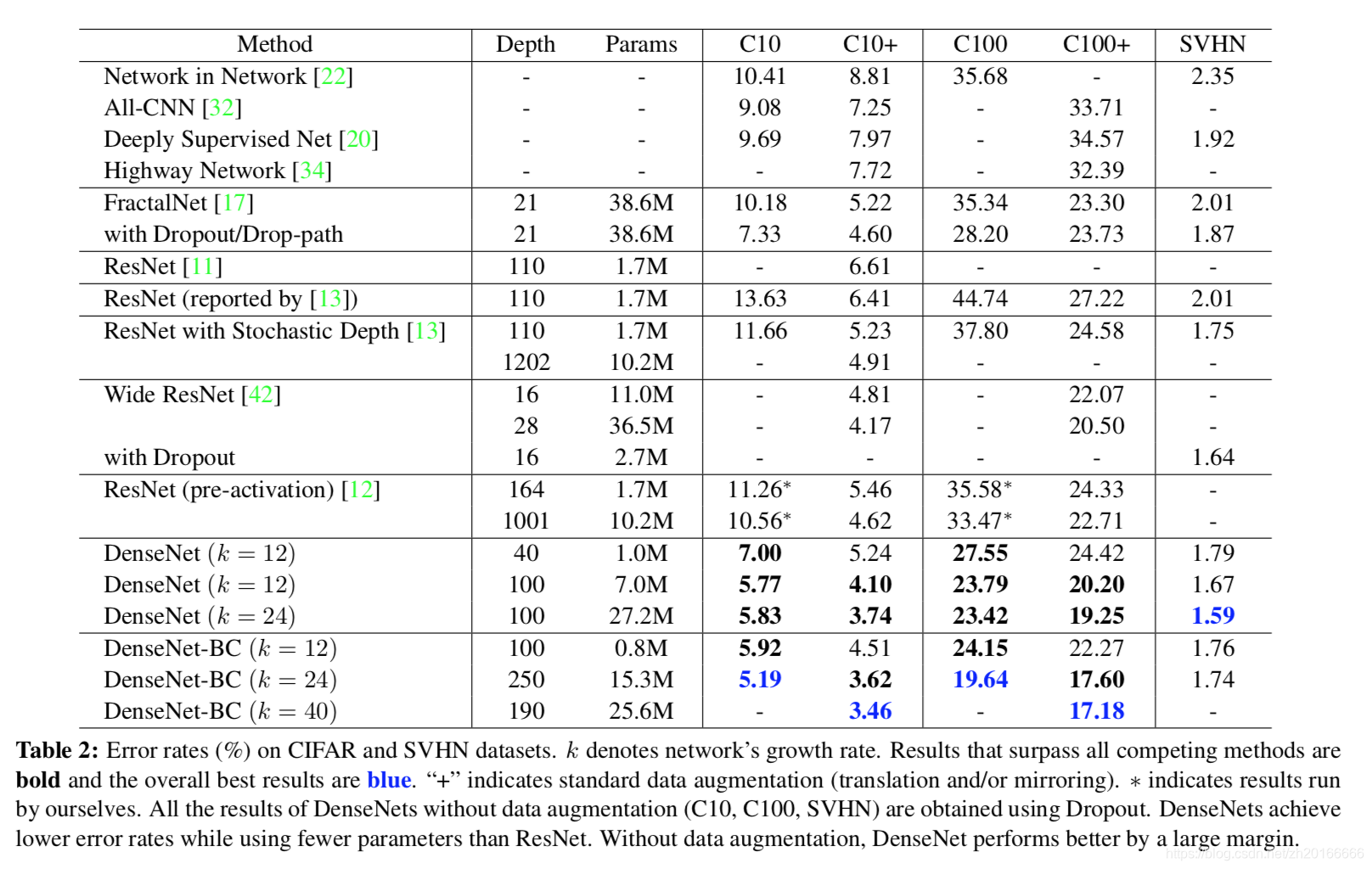
下表是在三個資料集(C10,C100,SVHN)上和其他演算法的對比結果。ResNet[11]就是kaiming He的論文。DenseNet-BC的網路引數和相同深度的DenseNet相比確實減少了很多,引數減少除了可以節省記憶體,還能減少過擬合。這裡對於SVHN資料集,層數更多的DenseNet-BC的結果並沒有層數少的DenseNet (k = 24) 的效果好,作者認為原因主要是SVHN這個資料集相對簡單,更深的模型容易過擬合。在表格的倒數第二個區域的三個不同深度L和k的DenseNet的對比可以看出隨著L和k的增加,模型的效果是更好的。
下圖是DenseNet-BC和ResNet在Imagenet資料集上的對比,左邊那個圖是引數複雜度和錯誤率的對比,右邊是flops和錯誤率的對比。
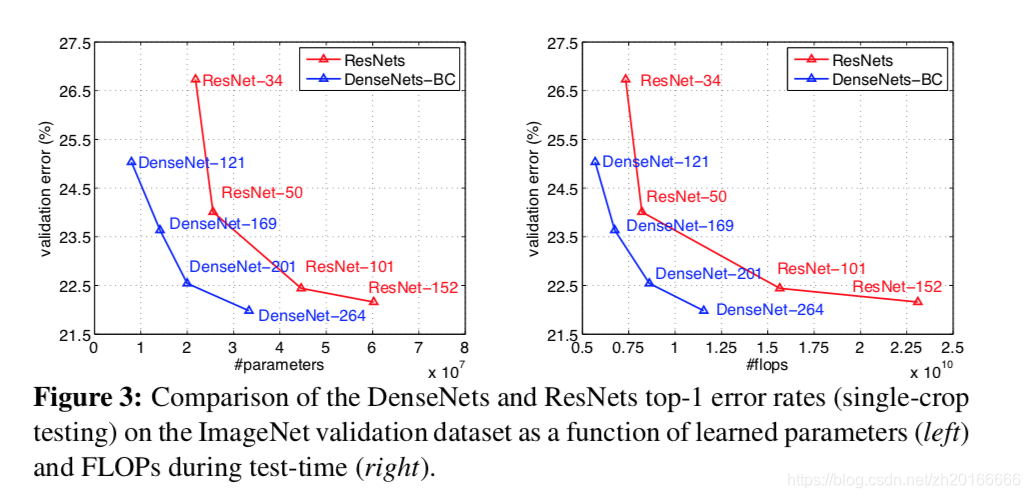
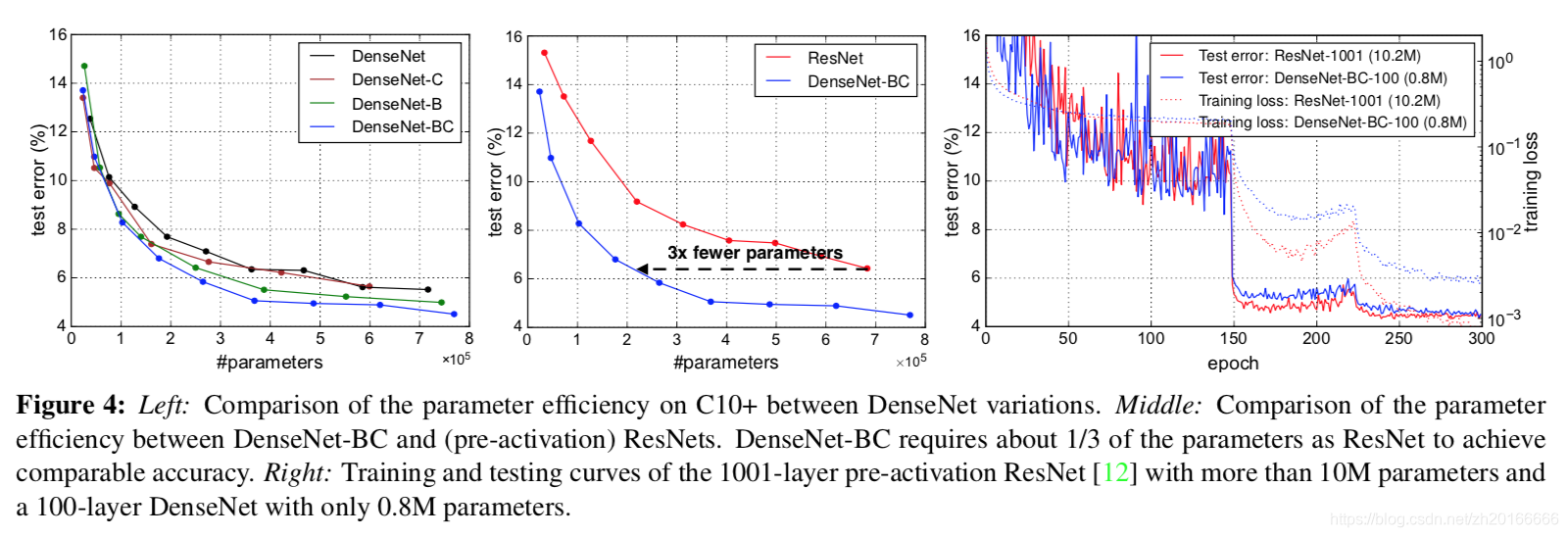
下圖中,左邊的圖表示不同型別DenseNet的引數數量和錯誤率的對比。中間的圖表示DenseNet-BC和ResNet在引數數量和錯誤率的對比,相同錯誤率下,DenseNet-BC的引數複雜度要小很多。右邊的圖也是表達DenseNet-BC-100只需要很少的引數就能達到和ResNet-1001相同的結果。