CNN經典模型:AlexNet
2012年,Alex Krizhevsky、Ilya Sutskever在多倫多大學Geoff Hinton的實驗室設計出了一個深層的卷積神經網路AlexNet,奪得了2012年ImageNet LSVRC的冠軍,且準確率遠超第二名(top5錯誤率為15.3%,第二名為26.2%),引起了很大的轟動。AlexNet可以說是具有歷史意義的一個網路結構,在此之前,深度學習已經沉寂了很長時間,自2012年AlexNet誕生之後,後面的ImageNet冠軍都是用卷積神經網路(CNN)來做的,並且層次越來越深,使得CNN成為在影象識別分類的核心演算法模型,帶來了深度學習的大爆發。
在本部落格之前的文章中已經介紹過了卷積神經網路(CNN)的技術原理(
一、AlexNet模型的特點
AlexNet之所以能夠成功,跟這個模型設計的特點有關,主要有:
- 使用了非線性啟用函式:ReLU
- 防止過擬合的方法:Dropout,資料擴充(Data augmentation)
- 其他:多GPU實現,LRN歸一化層的使用
1、使用ReLU啟用函式
傳統的神經網路普遍使用Sigmoid或者tanh等非線性函式作為激勵函式,然而它們容易出現梯度彌散或梯度飽和的情況。以Sigmoid函式為例,當輸入的值非常大或者非常小的時候,這些神經元的梯度接近於0(梯度飽和現象),如果輸入的初始值很大的話,梯度在反向傳播時因為需要乘上一個Sigmoid導數,會造成梯度越來越小,導致網路變的很難學習。(詳見本公部落格的文章:
在AlexNet中,使用了ReLU (Rectified Linear Units)激勵函式,該函式的公式為:f(x)=max(0,x),當輸入訊號<0時,輸出都是0,當輸入訊號>0時,輸出等於輸入,如下圖所示: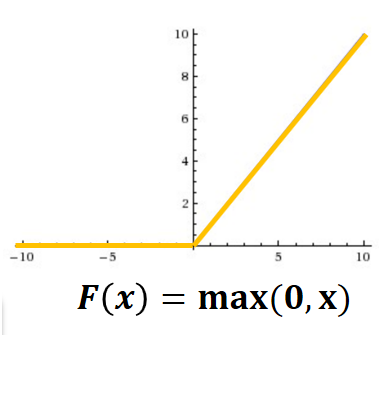
使用ReLU替代Sigmoid/tanh,由於ReLU是線性的,且導數始終為1,計算量大大減少,收斂速度會比Sigmoid/tanh快很多,如下圖所示: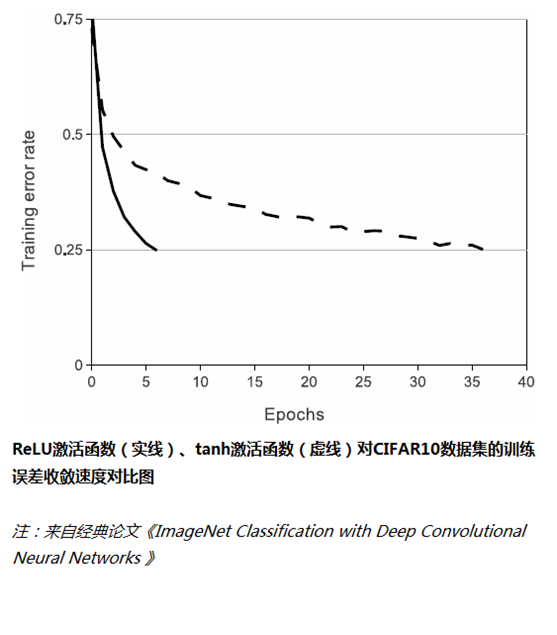
2、資料擴充(Data augmentation)
有一種觀點認為神經網路是靠資料喂出來的,如果能夠增加訓練資料,提供海量資料進行訓練,則能夠有效提升演算法的準確率,因為這樣可以避免過擬合,從而可以進一步增大、加深網路結構。而當訓練資料有限時,可以通過一些變換從已有的訓練資料集中生成一些新的資料,以快速地擴充訓練資料。
其中,最簡單、通用的影象資料變形的方式:水平翻轉影象,從原始影象中隨機裁剪、平移變換,顏色、光照變換,如下圖所示: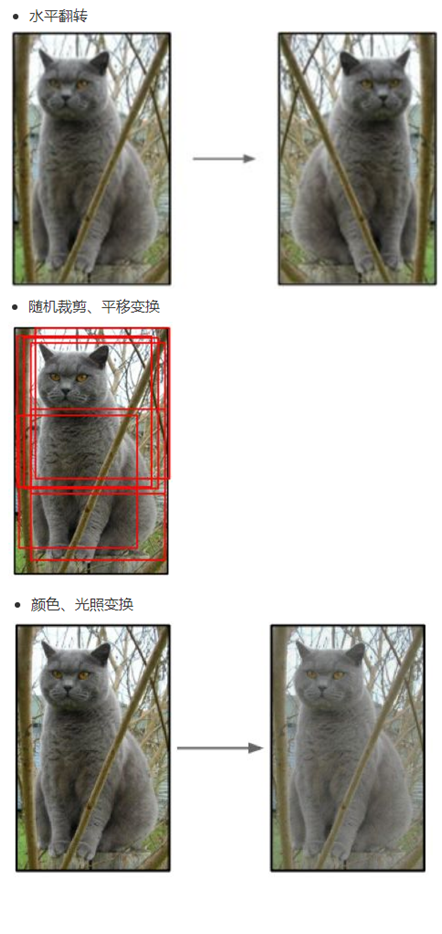
AlexNet在訓練時,在資料擴充(data augmentation)這樣處理:
(1)隨機裁剪,對256×256的圖片進行隨機裁剪到224×224,然後進行水平翻轉,相當於將樣本數量增加了((256-224)^2)×2=2048倍;
(2)測試的時候,對左上、右上、左下、右下、中間分別做了5次裁剪,然後翻轉,共10個裁剪,之後對結果求平均。作者說,如果不做隨機裁剪,大網路基本上都過擬合;
(3)對RGB空間做PCA(主成分分析),然後對主成分做一個(0, 0.1)的高斯擾動,也就是對顏色、光照作變換,結果使錯誤率又下降了1%。
3、重疊池化 (Overlapping Pooling)
一般的池化(Pooling)是不重疊的,池化區域的視窗大小與步長相同,如下圖所示: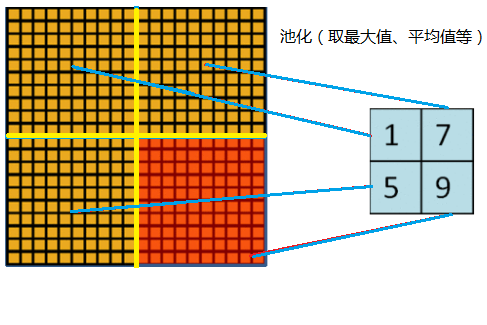
在AlexNet中使用的池化(Pooling)卻是可重疊的,也就是說,在池化的時候,每次移動的步長小於池化的視窗長度。AlexNet池化的大小為3×3的正方形,每次池化移動步長為2,這樣就會出現重疊。重疊池化可以避免過擬合,這個策略貢獻了0.3%的Top-5錯誤率。
4、區域性歸一化(Local Response Normalization,簡稱LRN)
在神經生物學有一個概念叫做“側抑制”(lateral inhibitio),指的是被啟用的神經元抑制相鄰神經元。歸一化(normalization)的目的是“抑制”,區域性歸一化就是借鑑了“側抑制”的思想來實現區域性抑制,尤其當使用ReLU時這種“側抑制”很管用,因為ReLU的響應結果是無界的(可以非常大),所以需要歸一化。使用區域性歸一化的方案有助於增加泛化能力。
LRN的公式如下,核心思想就是利用臨近的資料做歸一化,這個策略貢獻了1.2%的Top-5錯誤率。
5、Dropout
引入Dropout主要是為了防止過擬合。在神經網路中Dropout通過修改神經網路本身結構來實現,對於某一層的神經元,通過定義的概率將神經元置為0,這個神經元就不參與前向和後向傳播,就如同在網路中被刪除了一樣,同時保持輸入層與輸出層神經元的個數不變,然後按照神經網路的學習方法進行引數更新。在下一次迭代中,又重新隨機刪除一些神經元(置為0),直至訓練結束。
Dropout應該算是AlexNet中一個很大的創新,以至於“神經網路之父”Hinton在後來很長一段時間裡的演講中都拿Dropout說事。Dropout也可以看成是一種模型組合,每次生成的網路結構都不一樣,通過組合多個模型的方式能夠有效地減少過擬合,Dropout只需要兩倍的訓練時間即可實現模型組合(類似取平均)的效果,非常高效。
如下圖所示: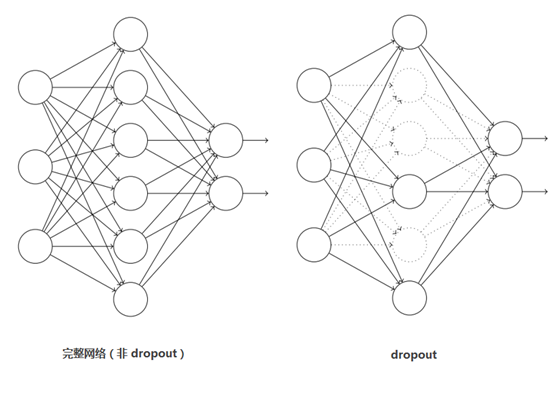
6、多GPU訓練
AlexNet當時使用了GTX580的GPU進行訓練,由於單個GTX 580 GPU只有3GB記憶體,這限制了在其上訓練的網路的最大規模,因此他們在每個GPU中放置一半核(或神經元),將網路分佈在兩個GPU上進行平行計算,大大加快了AlexNet的訓練速度。
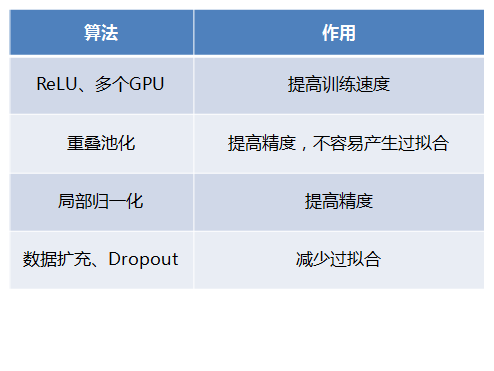
二、AlexNet網路結構的逐層解析
下圖是AlexNet的網路結構圖: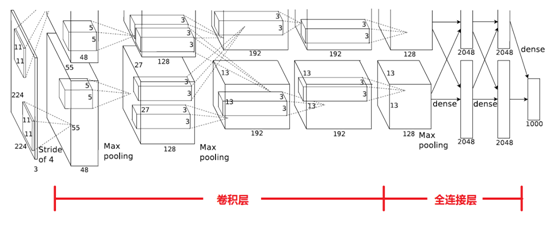
AlexNet網路結構共有8層,前面5層是卷積層,後面3層是全連線層,最後一個全連線層的輸出傳遞給一個1000路的softmax層,對應1000個類標籤的分佈。
由於AlexNet採用了兩個GPU進行訓練,因此,該網路結構圖由上下兩部分組成,一個GPU執行圖上方的層,另一個執行圖下方的層,兩個GPU只在特定的層通訊。例如第二、四、五層卷積層的核只和同一個GPU上的前一層的核特徵圖相連,第三層卷積層和第二層所有的核特徵圖相連線,全連線層中的神經元和前一層中的所有神經元相連線。
下面逐層解析AlexNet結構:
1、第一層(卷積層)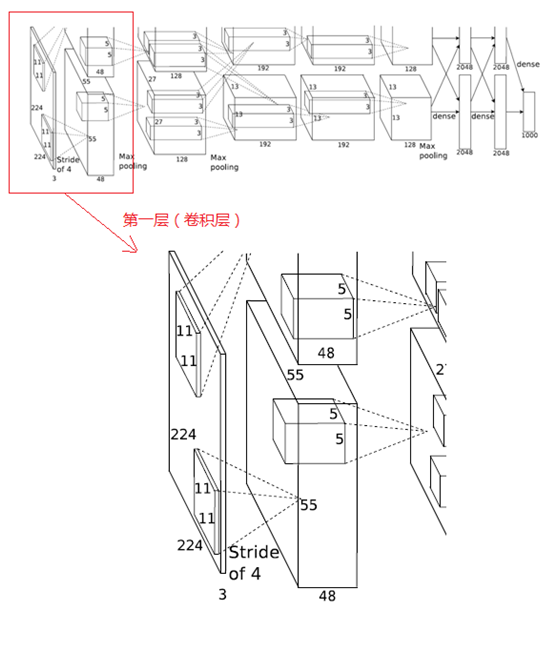
該層的處理流程為:卷積-->ReLU-->池化-->歸一化,流程圖如下: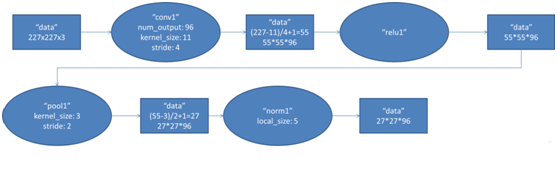
(1)卷積
輸入的原始影象大小為224×224×3(RGB影象),在訓練時會經過預處理變為227×227×3。在本層使用96個11×11×3的卷積核進行卷積計算,生成新的畫素。由於採用了兩個GPU並行運算,因此,網路結構圖中上下兩部分分別承擔了48個卷積核的運算。
卷積核沿影象按一定的步長往x軸方向、y軸方向移動計算卷積,然後生成新的特徵圖,其大小為:floor((img_size - filter_size)/stride) +1 = new_feture_size,其中floor表示向下取整,img_size為影象大小,filter_size為核大小,stride為步長,new_feture_size為卷積後的特徵圖大小,這個公式表示影象尺寸減去卷積核尺寸除以步長,再加上被減去的核大小畫素對應生成的一個畫素,結果就是卷積後特徵圖的大小。
AlexNet中本層的卷積移動步長是4個畫素,卷積核經移動計算後生成的特徵圖大小為 (227-11)/4+1=55,即55×55。
(2)ReLU
卷積後的55×55畫素層經過ReLU單元的處理,生成啟用畫素層,尺寸仍為2組55×55×48的畫素層資料。
(3)池化
RuLU後的畫素層再經過池化運算,池化運算的尺寸為3×3,步長為2,則池化後圖像的尺寸為 (55-3)/2+1=27,即池化後像素的規模為27×27×96
(4)歸一化
池化後的畫素層再進行歸一化處理,歸一化運算的尺寸為5×5,歸一化後的畫素規模不變,仍為27×27×96,這96層畫素層被分為兩組,每組48個畫素層,分別在一個獨立的GPU上進行運算。
2、第二層(卷積層)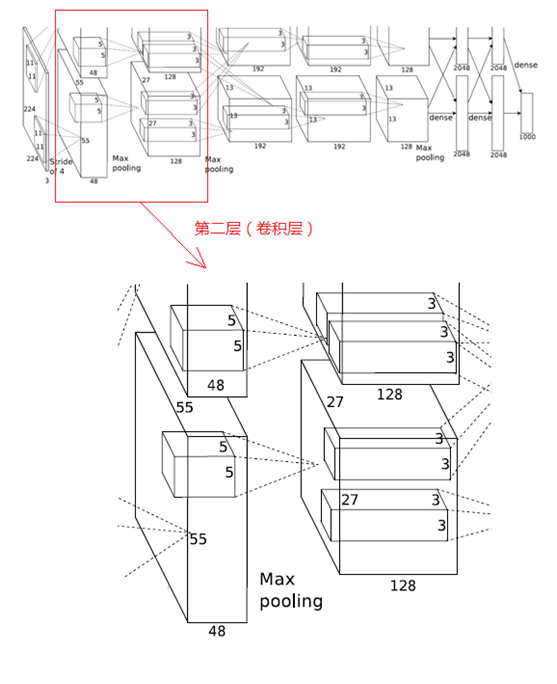
該層與第一層類似,處理流程為:卷積-->ReLU-->池化-->歸一化,流程圖如下: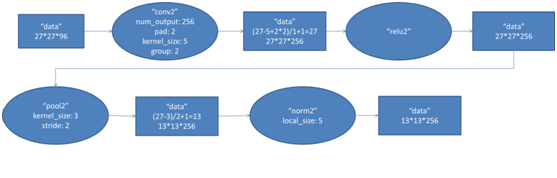
(1)卷積
第二層的輸入資料為第一層輸出的27×27×96的畫素層(被分成兩組27×27×48的畫素層放在兩個不同GPU中進行運算),為方便後續處理,在這裡每幅畫素層的上下左右邊緣都被填充了2個畫素(填充0),即影象的大小變為 (27+2+2) ×(27+2+2)。第二層的卷積核大小為5×5,移動步長為1個畫素,跟第一層第(1)點的計算公式一樣,經卷積核計算後的畫素層大小變為 (27+2+2-5)/1+1=27,即卷積後大小為27×27。
本層使用了256個5×5×48的卷積核,同樣也是被分成兩組,每組為128個,分給兩個GPU進行卷積運算,結果生成兩組27×27×128個卷積後的畫素層。
(2)ReLU
這些畫素層經過ReLU單元的處理,生成啟用畫素層,尺寸仍為兩組27×27×128的畫素層。
(3)池化
再經過池化運算的處理,池化運算的尺寸為3×3,步長為2,池化後圖像的尺寸為(57-3)/2+1=13,即池化後像素的規模為2組13×13×128的畫素層
(4)歸一化
然後再經歸一化處理,歸一化運算的尺度為5×5,歸一化後的畫素層的規模為2組13×13×128的畫素層,分別由2個GPU進行運算。
3、第三層(卷積層)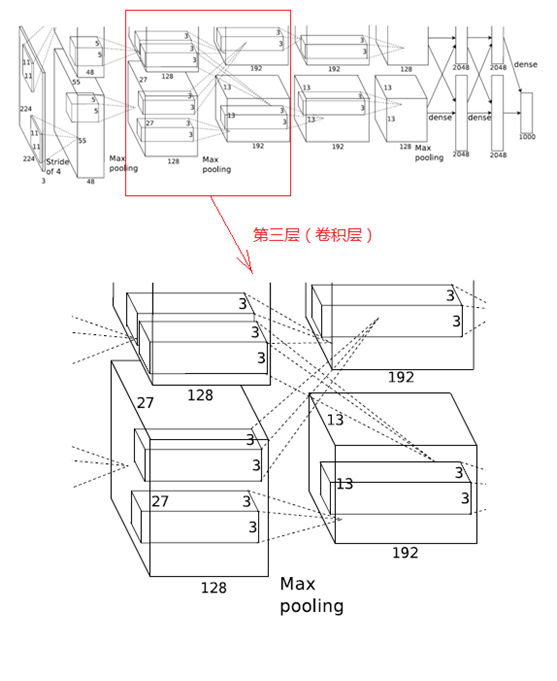
第三層的處理流程為:卷積-->ReLU
(1)卷積
第三層輸入資料為第二層輸出的2組13×13×128的畫素層,為便於後續處理,每幅畫素層的上下左右邊緣都填充1個畫素,填充後變為 (13+1+1)×(13+1+1)×128,分佈在兩個GPU中進行運算。
這一層中每個GPU都有192個卷積核,每個卷積核的尺寸是3×3×256。因此,每個GPU中的卷積核都能對2組13×13×128的畫素層的所有資料進行卷積運算。如該層的結構圖所示,兩個GPU有通過交叉的虛線連線,也就是說每個GPU要處理來自前一層的所有GPU的輸入。
本層卷積的步長是1個畫素,經過卷積運算後的尺寸為 (13+1+1-3)/1+1=13,即每個GPU中共13×13×192個卷積核,2個GPU中共有13×13×384個卷積後的畫素層。
(2)ReLU
卷積後的畫素層經過ReLU單元的處理,生成啟用畫素層,尺寸仍為2組13×13×192的畫素層,分配給兩組GPU處理。
4、第四層(卷積層)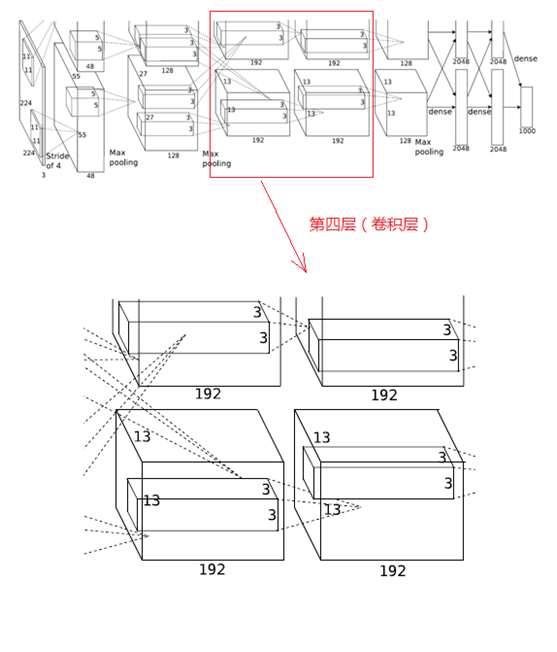
與第三層類似,第四層的處理流程為:卷積-->ReLU

(1)卷積
第四層輸入資料為第三層輸出的2組13×13×192的畫素層,類似於第三層,為便於後續處理,每幅畫素層的上下左右邊緣都填充1個畫素,填充後的尺寸變為 (13+1+1)×(13+1+1)×192,分佈在兩個GPU中進行運算。
這一層中每個GPU都有192個卷積核,每個卷積核的尺寸是3×3×192(與第三層不同,第四層的GPU之間沒有虛線連線,也即GPU之間沒有通訊)。卷積的移動步長是1個畫素,經卷積運算後的尺寸為 (13+1+1-3)/1+1=13,每個GPU中有13×13×192個卷積核,2個GPU卷積後生成13×13×384的畫素層。
(2)ReLU
卷積後的畫素層經過ReLU單元處理,生成啟用畫素層,尺寸仍為2組13×13×192畫素層,分配給兩個GPU處理。
5、第五層(卷積層)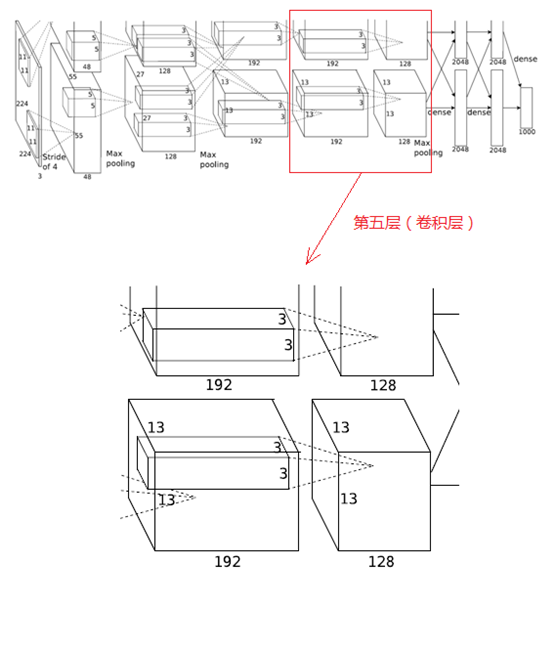
第五層的處理流程為:卷積-->ReLU-->池化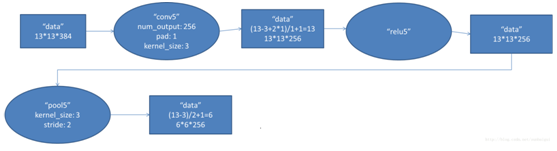
(1)卷積
第五層輸入資料為第四層輸出的2組13×13×192的畫素層,為便於後續處理,每幅畫素層的上下左右邊緣都填充1個畫素,填充後的尺寸變為 (13+1+1)×(13+1+1) ,2組畫素層資料被送至2個不同的GPU中進行運算。
這一層中每個GPU都有128個卷積核,每個卷積核的尺寸是3×3×192,卷積的步長是1個畫素,經卷積後的尺寸為 (13+1+1-3)/1+1=13,每個GPU中有13×13×128個卷積核,2個GPU卷積後生成13×13×256的畫素層。
(2)ReLU
卷積後的畫素層經過ReLU單元處理,生成啟用畫素層,尺寸仍為2組13×13×128畫素層,由兩個GPU分別處理。
(3)池化
2組13×13×128畫素層分別在2個不同GPU中進行池化運算處理,池化運算的尺寸為3×3,步長為2,池化後圖像的尺寸為 (13-3)/2+1=6,即池化後像素的規模為兩組6×6×128的畫素層資料,共有6×6×256的畫素層資料。
6、第六層(全連線層)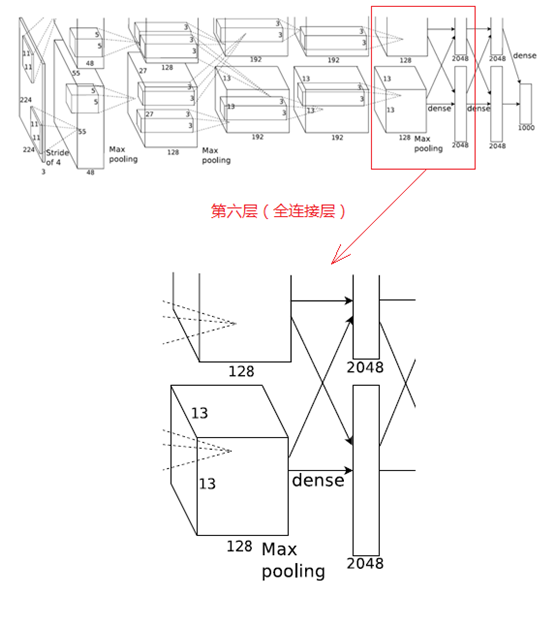
