
CNN經典模型:LeNet
阿新 • • 發佈:2019-01-02
近幾年來,卷積神經網路(Convolutional Neural Networks,簡稱CNN)在影象識別中取得了非常成功的應用,成為深度學習的一大亮點。CNN發展至今,已經有很多變種,其中有幾個經典模型在CNN發展歷程中有著里程碑的意義,它們分別是:LeNet、Alexnet、Googlenet、VGG、DRL等,接下來將分期進行逐一介紹。
在之前的文章中,已經介紹了卷積神經網路(CNN)的技術原理,細節部分就不再重複了,有興趣的同學再開啟連結看看(大話卷積神經網路),在此簡單回顧一下CNN的幾個特點:區域性感知、引數共享、池化。
1、區域性感知
人類對外界的認知一般是從區域性到全域性、從片面到全面,類似的,在機器識別影象時也沒有必要把整張影象按畫素全部都連線到神經網路中,在影象中也是區域性周邊的畫素聯絡比較緊密,而距離較遠的畫素則相關性較弱,因此可以採用區域性連線的模式(將影象分塊連線,這樣能大大減少模型的引數),如下圖所示: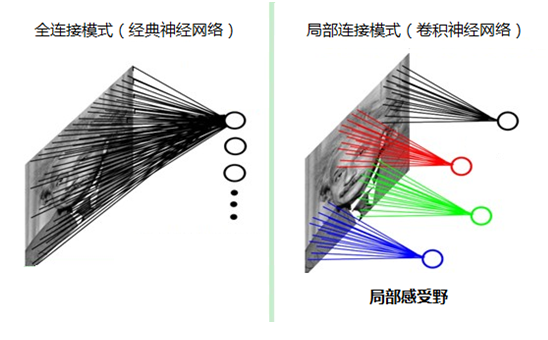
2、引數(權值)共享
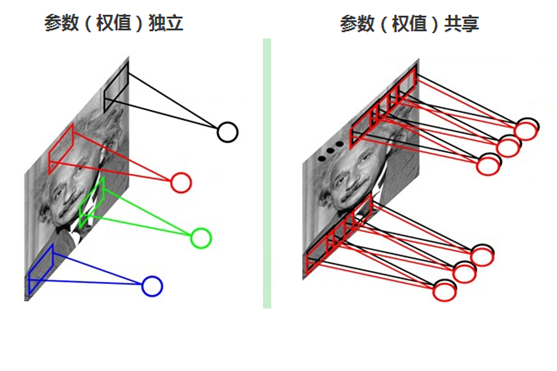
每張自然影象(人物、山水、建築等)都有其固有特性,也就是說,影象其中一部分的統計特性與其它部分是接近的。這也意味著這一部分學習的特徵也能用在另一部分上,能使用同樣的學習特徵。因此,在區域性連線中隱藏層的每一個神經元連線的區域性影象的權值引數(例如5×5),將這些權值引數共享給其它剩下的神經元使用,那麼此時不管隱藏層有多少個神經元,需要訓練的引數就是這個區域性影象的許可權引數(例如5×5),也就是卷積核的大小,這樣大大減少了訓練引數。如下圖
3、池化
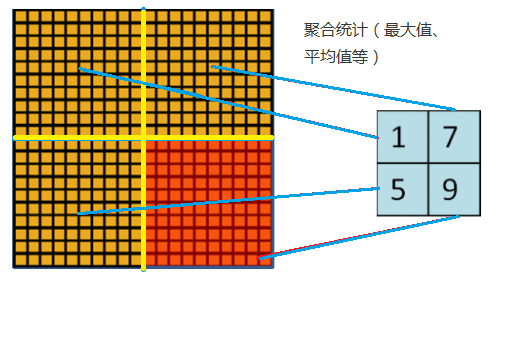
隨著模型網路不斷加深,卷積核越來越多,要訓練的引數還是很多,而且直接拿卷積核提取的特徵直接訓練也容易出現過擬合的現象。回想一下,之所以對影象使用卷積提取特徵是因為影象具有一種“靜態性”的屬性,因此,一個很自然的想法就是對不同位置區域提取出有代表性的特徵(進行聚合統計,例如最大值、平均值等),這種聚合的操作就叫做池化,池化的過程通常也被稱為特徵對映的過程(特徵降維),如下圖:
回顧了卷積神經網路(CNN)上面的三個特點後,下面來介紹一下CNN的經典模型:手寫字型識別模型LeNet5。
LeNet5誕生於1994年,是最早的卷積神經網路之一, 由Yann LeCun完成,推動了深度學習領域的發展。在那時候,沒有GPU幫助訓練模型,甚至CPU的速度也很慢,因此,LeNet5通過巧妙的設計,利用卷積、引數共享、池化等操作提取特徵,避免了大量的計算成本,最後再使用全連線神經網路進行分類識別,這個網路也是最近大量神經網路架構的起點,給這個領域帶來了許多靈感。
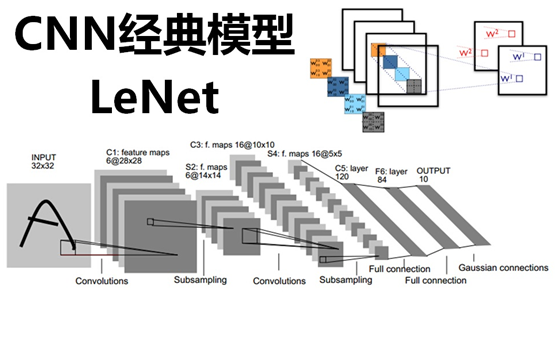
LeNet5的網路結構示意圖如下所示:
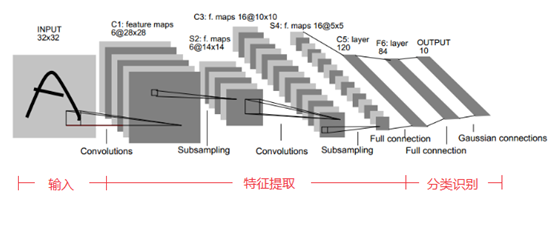
LeNet5由7層CNN(不包含輸入層)組成,上圖中輸入的原始影象大小是32×32畫素,卷積層用Ci表示,子取樣層(pooling,池化)用Si表示,全連線層用Fi表示。下面逐層介紹其作用和示意圖上方的數字含義。
1、C1層(卷積層):
該層使用了6個卷積核,每個卷積核的大小為5×5,這樣就得到了6個feature map(特徵圖)。
(1)特徵圖大小
每個卷積核(5×5)與原始的輸入影象(32×32)進行卷積,這樣得到的feature map(特徵圖)大小為(32-5+1)×(32-5+1)= 28×28
卷積過程如下圖所示:
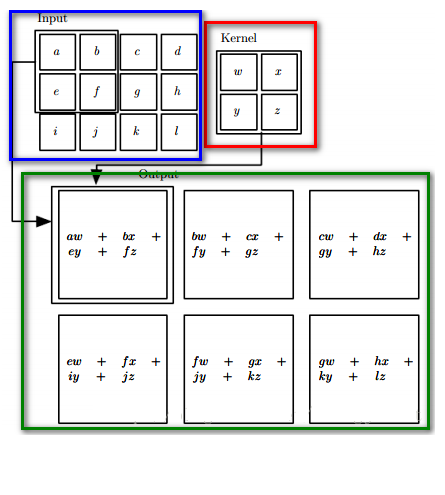
卷積核與輸入影象按卷積核大小逐個區域進行匹配計算,匹配後原始輸入影象的尺寸將變小,因為邊緣部分卷積核無法越出界,只能匹配一次,如上圖,匹配計算後的尺寸變為Cr×Cc=(Ir-Kr+1)×(Ic-Kc+1),其中Cr、Cc,Ir、Ic,Kr、Kc分別表示卷積後結果影象、輸入影象、卷積核的行列大小。
(2)引數個數
由於引數(權值)共享的原因,對於同個卷積核每個神經元均使用相同的引數,因此,引數個數為(5×5+1)×6= 156,其中5×5為卷積核引數,1為偏置引數
(3)連線數
卷積後的影象大小為28×28,因此每個特徵圖有28×28個神經元,每個卷積核引數為(5×5+1)×6,因此,該層的連線數為(5×5+1)×6×28×28=122304
2、S2層(下采樣層,也稱池化層):[email protected]×14
(1)特徵圖大小
這一層主要是做池化或者特徵對映(特徵降維),池化單元為2×2,因此,6個特徵圖的大小經池化後即變為14×14。回顧本文剛開始講到的池化操作,池化單元之間沒有重疊,在池化區域內進行聚合統計後得到新的特徵值,因此經2×2池化後,每兩行兩列重新算出一個特徵值出來,相當於影象大小減半,因此卷積後的28×28影象經2×2池化後就變為14×14。
這一層的計算過程是:2×2 單元裡的值相加,然後再乘以訓練引數w,再加上一個偏置引數b(每一個特徵圖共享相同的w和b),然後取sigmoid值(S函式:0-1區間),作為對應的該單元的值。卷積操作與池化的示意圖如下:
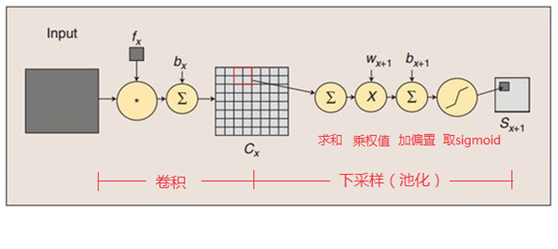
(2)引數個數
S2層由於每個特徵圖都共享相同的w和b這兩個引數,因此需要2×6=12個引數
(3)連線數
下采樣之後的影象大小為14×14,因此S2層的每個特徵圖有14×14個神經元,每個池化單元連線數為2×2+1(1為偏置量),因此,該層的連線數為(2×2+1)×14×14×6 = 5880
3、C3層(卷積層):[email protected]×10
C3層有16個卷積核,卷積模板大小為5×5。
(1)特徵圖大小
與C1層的分析類似,C3層的特徵圖大小為(14-5+1)×(14-5+1)= 10×10
(2)引數個數
需要注意的是,C3與S2並不是全連線而是部分連線,有些是C3連線到S2三層、有些四層、甚至達到6層,通過這種方式提取更多特徵,連線的規則如下表所示:
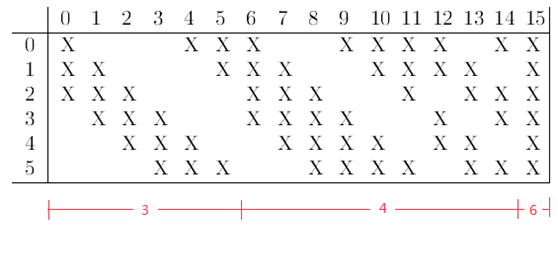
例如第一列表示C3層的第0個特徵圖(feature map)只跟S2層的第0、1和2這三個feature maps相連線,計算過程為:用3個卷積模板分別與S2層的3個feature maps進行卷積,然後將卷積的結果相加求和,再加上一個偏置,再取sigmoid得出卷積後對應的feature map了。其它列也是類似(有些是3個卷積模板,有些是4個,有些是6個)。因此,C3層的引數數目為(5×5×3+1)×6 +(5×5×4+1)×9 +5×5×6+1 = 1516
(3)連線數
卷積後的特徵圖大小為10×10,引數數量為1516,因此連線數為1516×10×10= 151600
4、S4(下采樣層,也稱池化層):[email protected]×5
(1)特徵圖大小
與S2的分析類似,池化單元大小為2×2,因此,該層與C3一樣共有16個特徵圖,每個特徵圖的大小為5×5。
(2)引數數量
與S2的計算類似,所需要引數個數為16×2 = 32
(3)連線數
連線數為(2×2+1)×5×5×16 = 2000
5、C5層(卷積層):120
(1)特徵圖大小
該層有120個卷積核,每個卷積核的大小仍為5×5,因此有120個特徵圖。由於S4層的大小為5×5,而該層的卷積核大小也是5×5,因此特徵圖大小為(5-5+1)×(5-5+1)= 1×1。這樣該層就剛好變成了全連線,這只是巧合,如果原始輸入的影象比較大,則該層就不是全連線了。
(2)引數個數
與前面的分析類似,本層的引數數目為120×(5×5×16+1) = 48120
(3)連線數
由於該層的特徵圖大小剛好為1×1,因此連線數為48120×1×1=48120
6、F6層(全連線層):84
(1)特徵圖大小
F6層有84個單元,之所以選這個數字的原因是來自於輸出層的設計,對應於一個7×12的位元圖,如下圖所示,-1表示白色,1表示黑色,這樣每個符號的位元圖的黑白色就對應於一個編碼。

該層有84個特徵圖,特徵圖大小與C5一樣都是1×1,與C5層全連線。
(2)引數個數
由於是全連線,引數數量為(120+1)×84=10164。跟經典神經網路一樣,F6層計算輸入向量和權重向量之間的點積,再加上一個偏置,然後將其傳遞給sigmoid函式得出結果。
(3)連線數
由於是全連線,連線數與引數數量一樣,也是10164。
7、OUTPUT層(輸出層):10
Output層也是全連線層,共有10個節點,分別代表數字0到9。如果第i個節點的值為0,則表示網路識別的結果是數字i。
(1)特徵圖大小
該層採用徑向基函式(RBF)的網路連線方式,假設x是上一層的輸入,y是RBF的輸出,則RBF輸出的計算方式是:
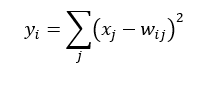
上式中的Wij的值由i的位元圖編碼確定,i從0到9,j取值從0到7×12-1。RBF輸出的值越接近於0,表示當前網路輸入的識別結果與字元i越接近。
(2)引數個數
由於是全連線,引數個數為84×10=840
(3)連線數
由於是全連線,連線數與引數個數一樣,也是840
通過以上介紹,已經瞭解了LeNet各層網路的結構、特徵圖大小、引數數量、連線數量等資訊,下圖是識別數字3的過程,可對照上面介紹各個層的功能進行一一回顧: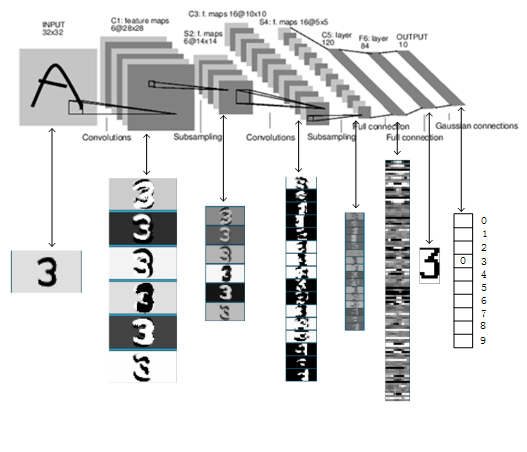
轉載地址:https://my.oschina.net/u/876354/blog/1632862