
資料結構圖文解析之:二叉堆詳解及C++模板實現
0. 資料結構圖文解析系列
1. 二叉堆的定義
二叉堆是一種特殊的堆,二叉堆是完全二叉樹或近似完全二叉樹。二叉堆滿足堆特性:父節點的鍵值總是保持固定的序關係於任何一個子節點的鍵值,且每個節點的左子樹和右子樹都是一個二叉堆。
當父節點的鍵值總是大於或等於任何一個子節點的鍵值時為最大堆。 當父節點的鍵值總是小於或等於任何一個子節點的鍵值時為最小堆。
2. 二叉堆的儲存
二叉堆一般使用陣列來表示。請回憶一下二叉樹的性質,其中有一條性質:
性質五:如果對一棵有n個節點的完全二叉樹的節點按層序編號(從第一層開始到最下一層,每一層從左到右編號,從1開始編號),對任一節點i有:
- 如果i=1 ,則節點為根節點,沒有雙親。
- 如果2 * i > n ,則節點i沒有左孩子 ;否則其左孩子節點為2*i . (n為節點總數)
- 如果2 * i+1>n ,則節點i沒有右孩子;否則其右孩子節點為2*1+1.
簡單來說:
- 如果根節點在陣列中的位置是1,第n個位置的子節點分別在2n 與 2n+1,第n個位置的雙親節點分別在⌊i /2⌋。因此,第1個位置的子節點在2和3.
- 如果根節點在陣列中的位置是0,第n個位置的子節點分別在2n+1與2n+2,第n個位置的雙親節點分別在⌊(i-1) /2⌋。因此,第0個位置的子節點在1和2.
得益於陣列的隨機儲存能力,我們能夠很快確定堆中節點的父節點與子節點。
下面以大頂堆展示一下堆的陣列儲存。
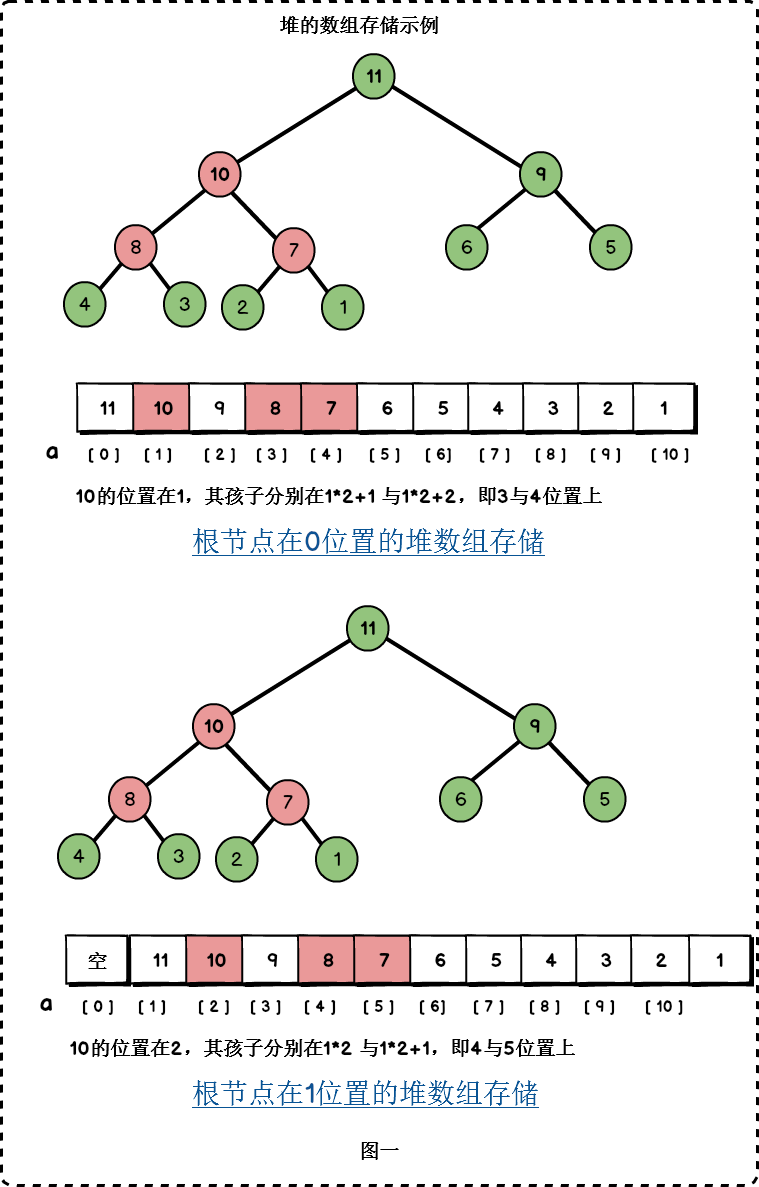
在本文中,我們以大頂堆為例進行堆的講解。本文大頂堆的根節點位置為0.
3. 二叉堆的具體實現
在二叉堆上可以進行插入節點、刪除節點、取出堆頂元素等操作。
3.1 二叉堆的抽象資料型別
/*大頂堆類定義*/ template <typename T> class MaxHeap { public: bool insert(T val); //往二叉堆中插入元素 bool remove(T data); //移除元素 void print(); //列印堆 T getTop(); //獲取堆頂元素 bool createMaxHeap(T a[], int size);//根據指定的陣列來建立一個最大堆 MaxHeap(int cap = 10); ~MaxHeap(); private: int capacity; //容量,也即是陣列的大小 int size; //堆大小,也即是陣列中有效元素的個數 T * heap; //底層的陣列 private: void filterUp(int index); //從index所在節點,往根節點調整堆 void filterDown(int begin ,int end ); //從begin所在節點開始,向end方向調整堆 };
- 注意capacity與size的區別。capacity指的是陣列的固有大小。size值陣列中有效元素的個數,有效元素為組成堆的元素。
- heap為陣列。
3.2 二叉堆的插入
在陣列的最末尾插入新節點,然後自下而上地調整子節點與父節點的位置:比較當前結點與父節點的大小,若不滿足大頂堆的性質,則交換兩節點,從而使當前子樹滿足二叉堆的性質。時間複雜度為O(logn)。
當我們在上圖的堆中插入元素12:

調整過程:
- 節點12新增在陣列尾部,位置為11;
- 節點12的雙親位置為⌊11/2⌋ = 5,即節點6;節點12比節點6大,與節點6交換位置。交換後節點12的位置為5.
- 節點12的雙親位置為⌊ 5 /2⌋ = 2,即節點9;節點12比節點9大,與節點9交換位置。交換後節點12的位置為2.
- 節點12的雙親位置為⌊2/2⌋ = 1,即節點11;節點12比節點11大,與節點11交換位置。交換後節點12的位置為1.
- 12已經到達根節點,調整過程結束。
這個從下到上的調整過程為:
/*從下到上調整堆*/
/*插入元素時候使用*/
template <typename T>
void MaxHeap<T>::filterUp(int index)
{
T value = heap[index]; //插入節點的值,圖中的12
while (index > 0) //如果還未到達根節點,繼續調整
{
int indexParent = (index -1)/ 2; //求其雙親節點
if (value< heap[indexParent])
break;
else
{
heap[index] = heap[indexParent];
index = indexParent;
}
}
heap[index] = value; //12插入最後的位置
};
在真正程式設計的時候,為了效率我們不必進行節點的交換,直接用父節點的值覆蓋子節點。最後把新節點插入它最後的位置即可。
基於這個調整函式,我們的插入函式為:
/*插入元素*/
template <typename T>
bool MaxHeap<T>::insert(T val)
{
if (size == capacity) //如果陣列已滿,則返回false
return false;
heap[size] = val;
filterUp(size);
size++;
return true;
};3.3 二叉堆的刪除
堆的刪除是這樣一個過程:用陣列最末尾節點覆蓋被刪節點,再從該節點從上到下調整二叉堆。我們刪除根節點12:

可能有人疑惑,刪除後陣列最末尾不是多了一個6嗎?
的確,但我們把陣列中有效元素的個數減少了一,最末尾的6並不是堆的組成元素。
這個從上到下的調整過程為:
/*從上到下調整堆*/
/*刪除元素時候使用*/
template<typename T>
void MaxHeap<T>::filterDown(int current,int end)
{
int child = current * 2 + 1; //當前結點的左孩子
T value = heap[current]; //儲存當前結點的值
while (child <= end)
{
if (child < end && heap[child] < heap[child+1])//選出兩個孩子中較大的孩子
child++;
if (value>heap[child]) //無須調整;調整結束
break;
else
{
heap[current] = heap[child]; //孩子節點覆蓋當前結點
current = child; //向下移動
child = child * 2 + 1;
}
}
heap[current] = value;
};基於調整函式的刪除函式:
/*刪除元素*/
template<typename T>
bool MaxHeap<T>::remove(T data)
{
if (size == 0) //如果堆是空的
return false;
int index;
for (index = 0; index < size; index++) //獲取值在陣列中的索引
{
if (heap[index] == data)
break;
}
if (index == size) //陣列中沒有該值
return false;
heap[index] = heap[size - 1]; //使用最後一個節點來代替當前結點,然後再向下調整當前結點。
filterDown(index,size--);
return true;
};3.4 其餘操作
其餘操作很簡單,不在這裡囉嗦。
/*列印大頂堆*/
template <typename T>
void MaxHeap<T>::print()
{
for (int i = 0; i < size; i++)
cout << heap[i] << " ";
};
/*獲取堆頂元素*/
template <typename T>
T MaxHeap<T>::getTop()
{
if (size != 0)
return heap[0];
};
/*根據指定的陣列來建立一個最大堆*/
template<typename T>
bool MaxHeap<T>::createMapHeap(T a[], int size)
{
if (size > capacity) // 堆的容量不足以建立
return false;
for (int i = 0; i < size; i++)
{
insert(a[i]);
}
return true;
};
4. 二叉堆程式碼測試
測試程式碼:
int _tmain(int argc, _TCHAR* argv[])
{
MaxHeap<int> heap(11);
//逐個元素構建大頂堆
for (int i = 0; i < 10; i++)
{
heap.insert(i);
}
heap.print();
cout << endl;
heap.remove(8);
heap.print();
cout << endl;
//根據指定的陣列建立大頂堆
MaxHeap<int> heap2(11);
int a[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
heap2.createMaxHeap(a, 10);
heap2.print();
getchar();
return 0;
}
執行結果:
9 8 5 6 7 1 4 0 3 2
9 7 5 6 2 1 4 0 3
10 9 6 7 8 2 5 1 4 35. 大頂堆、小頂堆完整程式碼下載
相關推薦
資料結構圖文解析之:二叉堆詳解及C++模板實現
0. 資料結構圖文解析系列 1. 二叉堆的定義 二叉堆是一種特殊的堆,二叉堆是完全二叉樹或近似完全二叉樹。二叉堆滿足堆特性:父節點的鍵值總是保持固定的序關係於任何一個子節點的鍵值,且每個節點的左子樹和右子樹都是一個二叉堆。 當父節點的鍵值總是大於或等於任何一個子節點的鍵值時為最大堆。 當父節點的鍵值總是小於
資料結構圖文解析之:樹的簡介及二叉排序樹C++模板實現.
閱讀目錄 0. 資料結構圖文解析系列 1. 樹的簡介 1.1 樹的特徵 1.2 樹的相關概念 2. 二叉樹簡介 2.1 二叉樹的定義 2.2 斜樹、滿二叉樹、完全二叉樹、二叉查詢樹 2
資料結構圖文解析之:佇列詳解與C++模板實現
正文 回到頂部 0. 資料結構圖文解析系列 回到頂部 1. 佇列簡介 回到頂部 1.1 佇列的特點 佇列(Queue)與棧一樣,是一種線性儲存結構,它具有如下特點: 佇列中的資料元素遵循“先進先出”(First In First Out)的原則,簡稱FI
資料結構圖文解析之:陣列、單鏈表、雙鏈表介紹及C++模板實現
0. 資料結構圖文解析系列 1. 線性表簡介 線性表是一種線性結構,它是由零個或多個數據元素構成的有限序列。線性表的特徵是在一個序列中,除了頭尾元素,每個元素都有且只有一個直接前驅,有且只有一個直接後繼,而序列頭元素沒有直接前驅,序列尾元素沒有直接後繼。 資料結構中常見的線性結構有陣列、單鏈表、雙鏈表、迴圈
資料結構圖文解析之:棧的簡介及C++模板實現
0. 資料結構圖文解析系列 1. 棧的簡介 1.1棧的特點 棧(Stack)是一種線性儲存結構,它具有如下特點: 棧中的資料元素遵守”先進後出"(First In Last Out)的原則,簡稱FILO結構。 限定只能在棧頂進行插入和刪除操作。 1.2棧的相關概念 棧的相關概念: 棧頂與棧底:允許元素
資料結構圖文解析之:哈夫曼樹與哈夫曼編碼詳解及C++模板實現
0. 資料結構圖文解析系列 1. 哈夫曼編碼簡介 哈夫曼編碼(Huffman Coding)是一種編碼方式,也稱為“赫夫曼編碼”,是David A. Huffman1952年發明的一種構建極小多餘編碼的方法。 在計算機資料處理中,霍夫曼編碼使用變長編碼表對源符號進行編碼,出現頻率較高的源符號採用較短的編碼,
資料結構圖文解析之:直接插入排序及其優化(二分插入排序)解析及C++實現
0. 資料結構圖文解析系列 1. 插入排序簡介 插入排序是一種簡單直觀的排序演算法,它也是基於比較的排序演算法。它的工作原理是通過不斷擴張有序序列的範圍,對於未排序的資料,在已排序中從後向前掃描,找到相應的位置並插入。插入排序在實現上通常採用就地排序,因而空間複雜度為O(1)。在從後向前掃描的過程中,需要反
資料結構圖文解析之:二分查詢及與其相關的幾個問題解析
0. 資料結構圖文解析系列 1. 二分查詢簡介 二分查詢大家都不陌生,可以說除了最簡單的順序查詢之外,我們第二個接觸的查詢演算法就是二分查找了。順序查詢的時間複雜度是O(n),二分查詢的時間複雜度為O(logn)。在面試中二分查詢被考察的概率還是比較高的,上次去面試時就遇到手寫二分查詢的題目。二分查詢不難,
java資料結構與演算法之平衡二叉樹(AVL樹)的設計與實現
關聯文章: 上一篇博文中,我們詳細地分析了樹的基本概念以及二叉查詢樹的實現過程,基於二叉查詢樹的特性,即對於樹種的每個結點T(T可能是父結點),它的左子樹中所有項的值小T中的值,而它的右子樹中所有項的值都大於T中的值。這意味著該樹所有的元素可以用某
資料結構之:AVL樹詳解及C++模板實現
AVL樹簡介AVL樹的名字來源於它的發明作者G.M. Adelson-Velsky 和 E.M. Landis。AVL樹是最先發明的自平衡二叉查詢樹(Self-Balancing Binary Search Tree,簡稱平衡二叉樹)。一棵AVL樹有如下必要條件:條件一:它必
Android版資料結構與演算法(八):二叉排序樹
本文目錄 前兩篇文章我們學習了一些樹的基本概念以及常用操作,本篇我們瞭解一下二叉樹的一種特殊形式:二叉排序樹(Binary Sort Tree),又稱二叉查詢樹(Binary Search Tree),亦稱二叉搜尋樹。 一、二叉排序樹定義 二叉排序樹或者是一顆空樹,或者是具有下列性質的二叉樹:
資料結構和演算法之美-二叉樹(上)
學習筆記 “樹”這種資料結構的形態特徵 包括有哪些命名節點和它們的概念,這些節點是根節點,葉子節點,父節點,子節點,兄弟節點等;以及相關節點關係的建立,這些關係是父子關係和兄弟關係 “樹"這種資
淺談演算法和資料結構(7):二叉查詢樹
前文介紹了符號表的兩種實現,無序連結串列和有序陣列,無序連結串列在插入的時候具有較高的靈活性,而有序陣列在查詢時具有較高的效率,本文介紹的二叉查詢樹(Binary Search Tree,BST)這一資料結構綜合了以上兩種資料結構的優點。 二叉查詢樹具有很高的靈活性
資料結構-BST、AVL、二叉堆、B樹、B+樹、紅黑樹
總結了資料結構中樹的一些常見的型別。 一、線索二叉樹 對於n個結點的二叉樹,在二叉鏈儲存結構中有n+1個空鏈域,利用這些空鏈域存放在某種遍歷次序下該結點的前驅結點和後繼結點的指標,這些指標稱為線索,加上線索的二叉樹稱為線索二叉樹。 二、二叉查詢樹(
《常見演算法和資料結構》優先佇列(2)——二叉堆
二叉堆 本系列文章主要介紹常用的演算法和資料結構的知識,記錄的是《Algorithms I/II》課程的內容,採用的是“演算法(第4版)”這本紅寶書作為學習教材的,語言是java。這本書的名
紅黑二叉樹詳解及理論分析
什麼是紅-黑二叉樹? 紅-黑二叉樹首先是一顆二叉樹,它具有二叉樹的所有性質,是一種平衡二叉樹。普通二叉樹在生成過程中,容易出現不平衡的現象,即使是使用隨機演算法生成二叉樹,也是有一定概率生成不平衡的二叉樹. 如下圖所示 :
資料結構實現 6.1:二叉堆_基於動態陣列實現(C++版)
資料結構實現 6.1:二叉堆_基於動態陣列實現(C++版) 1. 概念及基本框架 1.1 滿二叉樹 1.2 完全二叉樹 2. 基本操作程式實現 2.1 增加操作 2.2 刪除操作 2.3 查詢操作
軟考:資料結構基礎——建立順序完全二叉樹
首先是關於樹,二叉樹,完全二叉樹的一些知識 一、樹 (一)、基本概念 1. 度:一個節點的子樹的個數 &
常用資料結構與演算法:二叉堆(binary heap)
一:什麼是二叉堆 二:二叉堆的實現 三:使用二叉堆的幾個例子 一:什麼是二叉堆 1.1:二叉堆簡介 二叉堆故名思議是一種特殊的堆,二叉堆具有堆的性質(父節點的鍵值總是大於或等於(小於或等於)任何一個子節點的鍵值),二叉堆又具有二叉樹的性質(二叉堆是完全二叉樹
資料結構 樹筆記-5 線索二叉樹 以及 線索二叉連結串列
線索二叉連結串列 線索二叉連結串列 來自於 二叉連結串列。一個二叉連結串列,如果存放n個結點,就一定有n+1個空指標域,而線上索鏈 表中,就讓這n+1個空指標域有了用武之地。 空指標域 用於存放 某種遍歷順序下的 前驅或者後繼的地址。 已知 一棵二叉樹的結構: