
資料結構圖文解析之:二分查詢及與其相關的幾個問題解析
0. 資料結構圖文解析系列
1. 二分查詢簡介
二分查詢大家都不陌生,可以說除了最簡單的順序查詢之外,我們第二個接觸的查詢演算法就是二分查找了。順序查詢的時間複雜度是O(n),二分查詢的時間複雜度為O(logn)。在面試中二分查詢被考察的概率還是比較高的,上次去面試時就遇到手寫二分查詢的題目。二分查詢不難,但我們要能做到準確、快速地寫出二分查詢的程式碼,能對二分查詢的效率做出分析,還能夠將二分查詢的思想來解決其他的問題。
1.1 二分查詢過程圖解
二分查詢要求序列本身是有序的。因此對於無序的序列,我們要先對其進行排序。現在我們手頭有一有序序列:
array[10] = {2,4,5,7,,8,9,13,23,34,45},則二分查詢的過程為:
- 設定三個索引:start指向陣列待查範圍的起始元素,end指向陣列待查範圍的最後一個元素,middle=(start+end)/2。開始時待查範圍為整個陣列。
- 比較array[middle]與查詢元素的大小關係:
- 如果array[middle]等於查詢元素,則查詢成功
- 如果array[middle]大於查詢元素,則說明待查元素在陣列的前半部分,此時縮小待查範圍,令end = middle-1
- 如果array[middle]小於查詢元素,則說明待查元素在陣列的後半部分,此時縮小待查範圍,令start = middle +1
- 重複執行前面兩步,直到array[middle ] 等於查詢元素則查詢成功或start>end查詢失敗。
現在我們在陣列{2,4,5,7,,8,9,13,23,34,45}中查詢元素23,過程如圖:
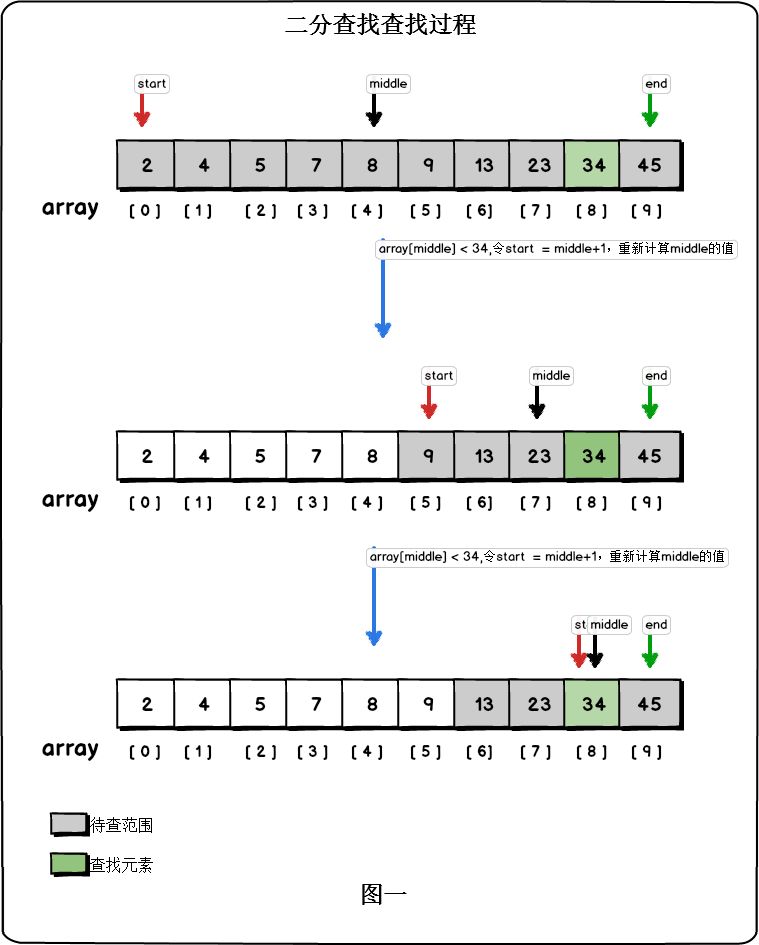
可見,每一次元素比較都可以把待查範圍縮小1/2,因此二分查詢的時間複雜度為o(logn)。
1.2 二分查詢實現程式碼
二分查詢程式碼簡單,可以遞迴或迭代地實現。遞迴容易實現,程式碼簡單,但待查元素數量巨大時,遞迴深度也隨之增大(logn的關係),應考慮是否會發生棧溢位。迭代的實現也不復雜,但我們力求準確簡潔。
遞迴實現
//查詢成功時返回查詢元素在陣列中的下標;查詢失敗時返回-1 template <typename T> int BinarySearch(const T array[], int start, int end, const T& value) { if (start>end) return -1; int middle = (start + end) / 2; if (array[middle] == value) return middle; if (array[middle] < value) { return BinarySearch(array, middle+1, end, value); } return BinarySearch(array, start, middle-1, value); };
迭代實現
template <typename T>
int BinarySearch(const T array[], int start, int end, const T& value)
{
int result = -1;
while (start <= end)
{
int middle = (start + end) / 2;
if (array[middle] == value)
{
result = middle;
break;
}
if (array[middle] < value)
{
start = middle + 1;
}
else
end = middle - 1;
}
return result;
}測試
為了方便使用者使用,我們定義一個介面:
//使用者使用介面
template <typename T>
int BinarySearch(const T array[], int length, const T& value)
{
if (array == nullptr || length <= 0)
return -1;
return BinarySearch(array, 0, length - 1, value);
}使用例項:
int _tmain(int argc, _TCHAR* argv[])
{
int array[10] = { 2, 4, 5, 7, 8, 9, 13, 23, 34, 45 };
int i;
while (cin >> i)
{
cout << BinarySearch(array, 10, i) << endl;
}
return 0;
}2. 二分查詢的應用
2.1 二分插入排序
這是對直接插入排序的一種優化策略,能夠有效減少插入排序的比較次數。
直接插入排序的思路是對於無序序列的第一個元素,從後至前進行順序查詢 掃描有序序列尋找合適的插入點。改進後的二分插入排序演算法使用二分查詢在有序序列中查詢插入點,將插入排序的比較次數降為O(log2n)。這個思路的實現程式碼為:
/*二分查詢函式,返回插入下標*/
template <typename T>
int BinarySearch(T array[], int start, int end, T k)
{
while (start <= end)
{
int middle = (start + end) / 2;
int middleData = array[middle];
if (middleData > k)
{
end = middle - 1;
}
else
start = middle + 1;
}
return start;
}
//二叉查詢插入排序
template <typename T>
void InsertSort(T array[], int length)
{
if (array == nullptr || length < 0)
return;
int i, j;
for (i = 1; i < length; i++)
{
if (array[i]<array[i - 1])
{
int temp = array[i];
int insertIndex = BinarySearch(array, 0,i, array[i]);//使用二分查詢在有序序列中進行查詢,獲取插入下標
for (j = i - 1; j>=insertIndex; j--) //移動元素
{
array[j + 1] = array[j];
}
array[insertIndex] = temp; //插入元素
}
}
}2.2 旋轉陣列的最小數字問題
問題描述:把一個數組最開始的若干個元素搬到陣列的末尾,我們稱為陣列的旋轉,輸入一個遞增排序陣列的一個旋轉,輸出旋轉陣列的最小元素。例如陣列{4,5,6,1,2,3}為陣列 {1,2,3,4,5,6}的一個旋轉,最小旋轉元素為1.
