線性迴歸模型採用梯度下降演算法求最優解
本人學習人工智慧之深度學習已有一段時間,第一個機器學習演算法就是梯度下降演算法,本部落格將詳細闡述線性迴歸模型採用梯度下降演算法求得最優解。
本文將從運用以下流程圖講解SGD:
1、線性迴歸模型
2、代價函式
3、使用梯度下降最小化代價函式
第一部分:線性迴歸模型
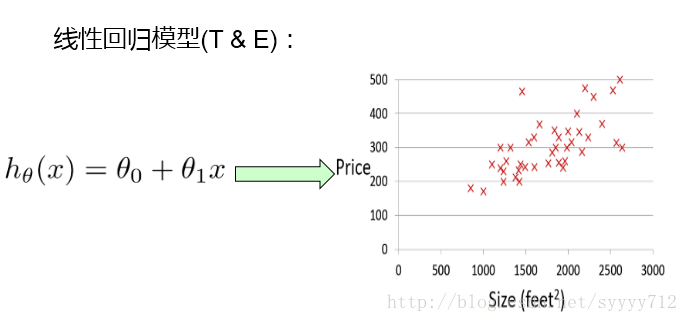
右圖橫座標為房子大小,縱座標為房子的價格,從紅色的資料集中可以看出該資料集可以採用線性迴歸模型進行擬合,當然也可以採用多項式,這裡講解就採用比較簡單的線性迴歸,左邊的公式是線性迴歸的公式。
第二部分:代價函式
代價函式主要是測試我們所假設的線性迴歸模型的效能優劣,
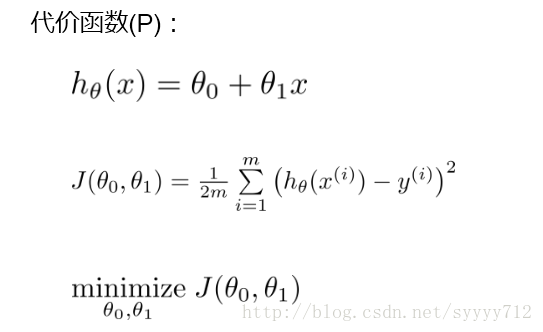
第一個公式是我們第一部分所假設的線性迴歸模型,第二個公式是代價函式J,該函式是一個平方誤差函式,是線性迴歸模型中比較典型的代價函式。其中m是指所給資料的容量大小,y是所給樣本對應x值的真實的y值。h是指我們假設的模型對應相應的x值預估的y’值。獲取模型函式和代價函式之後,接下來的目標就是最小化代價函式,使得模型預估值和真實值之間的差距最小。
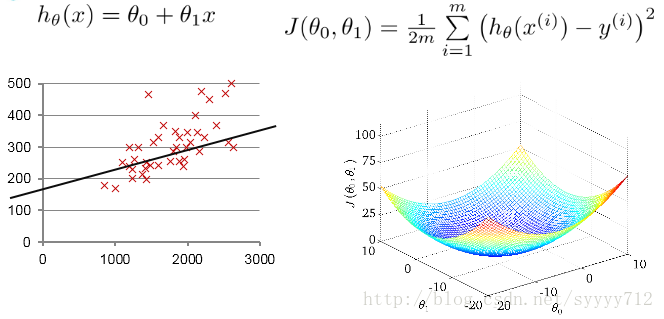
上圖是根據模型公式用matlab畫出的三維圖形,我們的目標是運用梯度下降使獲得J的最低點。
第三部分:使用梯度下降最小化代價函式
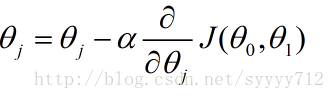
上述公式是梯度下降演算法公式,代價函式分別對兩個引數進行求導得出
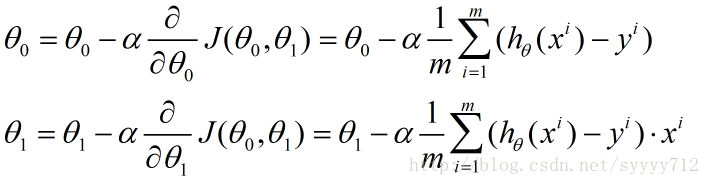
接下來介紹一下梯度下降演算法中微分項和學習率a如何執行梯度下降
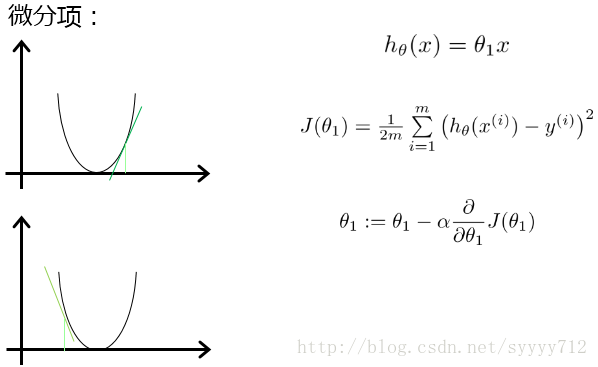
上圖第一個公式是模型數學公式,對應第一個公式,其畫出的代價函式的圖形是如圖所示,圖中的綠色的斜線的斜率代表了微分項的值,當斜率大於0時
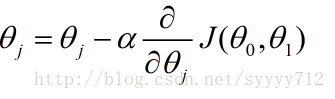
該公式計算得到的值就會比原先的值小,因此斜線的斜率會更加平緩,同時與J的切點也會更加靠近最低點,當斜率小於0也是同理。
學習率:
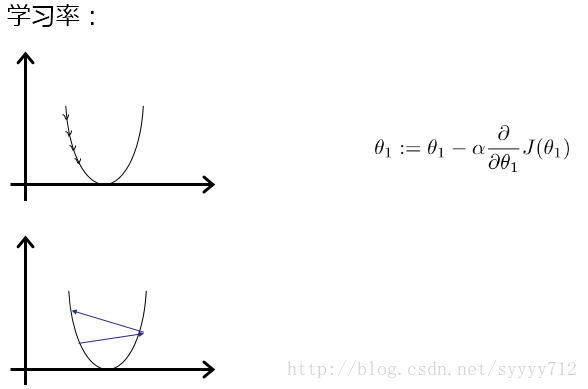
當a適當時
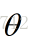
以下是我用python寫的一個線性迴歸模型梯度下降程式碼,主要用到了上述我所講的模型公式和代價函式公式:
from __future__ import division
x=[100,120,130,150,200]
y=[1000000,1200000,1300000,1500000,2000000]
epsilon = 0.000001
alpha = 0.001
error0 = 0
error1 = 0
diff = 0
theta0 = 0
theta1 = 10000
m = len(x)
#計算引數
for i in range(m):
diff = diff + (y[i]-(theta0 + theta1 * x[i]))
theta0 = theta0 - alpha * diff / 5 執行結果: