
Residual Network Research: Wide Residual Networks
WRNs:Wide Residual Networks
Abstract
深度殘差網路能夠讓我們將神經網路的層數增加到幾千層仍然能夠獲得性能的提升。但是,準確率每提升一個百分點網路的層數幾乎要增加一倍,因此訓練非常深的殘差網路存在降低特徵重用的問題,這使得這些網路訓練的很慢。為了解決這個問題,作者在這篇文章中做了很多對比實驗來研究ResNet block的結構,然後提出了一種新的結構,在這種結構下作者減少了網路的深度但是增加了網路的寬度。作者將這種結構稱為wide residual networks (WRNs),而且作者展示了這種結構要比通常的窄的但是深度很深的結構要好很多。
1 Introduction
Width vs depth in residual networks 作者提出了層數很深的ResNet的一個問題:
As gradient flows through the network there is nothing to force it to go through residual block weights and it can avoid learning anything during training, so it is possible that there is either only a few blocks that learn useful representations, or many blocks share very little information with small contribution to the final goal. This problem was formulated as diminishing feature reuse in [28]
意思是說隨著梯度在網路中的傳遞,並沒有措施來強制其通過Residual block weights,這樣就可能導致在訓練時學不到或者學到的很少,因此很有可能在網路中只有少數的幾個block能夠學習到有用的表示,其他很多blocks只是共享了很少的資訊,對最終的結構貢獻很少,這個問題被稱為diminishing feature reuse。
基於上述的問題,作者就在這片文章中研究了怎麼來設計wide residual networks以及來解決一些訓練中的問題。
Use of dropout in ResNet blocks 之前有文章表明將 dropout 新增到 residual networks 中的 identity part 會有副作用。但是作者確認為應該新增到卷積層之間,實驗表明這樣會取得更好的效果。
2 Wide residual networks
在 Identity mappings in deep residual networks 這篇文章中提出了兩種 residual blocks:
- basic (Figure 1.a)
- bottleneck (Figure 1.b)
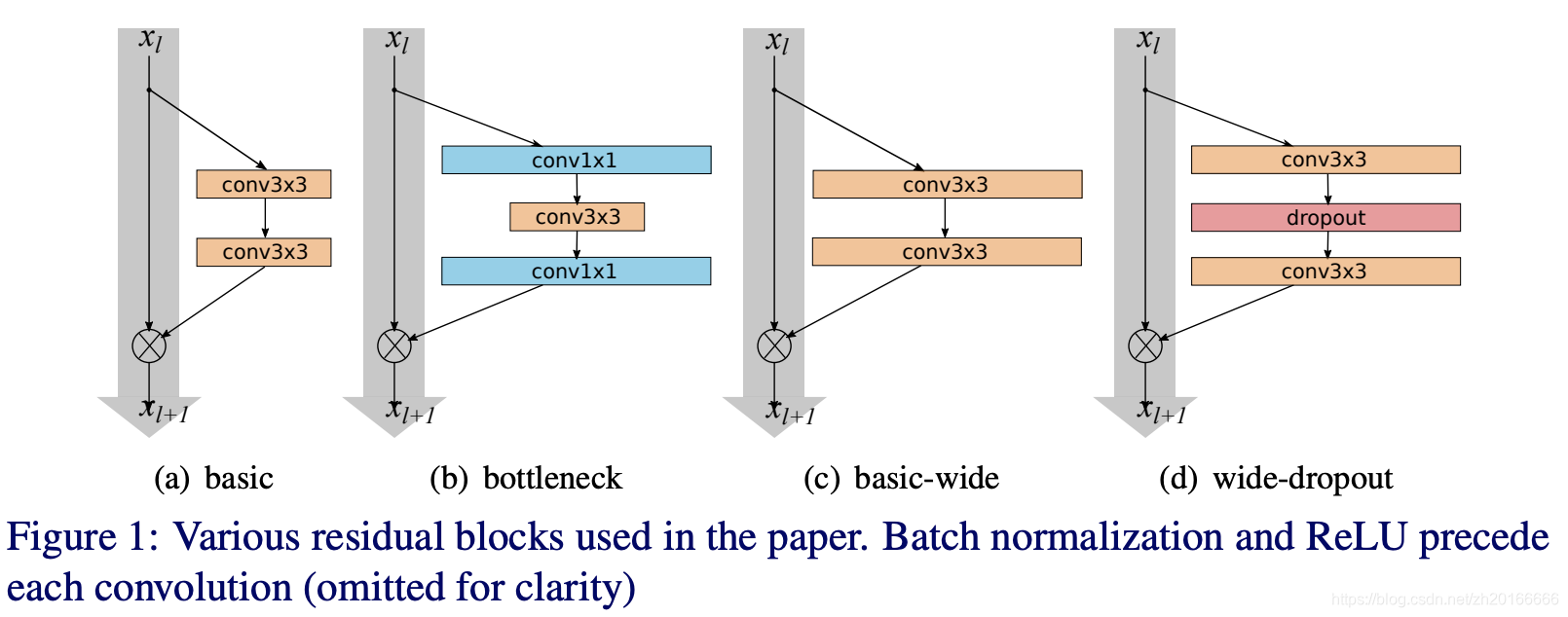 由於bottleneck block是為了減少計算量,這篇文章是為了研究深度的影響,所以不考慮bottleneck形式的block。
由於bottleneck block是為了減少計算量,這篇文章是為了研究深度的影響,所以不考慮bottleneck形式的block。
在 Deep residual learning for image recognition 和 Identity mappings in deep residual networks 這兩篇文章提出了不同結構(BN、ReLU、Conv的順序不同)的 residual block。從 conv-BN-ReLU 到 BN-ReLU-conv,由於後面這種訓練更快,效果更好,所以在實驗中不考慮前面那種結構了。
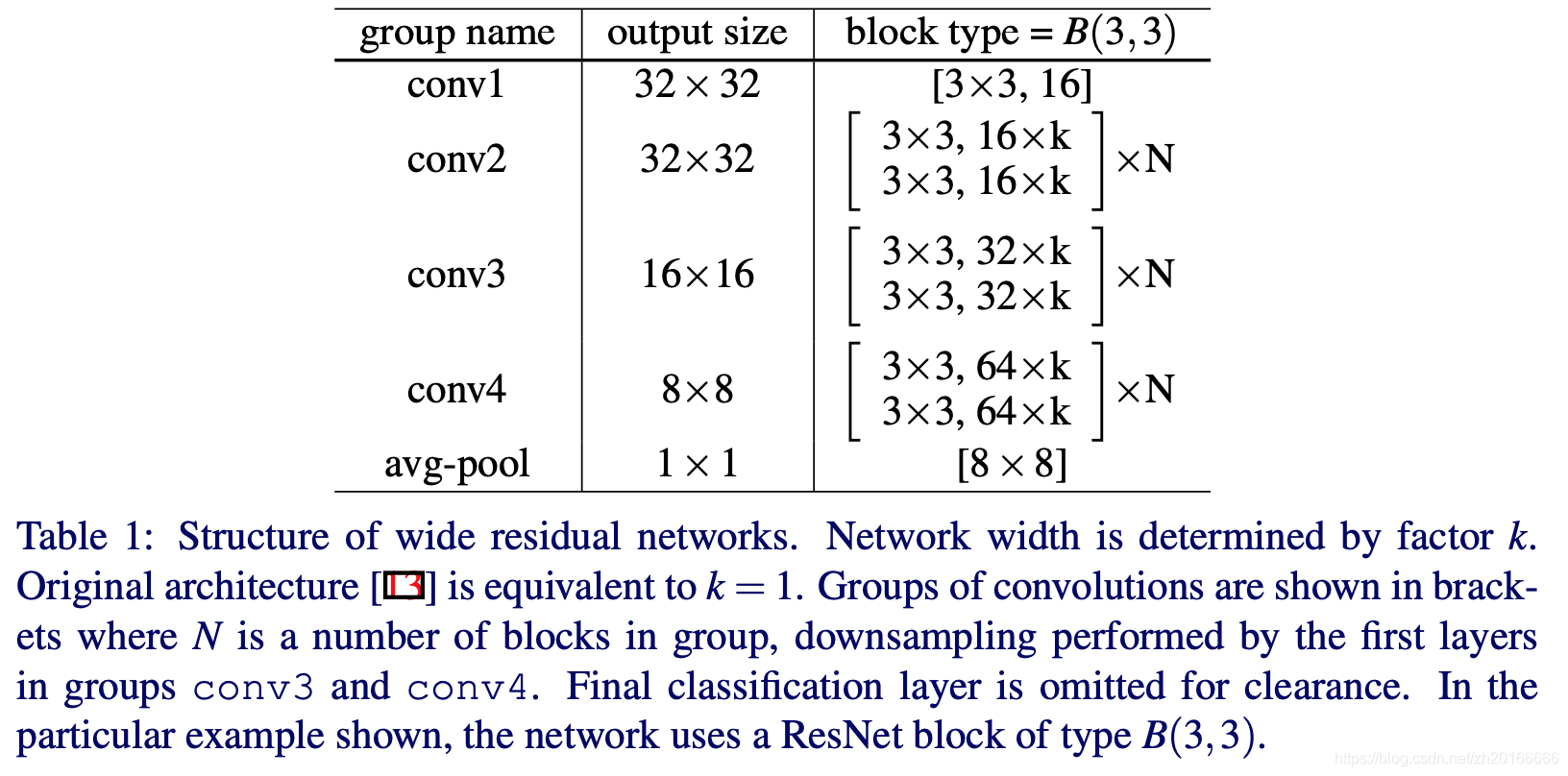 wide residual networks 的結構如上圖,原始的ResNet中k=1.
wide residual networks 的結構如上圖,原始的ResNet中k=1.
有三種簡單的方式來增強ResNet的效能:
- 在每個block中新增更多的卷積層
- 通過新增feature maps的數量來增加網路的寬度
- 使用更大的filter
由於有文章表明較小的卷積核在一些任務上有更好的想過,所以實驗不會使用比 3x3 更大的卷積核了。
2.1 Type of convolutions in residual block
用表示residual block 的結構,其中 表示卷積核大小的一個list,例如 表示擁有一個3x3卷積和1x1卷積的 residual block。作者設計了一下幾種結構的 residual block:
 2.2 Number of convolution layers per residual block
作者也通過實驗驗證了residual block中卷積層的數目的影響(保證引數數目差不多的條件下)。
2.3 Width of residual block
residual block寬度對效果的影響,即上面那個結構圖中的k>1時。當k>1時稱為 wide residual networks (WRNs). 文章中用 WRN-n-k 來表示卷積層數為n,widen factor 為 k 的 WRNs。
2.4 Dropout in residual blocks
作者也驗證了加入 dropout 後的影響,結構見 Figure 1.d.
2.2 Number of convolution layers per residual block
作者也通過實驗驗證了residual block中卷積層的數目的影響(保證引數數目差不多的條件下)。
2.3 Width of residual block
residual block寬度對效果的影響,即上面那個結構圖中的k>1時。當k>1時稱為 wide residual networks (WRNs). 文章中用 WRN-n-k 來表示卷積層數為n,widen factor 為 k 的 WRNs。
2.4 Dropout in residual blocks
作者也驗證了加入 dropout 後的影響,結構見 Figure 1.d.
Experimental results
Type of convolution in a block
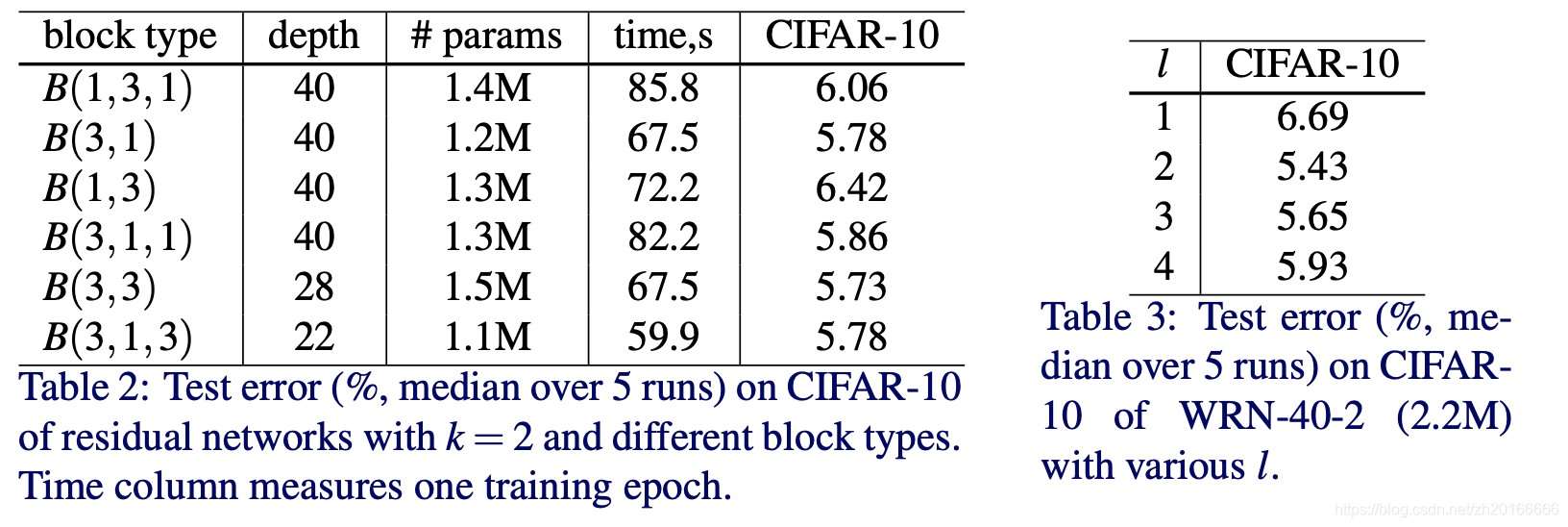 從 Table 2 可以看出B(3,3)效果最好,而 B(3,1) 和 B(3,1,3) 的效果與 B(3,3) 很接近。
從 Table 2 可以看出B(3,3)效果最好,而 B(3,1) 和 B(3,1,3) 的效果與 B(3,3) 很接近。
Number of convolution layers per residual block Table 3 展示了residual block 中卷積層數目的影響。可以看出兩層卷積時效果最好,因此在後面的實驗中作者都採用了B(3,3)形式的 residual block。
Width of residual blocks
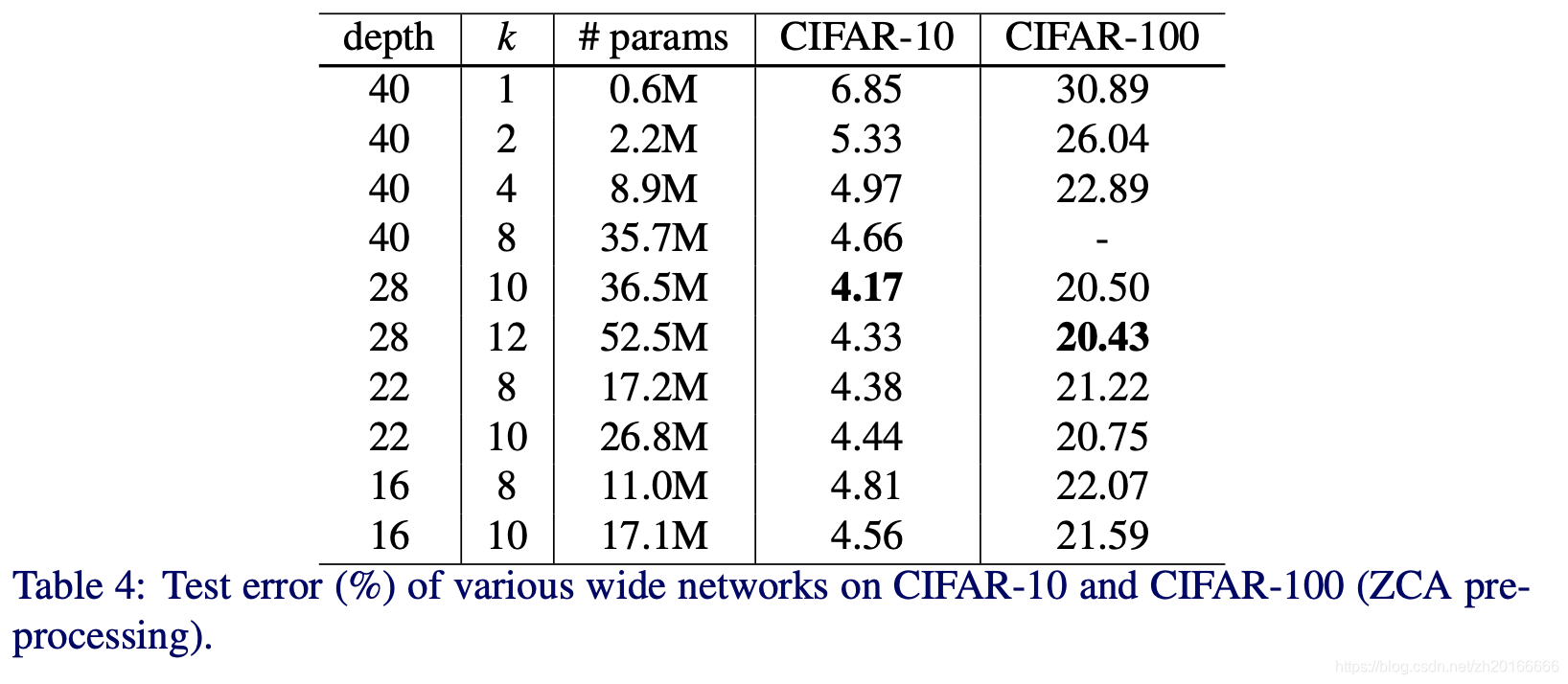 在增加k的同時要減少網路的深度,作者為了找到最合適的比例將k從2增到12,深度從16到40,結果見下表。由Table 4可以看出深度為40、22、16的網路隨著k的增大效果也在變好。另一方面,如果固定k=8或k=10,深度從16到28,效果也在變好,但是當繼續增加到40層的時候效果卻下降了(WRN-40-8的準確率比WRN-22-8要低)。
在增加k的同時要減少網路的深度,作者為了找到最合適的比例將k從2增到12,深度從16到40,結果見下表。由Table 4可以看出深度為40、22、16的網路隨著k的增大效果也在變好。另一方面,如果固定k=8或k=10,深度從16到28,效果也在變好,但是當繼續增加到40層的時候效果卻下降了(WRN-40-8的準確率比WRN-22-8要低)。
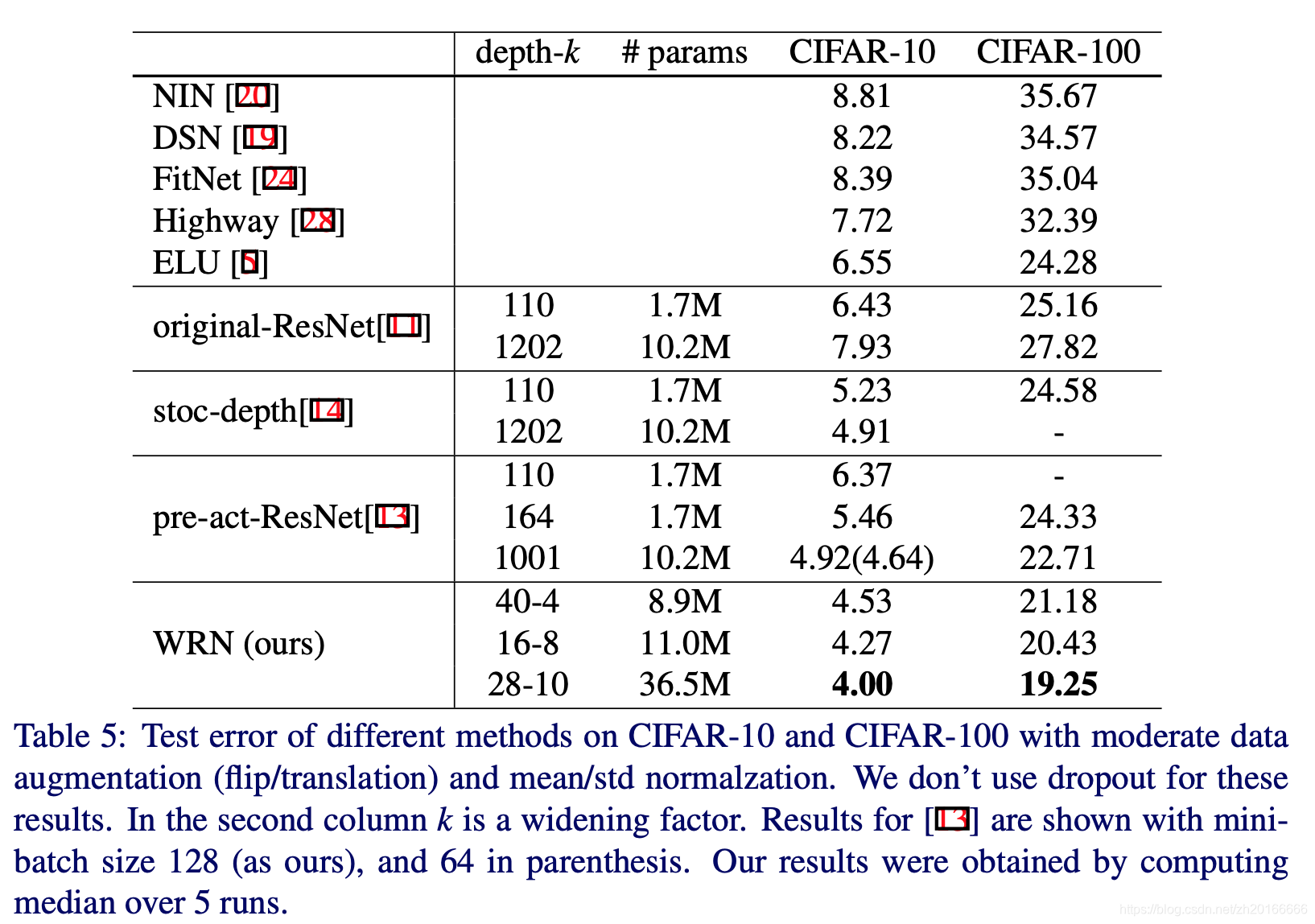 作者在Table 5中展示了窄的網路和寬網路的對比。從表中我們可以看出寬的WRN-40-4要比窄的ResNet-1001要好,因為在CIFAR-10和CIFAR-100兩個資料集上WRN-40-4的準確率都更高,而且它們有著相似的引數數量,表明與這種寬度相比深度並沒有增加正則化的效應。作者在基準測試中進一步顯示,WRN-40-8的訓練速度比ResNet-1001快八倍,所以作者認為原來residual network的深度和寬度的比例遠不是最優的。
作者在Table 5中展示了窄的網路和寬網路的對比。從表中我們可以看出寬的WRN-40-4要比窄的ResNet-1001要好,因為在CIFAR-10和CIFAR-100兩個資料集上WRN-40-4的準確率都更高,而且它們有著相似的引數數量,表明與這種寬度相比深度並沒有增加正則化的效應。作者在基準測試中進一步顯示,WRN-40-8的訓練速度比ResNet-1001快八倍,所以作者認為原來residual network的深度和寬度的比例遠不是最優的。
儘管之前有爭論說深度能過提供正則化的效果而寬度則會導致過擬合,但是作者卻成功訓練了引數數量是ResNet-1001幾倍的網路,而且效果要更好。
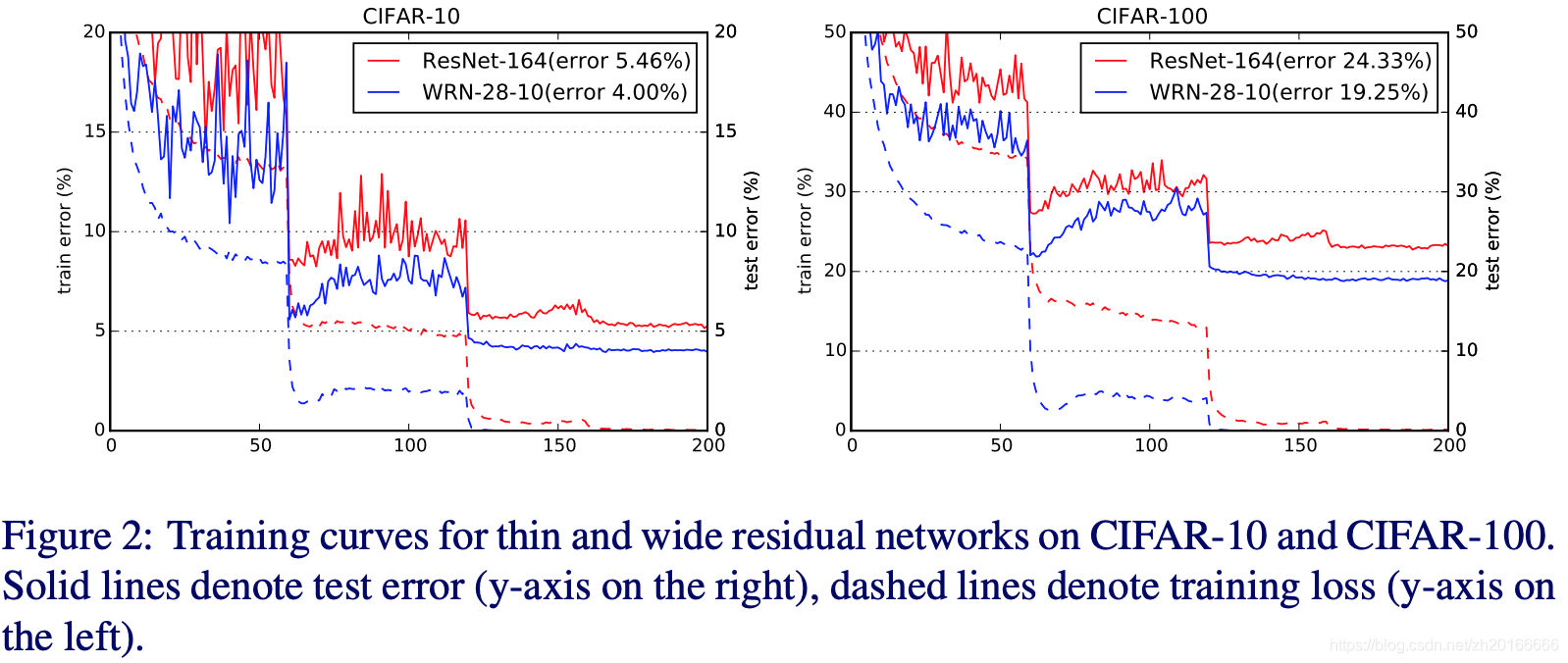 上面的圖是thin和wide的residual networks在在訓練和測試時錯誤率的變化曲線。
根據上面的實驗,作者得出一下幾點結論:
上面的圖是thin和wide的residual networks在在訓練和測試時錯誤率的變化曲線。
根據上面的實驗,作者得出一下幾點結論:
- 寬度的增加提高了效能
- 增加深度和寬度都有好處,直到引數太大,regularization不夠
- 相同引數時,寬度比深度好訓練
Dropout in residual blocks
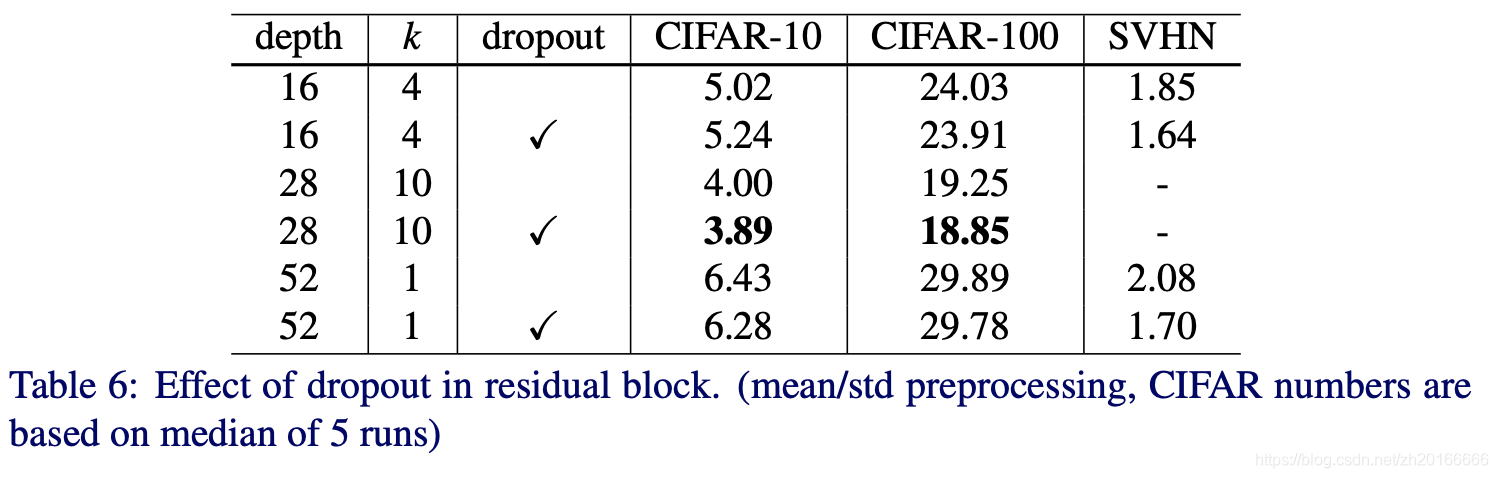 從上表可以看出dropout減少了各種WRN的錯誤率,但是在WRN-16-4在CIFAR-10資料集上準確率卻有一點下降,可能是因為WRN-16-4的引數數量相對較少。
從上表可以看出dropout減少了各種WRN的錯誤率,但是在WRN-16-4在CIFAR-10資料集上準確率卻有一點下降,可能是因為WRN-16-4的引數數量相對較少。
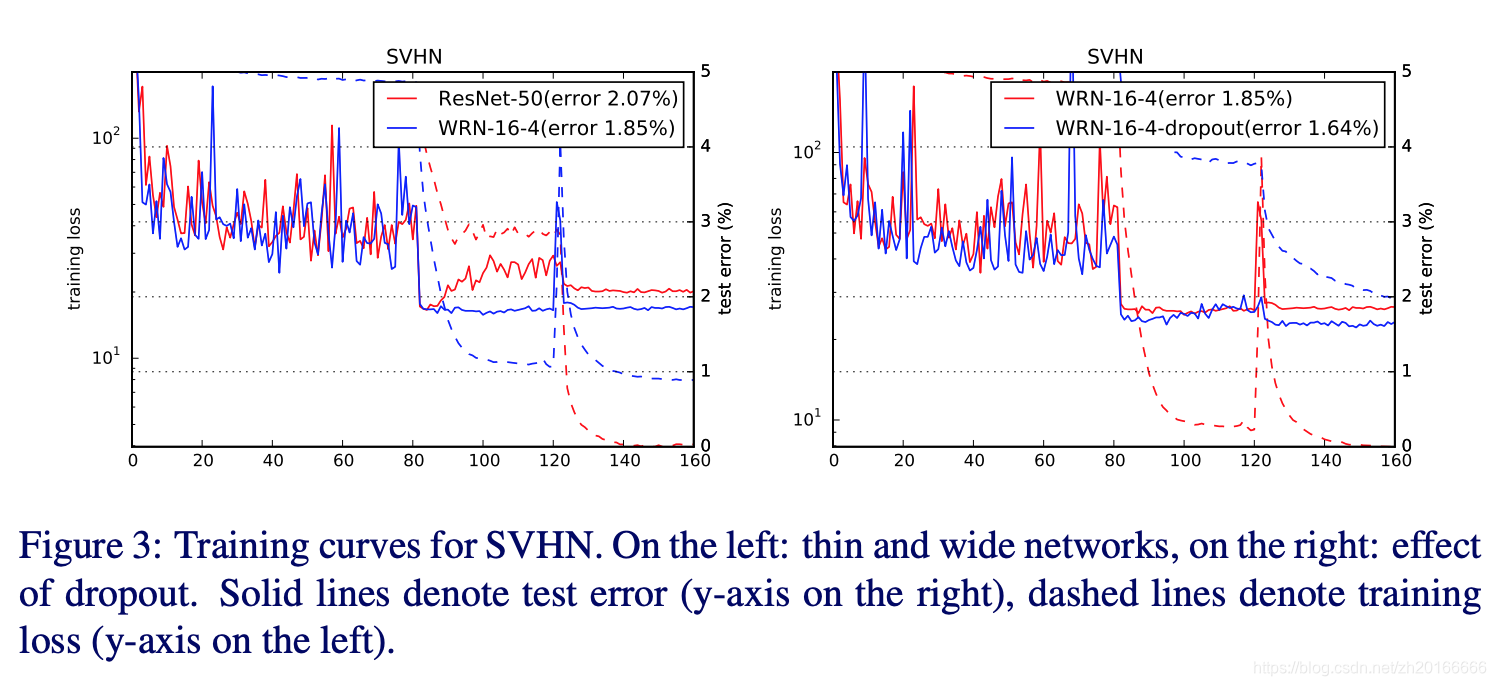
dropout能夠增加正則化的效果,這個可以在Figure 3中看出來。在訓練集上沒有使用dropout時損失可以降的很低。但是在測試時添加了dropout的效果卻更好。
 ImageNet and COCO experiment
這部分就不詳細說了,大家可以自己去看論文。
Computation efficiency
ImageNet and COCO experiment
這部分就不詳細說了,大家可以自己去看論文。
Computation efficiency
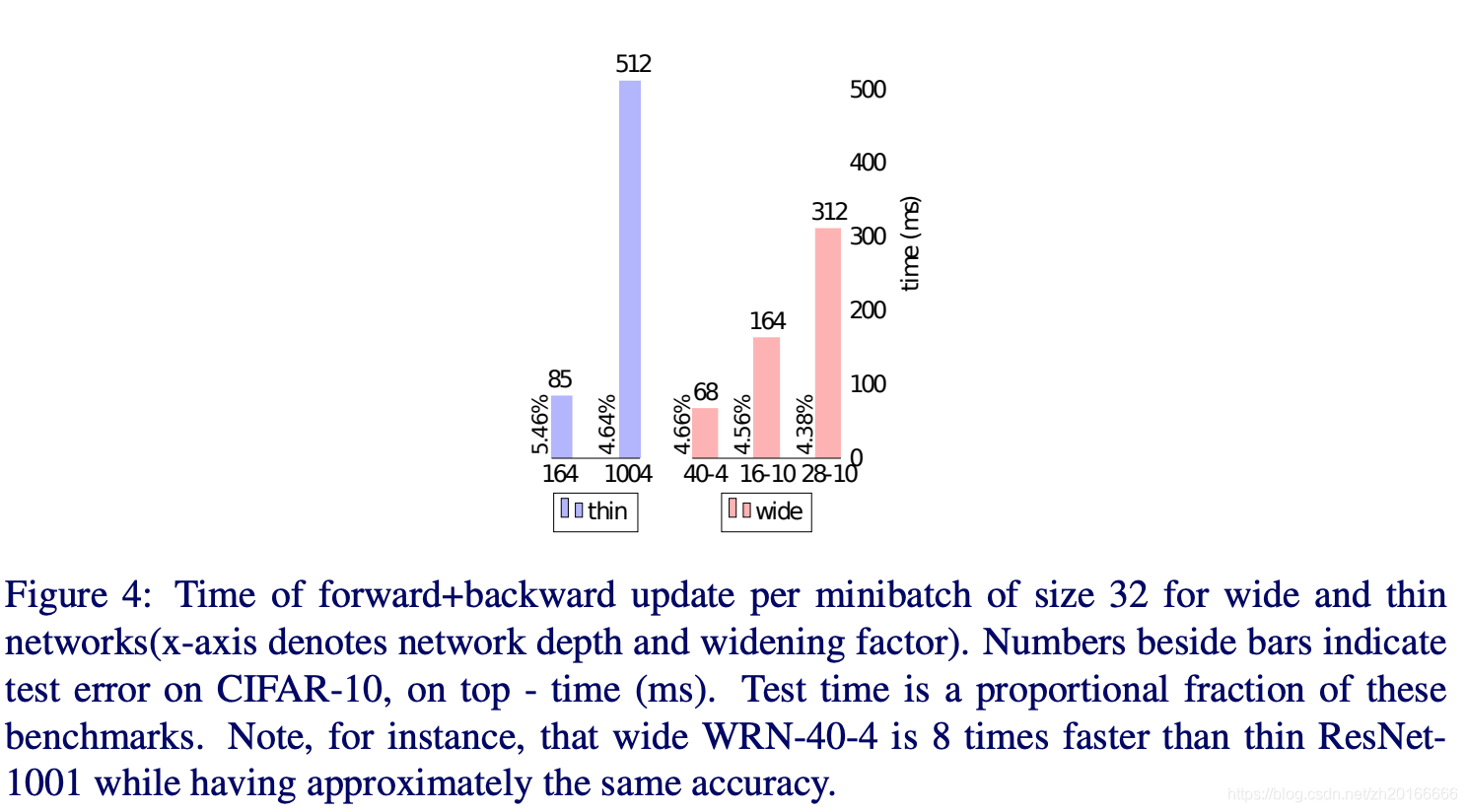 增加寬度可能會增加引數數量,但是對GPU來說他很擅長做並行的計算。從上面的圖可以看出效果最好的WRN-28-10訓練的速度比ResNet-1001快1.6倍。對於準確率差不多的WRN-40-4和ResNet-1001,WRN-40-4快8倍。
增加寬度可能會增加引數數量,但是對GPU來說他很擅長做並行的計算。從上面的圖可以看出效果最好的WRN-28-10訓練的速度比ResNet-1001快1.6倍。對於準確率差不多的WRN-40-4和ResNet-1001,WRN-40-4快8倍。