第六層的處理流程為:卷積(全連線)-->ReLU-->Dropout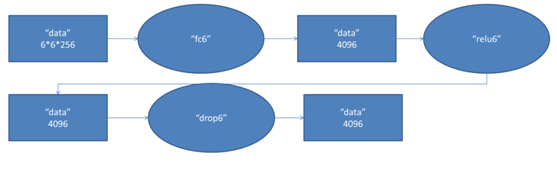
(1)卷積(全連線)
第六層輸入資料是第五層的輸出,尺寸為6×6×256。本層共有4096個卷積核,每個卷積核的尺寸為6×6×256,由於卷積核的尺寸剛好與待處理特徵圖(輸入)的尺寸相同,即卷積核中的每個係數只與特徵圖(輸入)尺寸的一個畫素值相乘,一一對應,因此,該層被稱為全連線層。由於卷積核與特徵圖的尺寸相同,卷積運算後只有一個值,因此,卷積後的畫素層尺寸為4096×1×1,即有4096個神經元。
(2)ReLU
這4096個運算結果通過ReLU啟用函式生成4096個值。
(3)Dropout
然後再通過Dropout運算,輸出4096個結果值。
7、第七層(全連線層)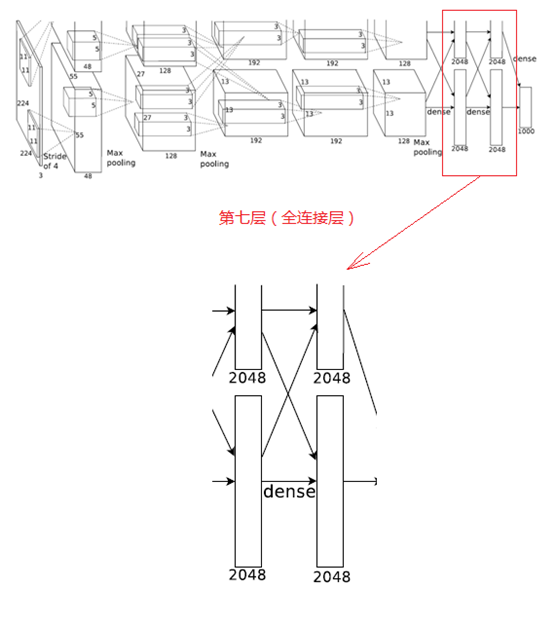
第七層的處理流程為:全連線-->ReLU-->Dropout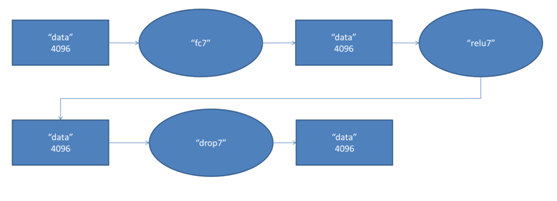
第六層輸出的4096個數據與第七層的4096個神經元進行全連線,然後經ReLU進行處理後生成4096個數據,再經過Dropout處理後輸出4096個數據。
8、第八層(全連線層)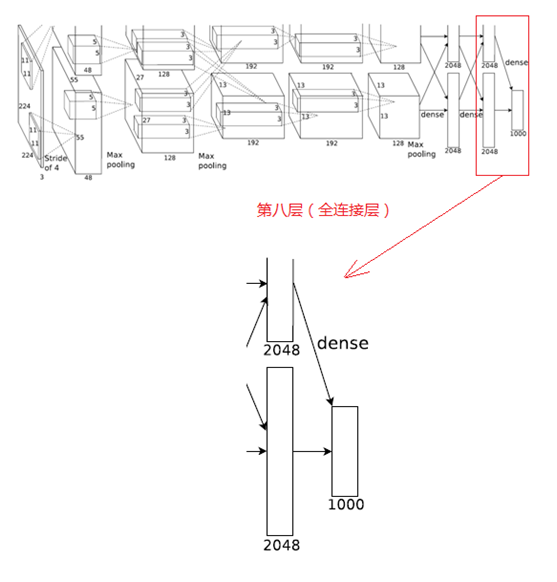
第八層的處理流程為:全連線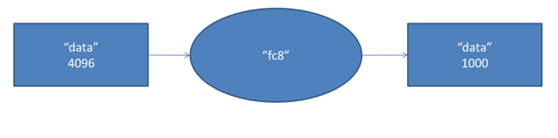
第七層輸出的4096個數據與第八層的1000個神經元進行全連線,經過訓練後輸出1000個float型的值,這就是預測結果。
以上就是關於AlexNet網路結構圖的逐層解析了,看起來挺複雜的,下面是一個簡圖,看起來就清爽很多啊
通過前面的介紹,可以看出AlexNet的特點和創新之處,主要如下: