
Artwork Personalization at Netflix
Artwork Personalization at Netflix
For many years, the main goal of the Netflix personalized recommendation system has been to get the right titles in front each of our members at the right time. With a catalog spanning thousands of titles and a diverse member base spanning over a hundred million accounts, recommending the titles that are just right for each member is crucial. But the job of recommendation does not end there. Why should you care about any particular title we recommend? What can we say about a new and unfamiliar title that will pique your interest? How do we convince you that a title is worth watching? Answering these questions is critical in helping our members discover great content, especially for unfamiliar titles. One avenue to address this challenge is to consider the artwork or imagery we use to portray the titles. If the artwork representing a title captures something compelling to you, then it acts as a gateway into that title and gives you some visual “evidence” for why the title might be good for you. The artwork may highlight an actor that you recognize, capture an exciting moment like a car chase, or contain a dramatic scene that conveys the essence of a movie or TV show. If we present that perfect image on your homepage (and as they say: an image is worth a thousand words), then maybe, just maybe, you will give it a try. This is yet another way Netflix differs from traditional media offerings: we don’t have one product but over a 100 million different products with one for each of our members with personalized recommendations


In previous work, we discussed an effort to find the single perfect artwork for each title across all our members. Through multi-armed bandit algorithms, we hunted for the best artwork for a title, say Stranger Things, that would earn the most plays from the largest fraction of our members. However, given the enormous diversity in taste and preferences, wouldn’t it be better if we could find the best artwork for each


As inspiration, let us explore scenarios where personalization of artwork would be meaningful. Consider the following examples where different members have different viewing histories. On the left are three titles a member watched in the past. To the right of the arrow is the artwork that a member would get for a particular movie that we recommend for them.
Let us consider trying to personalize the image we use to depict the movie Good Will Hunting. Here we might personalize this decision based on how much a member prefers different genres and themes. Someone who has watched many romantic movies may be interested in Good Will Hunting if we show the artwork containing Matt Damon and Minnie Driver, whereas, a member who has watched many comedies might be drawn to the movie if we use the artwork containing Robin Williams, a well-known comedian.


In another scenario, let’s imagine how the different preferences for cast members might influence the personalization of the artwork for the movie Pulp Fiction. A member who watches many movies featuring Uma Thurman would likely respond positively to the artwork for Pulp Fiction that contains Uma. Meanwhile, a fan of John Travolta may be more interested in watching Pulp Fiction if the artwork features John.


Of course, not all the scenarios for personalizing artwork are this clear and obvious. So we don’t enumerate such hand-derived rules but instead rely on the data to tell us what signals to use. Overall, by personalizing artwork we help each title put its best foot forward for every member and thus improve our member experience.
Challenges
At Netflix, we embrace personalization and algorithmically adapt many aspects of our member experience, including the rows we select for the homepage, the titles we select for those rows, the galleries we display, the messages we send, and so forth. Each new aspect that we personalize has unique challenges; personalizing the artwork we display is no exception and presents different personalization challenges. One challenge of image personalization is that we can only select a single piece of artwork to represent each title in each place we present it. In contrast, typical recommendation settings let us present multiple selections to a member where we can subsequently learn about their preferences from the item a member selects. This means that image selection is a chicken-and-egg problem operating in a closed loop: if a member plays a title it can only come from the image that we decided to present to that member. What we seek to understand is when presenting a specific piece of artwork for a title influenced a member to play (or not to play) a title and when a member would have played a title (or not) regardless of which image we presented. Therefore artwork personalization sits on top of the traditional recommendation problem and the algorithms need to work in conjunction with each other. Of course, to properly learn how to personalize artwork we need to collect a lot of data to find signals that indicate when one piece of artwork is significantly better for a member.
Another challenge is to understand the impact of changing artwork that we show a member for a title between sessions. Does changing artwork reduce recognizability of the title and make it difficult to visually locate the title again, for example if the member thought was interested before but had not yet watched it? Or, does changing the artwork itself lead the member to reconsider it due to an improved selection? Clearly, if we find better artwork to present to a member we should probably use it; but continuous changes can also confuse people. Changing images also introduces an attribution problem as it becomes unclear which image led a member to be interested in a title.
Next, there is the challenge of understanding how artwork performs in relation to other artwork we select in the same page or session. Maybe a bold close-up of the main character works for a title on a page because it stands out compared to the other artwork. But if every title had a similar image then the page as a whole may not seem as compelling. Looking at each piece of artwork in isolation may not be enough and we need to think about how to select a diverse set of images across titles on a page and across a session. Beyond the artwork for other titles, the effectiveness of the artwork for a title may depend on what other types of evidence and assets (e.g. synopses, trailers, etc.) we also display for that title. Thus, we may need a diverse selection where each can highlight complementary aspects of a title that may be compelling to a member.
To achieve effective personalization, we also need a good pool of artwork for each title. This means that we need several assets where each is engaging, informative and representative of a title to avoid “clickbait”. The set of images for a title also needs to be diverse enough to cover a wide potential audience interested in different aspects of the content. After all, how engaging and informative a piece of artwork is truly depends on the individual seeing it. Therefore, we need to have artwork that highlights not only different themes in a title but also different aesthetics. Our teams of artists and designers strive to create images that are diverse across many dimensions. They also take into consideration the personalization algorithms which will select the images during their creative process for generating artwork.
Finally, there are engineering challenges to personalize artwork at scale. One challenge is that our member experience is very visual and thus contains a lot of imagery. So using personalized selection for each asset means handling a peak of over 20 million requests per second with low latency. Such a system must be robust: failing to properly render the artwork in our UI brings a significantly degrades the experience. Our personalization algorithm also needs to respond quickly when a title launches, which means rapidly learning to personalize in a cold-start situation. Then, after launch, the algorithm must continuously adapt as the effectiveness of artwork may change over time as both the title evolves through its life cycle and member tastes evolve.
Contextual bandits approach
Much of the Netflix recommendation engine is powered by machine learning algorithms. Traditionally, we collect a batch of data on how our members use the service. Then we run a new machine learning algorithm on this batch of data. Next we test this new algorithm against the current production system through an A/B test. An A/B test helps us see if the new algorithm is better than our current production system by trying it out on a random subset of members. Members in group A get the current production experience while members in group B get the new algorithm. If members in group B have higher engagement with Netflix, then we roll-out the new algorithm to the entire member population. Unfortunately, this batch approach incurs regret: many members over a long period of time did not benefit from the better experience. This is illustrated in the figure below.

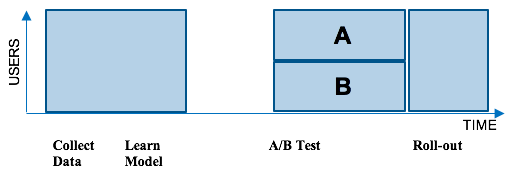


To reduce this regret, we move away from batch machine learning and consider online machine learning. For artwork personalization, the specific online learning framework we use is contextual bandits. Rather than waiting to collect a full batch of data, waiting to learn a model, and then waiting for an A/B test to conclude, contextual bandits rapidly figure out the optimal personalized artwork selection for a title for each member and context. Briefly, contextual bandits are a class of online learning algorithms that trade off the cost of gathering training data required for learning an unbiased model on an ongoing basis with the benefits of applying the learned model to each member context. In our previous unpersonalized image selection work, we used non-contextual bandits where we found the winning image regardless of the context. For personalization, the member is the context as we expect different members to respond differently to the images.
A key property of contextual bandits is that they are designed to minimize regret. At a high level, the training data for a contextual bandit is obtained through the injection of controlled randomization in the learned model’s predictions. The randomization schemes can vary in complexity from simple epsilon-greedy formulations with uniform randomness to closed loop schemes that adaptively vary the degree of randomization as a function of model uncertainty. We broadly refer to this process as data exploration. The number of candidate artworks that are available for a title along with the size of the overall population for which the system will be deployed informs the choice of the data exploration strategy. With such exploration, we need to log information about the randomization for each artwork selection. This logging allows us to correct for skewed selection propensities and thereby perform offline model evaluation in an unbiased fashion, as described later.
Exploration in contextual bandits typically has a cost (or regret) due to the fact that our artwork selection in a member session may not use the predicted best image for that session. What impact does this randomization have on the member experience (and consequently on our metrics)? With over a hundred millions members, the regret incurred by exploration is typically very small and is amortized across our large member base with each member implicitly helping provide feedback on artwork for a small portion of the catalog. This makes the cost of exploration per member negligible, which is an important consideration when choosing contextual bandits to drive a key aspect of our member experience. Randomization and exploration with contextual bandits would be less suitable if the cost of exploration were high.
Under our online exploration scheme, we obtain a training dataset that records, for each (member, title, image) tuple, whether that selection resulted in a play of the title or not. Furthermore, we can control the exploration such that artwork selections do not change too often. This gives a cleaner attribution of the member’s engagement to specific artwork. We also carefully determine the label for each observation by looking at the quality of engagement to avoid learning a model that recommends “clickbait” images: ones that entice a member to start playing but ultimately result in low-quality engagement.
Model training
In this online learning setting, we train our contextual bandit model to select the best artwork for each member based on their context. We typically have up to a few dozen candidate artwork images per title. To learn the selection model, we can consider a simplification of the problem by ranking images for a member independently across titles. Even with this simplification we can still learn member image preferences across titles because, for every image candidate, we have some members who were presented with it and engaged with the title and some members who were presented with it and did not engage. These preferences can be modeled to predict for each (member, title, image) tuple, the probability that the member will enjoy a quality engagement. These can be supervised learning models or contextual bandit counterparts with Thompson Sampling, LinUCB, or Bayesian methods that intelligently balance making the best prediction with data exploration.
Potential signals
In contextual bandits, the context is usually represented as an feature vector provided as input to the model. There are many signals we can use as features for this problem. In particular, we can consider many attributes of the member: the titles they’ve played, the genre of the titles, interactions of the member with the specific title, their country, their language preferences, the device that the member is using, the time of day and the day of week. Since our algorithm selects images in conjunction with our personalized recommendation engine, we can also use signals regarding what our various recommendation algorithms think of the title, irrespective of what image is used to represent it.
An important consideration is that some images are naturally better than others in the candidate pool. We observe the overall take rates for all the images in our data exploration, which is simply the number of quality plays divided by the number of impressions. Our previous work on unpersonalized artwork selection used overall differences in take rates to determine the single best image to select for a whole population. In our new contextual personalized model, the overall take rates are still important and personalization still recovers selections that agree on average with the unpersonalized model’s ranking.
Image Selection
The optimal assignment of image artwork to a member is a selection problem to find the best candidate image from a title’s pool of available images. Once the model is trained as above, we use it to rank the images for each context. The model predicts the probability of play for a given image in a given a member context. We sort a candidate set of images by these probabilities and pick the one with the highest probability. That is the image we present to that particular member.
Performance evaluation
Offline
To evaluate our contextual bandit algorithms prior to deploying them online on real members, we can use an offline technique known as replay [1]. This method allows us to answer counterfactual questions based on the logged exploration data (Figure 1). In other words, we can compare offline what would have happened in historical sessions under different scenarios if we had used different algorithms in an unbiased way.

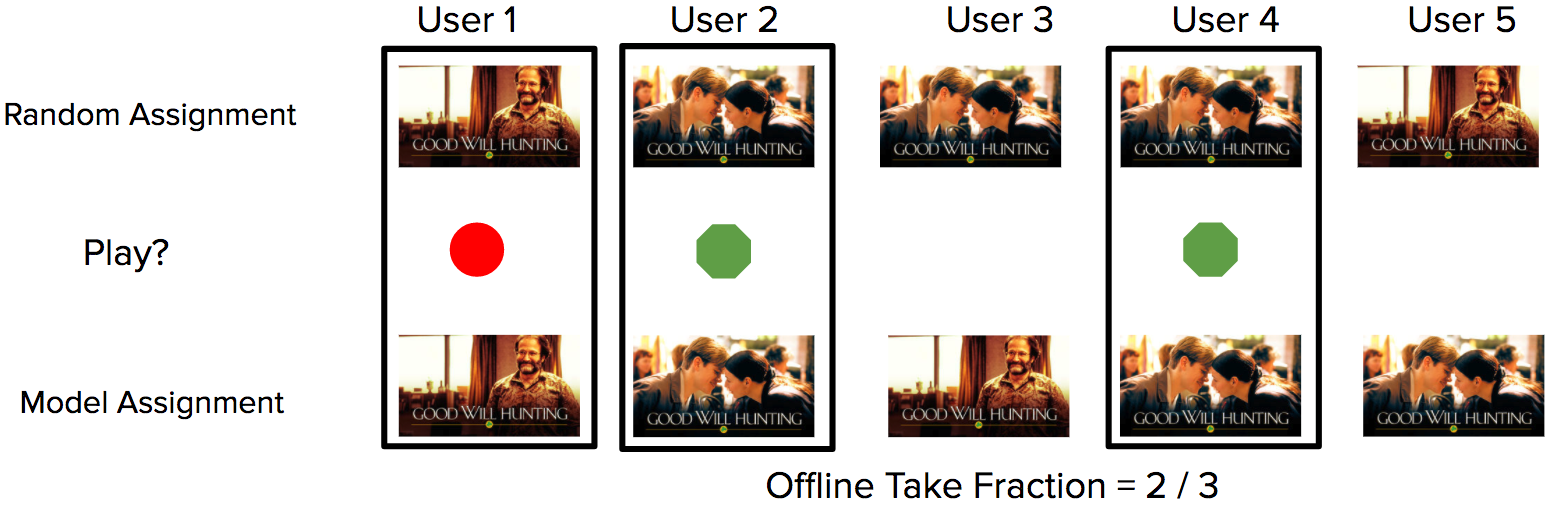
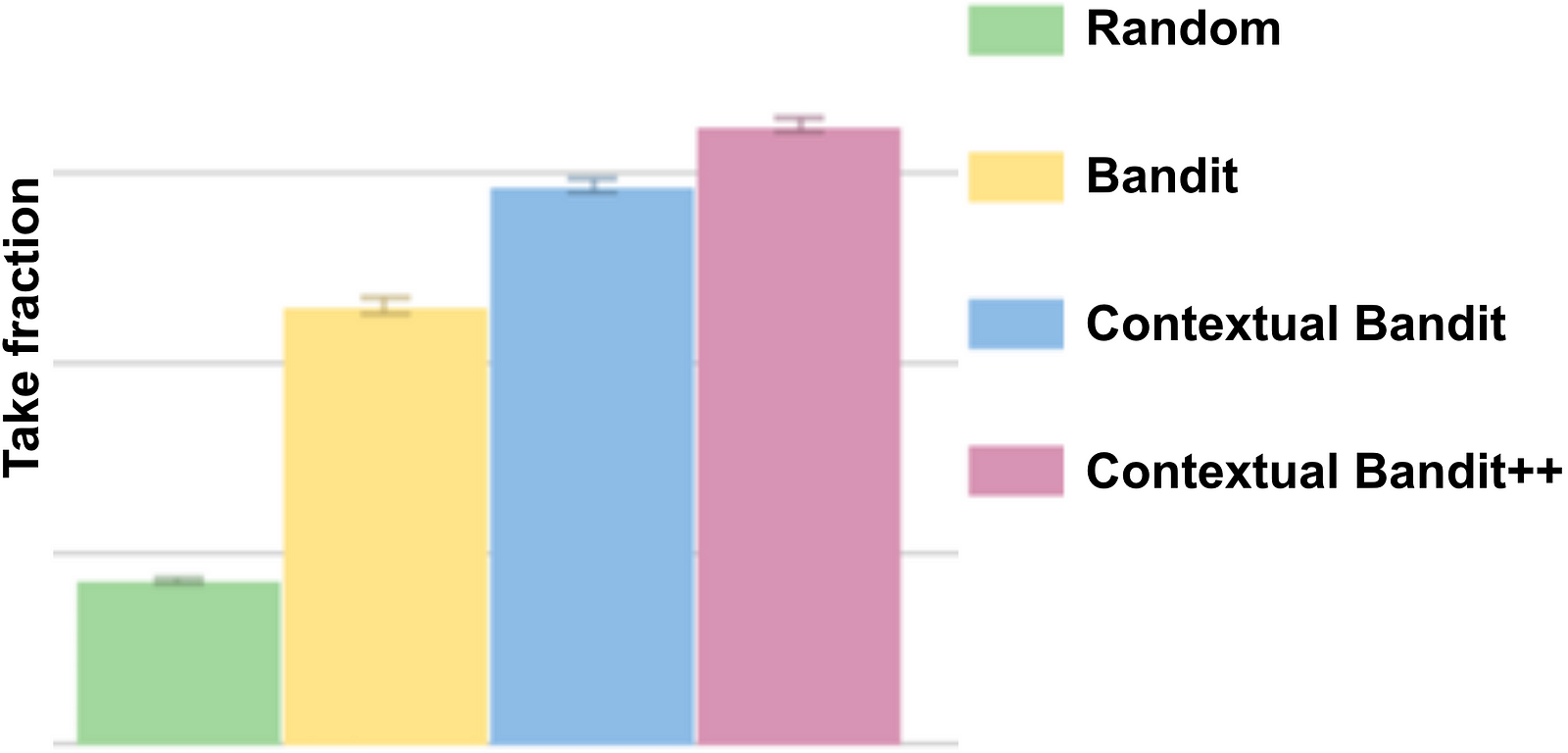
Replay allows us to see how members would have engaged with our titles if we had hypothetically presented images that were selected through a new algorithm rather than the algorithm used in production. For images, we are interested in several metrics, particularly the take fraction, as described above. Figure 2 shows how contextual bandit approach helps increase the average take fraction across the catalog compared to random selection or non-contextual bandits.


Online
After experimenting with many different models offline and finding ones that had a substantial increase in replay, we ultimately ran an A/B test to compare the most promising personalized contextual bandits against unpersonalized bandits. As we suspected, the personalization worked and generated a significant lift in our core metrics. We also saw a reasonable correlation between what we measured offline in replay and what we saw online with the models. The online results also produced some interesting insights. For example, the improvement of personalization was larger in cases where the member had no prior interaction with the title. This makes sense because we would expect that the artwork would be more important to someone when a title is less familiar.
Conclusion
With this approach, we’ve taken our first steps in personalizing the selection of artwork for our recommendations and across our service. This has resulted in a meaningful improvement in how our members discover new content… so we’ve rolled it out to everyone! This project is the first instance of personalizing not just what we recommend but also how we recommend to our members. But there are many opportunities to expand and improve this initial approach. These opportunities include developing algorithms to handle cold-start by personalizing new images and new titles as quickly as possible, for example by using techniques from computer vision. Another opportunity is extending this personalization approach across other types of artwork we use and other evidence that describe our titles such as synopses, metadata, and trailers. There is also an even broader problem: helping artists and designers figure out what new imagery we should add to the set to make a title even more compelling and personalizable.
If these types of challenges interest you, please let us know! We are always looking for great people to join our team, and, for these types of projects, we are especially excited by candidates with machine learning and/or computer vision expertise.
References
[1] L. Li, W. Chu, J. Langford, and X. Wang, “Unbiased Offline Evaluation of Contextual-bandit-based News Article Recommendation Algorithms,” in Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, New York, NY, USA, 2011, pp. 297–306.