解決思路:
尋找陣列中最小的元素,我們可以遍歷陣列,時間複雜度為O(n)。但是藉助二分查詢的思想,我們能夠在O(logn)的時間複雜度內找到最小的元素。旋轉陣列的特點是陣列中兩個部分都分別是有序的,以{4,5,6,1,2,3}為例,{4,5,6}是非遞減的,{1,2,3}也是非遞減的:
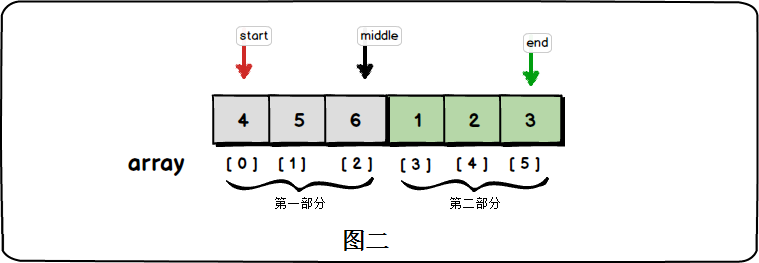
我們可以定義兩個索引:start指向第一部分的起始位置;end指向第二部分的最後一個元素,如圖所示。由於陣列在旋轉前整體有序,故array[start]>=array[end],而中間值array[middle]滿足:
- 如果array[middle]>array[start] ,則array[middle]屬於第一部分。此時令start= middle ;
- 如果array[middle]<array[start] ,則array[middle]屬於第二部分。此時令end = middle ;
迴圈執行上述操作,當start與end相鄰時,end所指便是陣列中的最小元素:
end所指元素便是最小元素。
這個定址的過程有一個隱喻的要求:中間這個元素必須能夠判斷它是屬於第一部分還是第二部分。在有些輸入下,這個要求不能滿足,例如陣列:{0,1,1,1,1},它的兩個選擇陣列為:
- {1,0,1,1,1}
- {1,1,1,0,1}
此時因array[middle] == array[start] == array[end] 而無法判斷array[middle]屬於哪一部分,我們只能進行順序查詢找出最小元素。
如圖:

此時無法確定array[middle]是屬於第一部分還是第二部分,這種情況下我們需要進行順序查詢。
因此,我們的程式碼實現為:
//順序查詢函式
int Min(int array[], int length)
{
int result = array[0];
for (int i = 1; i < length; i++)
{
if (array[i] < result)
result = array[i];
}
return result;
}
int MinInRotation(int array[],int length)
{
int result = -999;
if (array == nullptr || length < 0)
return result;
int start = 0;
int end = length - 1;
int middle = start;
while (start < end)
{
if (start + 1 == end)
{
result = array[end];
break;
}
middle = (start + end)/2;
//如果遇上特殊情況,則需要進行順序查詢
if (array[middle] == array[start] && array[middle] == array[end])
return Min(array,length); //呼叫順序查詢函式
//否則;中間元素屬於第一部分
if (array[middle]>=array[start])
{
start = middle;
}//中間元素屬於第二部分
else if (array[middle] <= array[start])
{
end = middle;
}
}
return result;
}測試程式碼:
int _tmain(int argc, _TCHAR* argv[])
{
int array1[6] = { 4, 5, 6, 1, 2, 3 };
int array2[5] = { 1, 0, 1, 1, 1 };
int array3[5] = { 1, 1, 1, 0, 1 };
cout << MinInRotation(array1, 6)<<endl;
cout << MinInRotation(array2, 5) << endl;
cout << MinInRotation(array3, 5) << endl;
getchar();
return 0;
}執行結果:
1
0
02.3 數字在排序陣列中出現次數問題
問題描述:統計一個數組在排序陣列中出現的次數。例如輸入排序陣列{1,2,3,3,3,3,4,5}和數字3,由於3在陣列中出現了4次,因此輸出4.
解決思路:假設我們是統計數字k在排序陣列中出現的次數,只要找出排序陣列中第一個k與最後一個k的下標,就能夠計算出k的出現次數。
尋找第一個k時,利用二分查詢的思想,我們總是拿k與陣列的中間元素進行比較。如果中間元素比k大,那麼第一個k只有可能出現在陣列的前半段;如果中間元素等於k,我們就需要判斷k是否是前半段的第一個k,如果k前面的元素不等於k,那麼說明這是第一個k;如果k前面的元素依舊是k,那麼說明第一個k在陣列的前半段中,我們要繼續遞迴查詢。
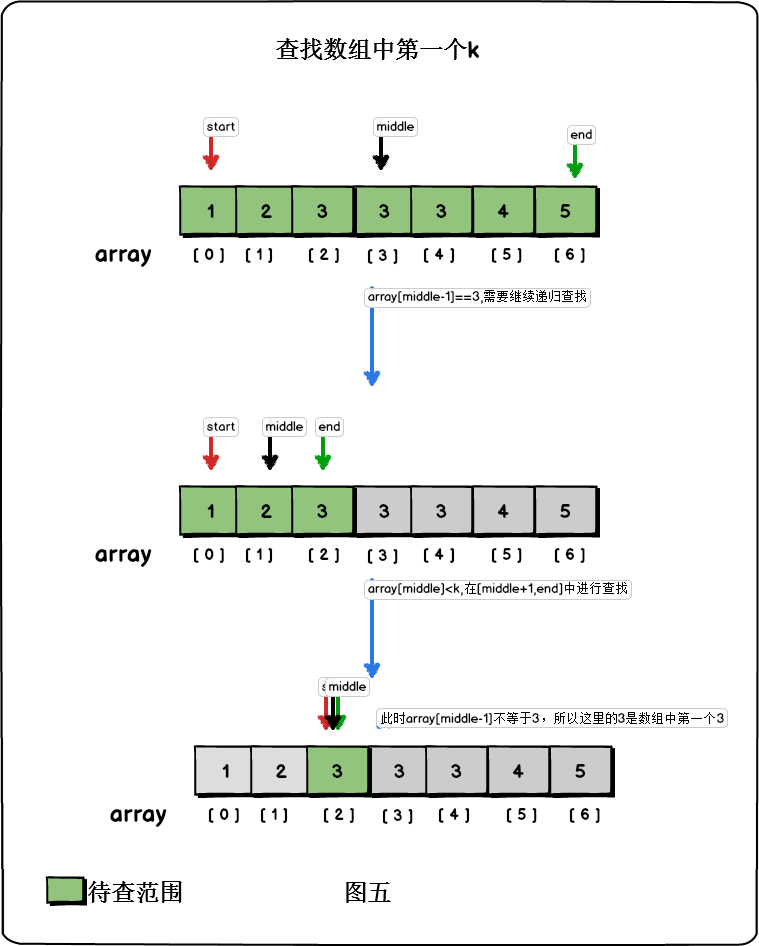
這個過程的程式碼:
int getFirstIndex(int array[], int start ,int end, int k)
{
if (start > end)
return -1;
int middle = (start + end) / 2;
int middleData = array[middle];
if (middleData == k)
{
if (middle == 0 || array[middle - 1] != k)
return middle;
else
end = middle - 1;
}
else if (middleData>k)
{
end = middle - 1;
}
else
start = middle + 1;
return getFirstIndex(array, start, end, k);
}同樣的思路,我們在陣列中尋找最後一個k,如果中間元素比K大,那麼k只能出現在陣列的後半段;如果中間元素比K小,那麼K只能出現在陣列的前半段。如果中間元素等於k,而k後面的元素等於k,那麼最後一個k只能在後半段出現;否則k為陣列中最後的一個k。
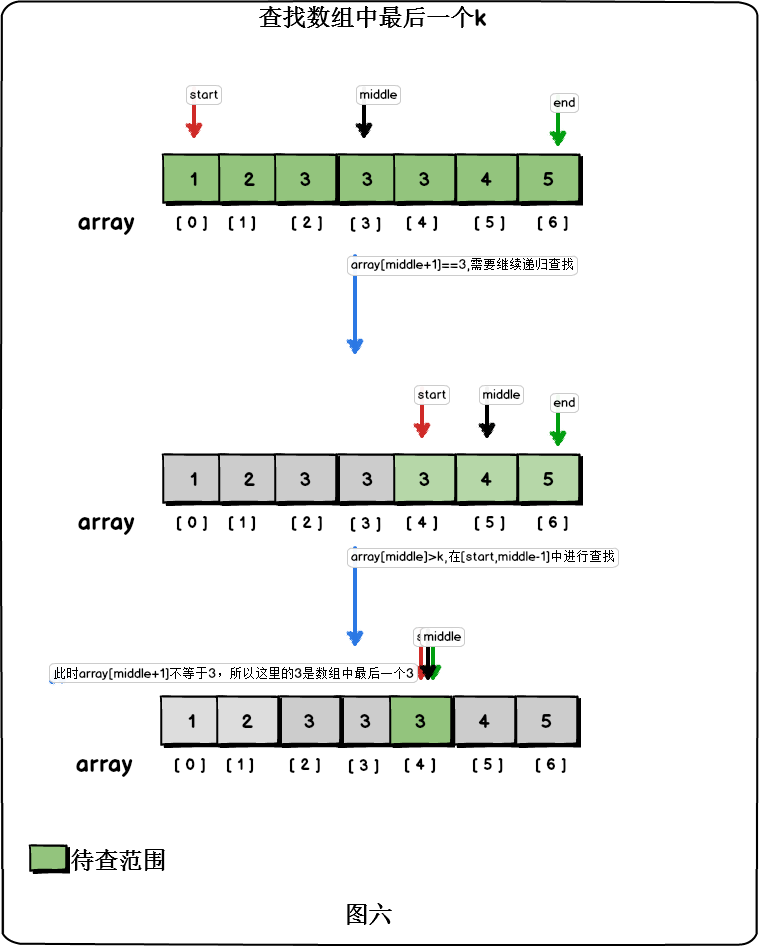
程式碼如下:
///獲取最後一個K的下標
int getLastIndex(int array[], int start,int end,int length, int k)
{
if (start > end)
return -1;
int middle = (start + end) / 2;
int middleData = array[middle];
if (middleData == k)
{
if (middle == length-1 || array[middle+ 1] != k) //最後一個k
return middle;
else
start = middle + 1;
}
else if (middleData>k)
{
end = middle - 1;
}
else
start = middle + 1;
return getLastIndex(array, start, end,length, k);
}把第一個座標與最後一個座標算出來後,我們可以進行元素出現次數的計算:
//計算元素出現個數
int CountKInArray(int array[], int length, int k)
{
int result=-1;
if (array != nullptr && length > 0)
{
int firstPos = getFirstIndex(array, 0, length - 1, k);
int lastPos = getLastIndex(array, 0, length - 1, length, k);
if (firstPos != -1 && lastPos != -1)
{
result = lastPos - firstPos+1;
}
}
return result;
}測試:
int _tmain(int argc, _TCHAR* argv[])
{
int array[8] = { 1, 2, 3, 3, 3, 4, 5 };
cout << "陣列array中數字3出現的次數為:"<<CountKInArray(array, 7, 3) << endl;
getchar();
return 0;
}執行結果:
陣列array中數字3出現的次數為:3相關推薦
資料結構圖文解析之:二分查詢及與其相關的幾個問題解析
0. 資料結構圖文解析系列 1. 二分查詢簡介 二分查詢大家都不陌生,可以說除了最簡單的順序查詢之外,我們第二個接觸的查詢演算法就是二分查找了。順序查詢的時間複雜度是O(n),二分查詢的時間複雜度為O(logn)。在面試中二分查詢被考察的概率還是比較高的,上次去面試時就遇到手寫二分查詢的題目。二分查詢不難,
資料結構與演算法基礎-01-二分查詢
二分查詢 注:本題目源自《浙江大學-資料結構》課程,題目要求實現二分查詢演算法。 函式介面定義 Position BinarySearch( List L, ElementType X ); 其中List結構定義如下: typedef int Position; typ
資料結構與演算法基礎-02-二分查詢-實踐
演算法中查詢演算法和排序演算法可謂是最重要的兩種演算法,是其他高階演算法的基礎。在此係列文章中,將逐一學習和總結這兩種基礎演算法中常見的演算法實現。首先,第一種演算法——二分(折半)查詢的學習和練習。 1、概念 二分查詢,是逐次將查詢範圍折半,縮小搜尋的範圍,直到找到那個需要的結果。
資料結構實現 3.1:二分搜尋樹(C++版)
資料結構實現 3.1:二分搜尋樹(C++版) 1. 概念及基本框架 2. 基本操作程式實現 2.1 增加操作 2.2 刪除操作 2.3 查詢操作 2.4 遍歷操作 2.5 其他操作 3. 演算法複雜度分
玩轉資料結構——第五章:二分搜尋樹
內容概要: 為什麼要研究樹結構 二分搜尋樹基礎 向二分搜尋樹中新增元素 改進新增操作:深入理解遞迴終止條件 二分搜尋樹的查詢操作 二手搜尋樹的前序遍歷 二分搜尋樹的中序遍歷和後序遍歷 深入理解二分搜尋樹的前中後遍歷(深度遍歷) 二分搜尋樹是的
資料結構學習筆記四(二分查詢)
一、什麼是二分查詢 二分查詢針對的是一個有序的資料集合,每次都通過更區間的中間元素做對比,將要查詢的區間縮小為原來的一半,直到找到要查詢的元素,或者區間被縮小為0。其時間複雜度為O(logn)。
資料結構與演算法之兩種查詢方法
本節的內容: 什麼是列表查詢; 順序查詢(線性查詢); 二分查詢; 順序查詢與二分查詢比較; 執行時間; 增速問題 一:什麼是查詢 查詢:在一些資料元素中,通過一定的方法找出與給定的關鍵詞相同的資料元素的過程。 二:順序查詢(線性查詢)
資料結構與演算法總結——二叉查詢樹及其相關操作
我實現瞭如下操作 插入,查詢,刪除,最大值 樹的高度,子樹大小 二叉樹的範圍和,範圍搜尋 樹的前序,中序,後序三種遍歷 rank 前驅值 在這一版本的程式碼中,我使用了類模板將介面與實現分
java資料結構與演算法之樹基本概念及二叉樹(BinaryTree)的設計與實現
關聯文章: 樹博文總算趕上這周釋出了,上篇我們聊完了遞迴,到現在相隔算挺久了,因為樹的內容確實不少,博主寫起來也比較費時費腦,一篇也無法涵蓋樹所有內容,所以後續還會用2篇左右的博文來分析其他內容大家就持續關注吧,而本篇主要了解的知識點如下(還是蠻多
資料結構圖文解析之:直接插入排序及其優化(二分插入排序)解析及C++實現
0. 資料結構圖文解析系列 1. 插入排序簡介 插入排序是一種簡單直觀的排序演算法,它也是基於比較的排序演算法。它的工作原理是通過不斷擴張有序序列的範圍,對於未排序的資料,在已排序中從後向前掃描,找到相應的位置並插入。插入排序在實現上通常採用就地排序,因而空間複雜度為O(1)。在從後向前掃描的過程中,需要反
資料結構實驗之查詢四:二分查詢__Find
Time Limit: 30 ms Memory Limit: 65536 KiB Problem Description 在一個給定的無重複元素的遞增序列裡,查詢與給定關鍵字相同的元素,若存在則輸出找到的位置,不存在輸出-1。 Input 一組輸入資料,輸入資料第一行首先輸入兩
資料結構圖文解析之:樹的簡介及二叉排序樹C++模板實現.
閱讀目錄 0. 資料結構圖文解析系列 1. 樹的簡介 1.1 樹的特徵 1.2 樹的相關概念 2. 二叉樹簡介 2.1 二叉樹的定義 2.2 斜樹、滿二叉樹、完全二叉樹、二叉查詢樹 2
SDUT3376資料結構實驗之查詢四:二分查詢
簡單題,就不多說了,不會的對答案,或者評論也行,哈哈 #include <iostream> #include <cstring> #include <cstdio> using namespace std; int a[1000010]; int
SDUT-3376_資料結構實驗之查詢四:二分查詢
資料結構實驗之查詢四:二分查詢 Time Limit: 30 ms Memory Limit: 65536 KiB Problem Description 在一個給定的無重複元素的遞增序列裡,查詢與給定關鍵字相同的元素,若存在則輸出找到的位置,不存在輸出-1。 Input 一組輸入資料,輸入資料第一
資料結構圖文解析之:佇列詳解與C++模板實現
正文 回到頂部 0. 資料結構圖文解析系列 回到頂部 1. 佇列簡介 回到頂部 1.1 佇列的特點 佇列(Queue)與棧一樣,是一種線性儲存結構,它具有如下特點: 佇列中的資料元素遵循“先進先出”(First In First Out)的原則,簡稱FI
資料結構圖文解析之:二叉堆詳解及C++模板實現
0. 資料結構圖文解析系列 1. 二叉堆的定義 二叉堆是一種特殊的堆,二叉堆是完全二叉樹或近似完全二叉樹。二叉堆滿足堆特性:父節點的鍵值總是保持固定的序關係於任何一個子節點的鍵值,且每個節點的左子樹和右子樹都是一個二叉堆。 當父節點的鍵值總是大於或等於任何一個子節點的鍵值時為最大堆。 當父節點的鍵值總是小於
資料結構圖文解析之:陣列、單鏈表、雙鏈表介紹及C++模板實現
0. 資料結構圖文解析系列 1. 線性表簡介 線性表是一種線性結構,它是由零個或多個數據元素構成的有限序列。線性表的特徵是在一個序列中,除了頭尾元素,每個元素都有且只有一個直接前驅,有且只有一個直接後繼,而序列頭元素沒有直接前驅,序列尾元素沒有直接後繼。 資料結構中常見的線性結構有陣列、單鏈表、雙鏈表、迴圈
資料結構圖文解析之:棧的簡介及C++模板實現
0. 資料結構圖文解析系列 1. 棧的簡介 1.1棧的特點 棧(Stack)是一種線性儲存結構,它具有如下特點: 棧中的資料元素遵守”先進後出"(First In Last Out)的原則,簡稱FILO結構。 限定只能在棧頂進行插入和刪除操作。 1.2棧的相關概念 棧的相關概念: 棧頂與棧底:允許元素
資料結構圖文解析之:哈夫曼樹與哈夫曼編碼詳解及C++模板實現
0. 資料結構圖文解析系列 1. 哈夫曼編碼簡介 哈夫曼編碼(Huffman Coding)是一種編碼方式,也稱為“赫夫曼編碼”,是David A. Huffman1952年發明的一種構建極小多餘編碼的方法。 在計算機資料處理中,霍夫曼編碼使用變長編碼表對源符號進行編碼,出現頻率較高的源符號採用較短的編碼,
資料結構與演算法之美專欄學習筆記-二分查詢(下)
四種常見的二分查詢變形問題 查詢第一個值等於給定值的元素 //查詢第一個等於給定值的元素 public static int BSearch2(int[] a, int n, int value){ //定義陣列頭尾索引 int low = 0, high = n - 1;