
[珠璣之櫝]字串和序列:左移、雜湊、最長重複子序列的字尾陣列解法、最大連續子序列
字串和陣列在儲存上是類似的,把它們歸為同一主題之下。本文主要介紹三大類問題和它們衍生的問題,以及相應演算法。
本文主要介紹和討論的問題和介紹的演算法(點選跳轉):
字串迴圈移位(左旋轉)問題
問題敘述:
將一個n元一維向量向左旋轉i個位置。例如,當n=8且i=3時,"abcdefgh"旋轉為"defghabc",要求時間為O(n),額外儲存佔用為O(1)。(《程式設計珠璣》第二章問題B)
分析:
嚴格來說這並不是一個字串,因為'\0'是不會移動的。為了敘述方便,可以把它認為是字串,只是不對'\0'進行操作罷了。
如果不考慮時間要求為O(n),那麼可以每次整體左移一位,一共移動i次。只使用O(1)的空間的條件下,一共要進行元素交換O(n*i)次;
如果不考慮空間要求為O(1),那麼可以把前i個存入臨時陣列,剩下的左移i位,再把臨時數組裡的內容放入後i個位置中。
很可惜,由於兩個限制條件,以上兩種思路都不滿足要求。
對於演算法1和演算法2,如果理解有困難,不必強求,能掌握演算法3就好。
演算法1:“雜技”程式碼
為了滿足O(1)空間的限制,延續第一個思路,如果每次直接把原向量的一個元素移動到目標向量中它的應該出現新位置上就行了。先把array[0]儲存起來,然後把array[i]移動到array[0]上,array[2i]移到array[i]上,直至返回取原先的array[0]。但這需要解決的問題是,如何保證所有元素都被移動過了?數學上的結論是,依次以array[0],...,array[gcd(i,n)-1]為首元進行迴圈即可,其中gcd(a,b)是a與b的最大公約數。因此演算法可寫為:


int vec_rotate(char *vec,int rotdist, int length) { int i,j,k,times; char t; times = gcd(rotdist,length); printf("%d\n",times); for(i=0;i<times;i++) { t = vec[i]; j = i; while(1) { k = j+ rotdist; if(k>=length) k向量左旋演算法1:"雜技"程式碼-=length; if(k==i) break; vec[j] = vec[k]; j = k; } vec[j]=t; } return 0; }
正如“雜技”一詞所暗示的一樣,這個演算法就像在玩雜耍球,你要讓它們中的每一個都在合適的位置上,這些球,除了手中有一個,其它幾個都在空中。如果不熟悉,很容易手忙腳亂,把球掉的滿地都是。
演算法2:塊交換
考慮第二個思路,相當於把向量x分為兩部分a和b,左移就是把ab變成ba,其中a包含了前i個元素。假設a比b短,把b分為bl和br,那麼需要先把a與br交換得到brbla,再對brbl遞迴左旋。而a比b長的情況類似,當a與b長度相等時直接兩兩交換元素就能完成。同時可以看到,每次待交換的向量長度都小於上一次,最終遞迴結束。
int vec_rotate_v1(char *vec,int i, int length) { int j = length - i; if(i>length) i = i%length; if(j==0) return 0; else if(j>i) { //case1: ab -> a-b(l)-b(r) swap(vec,0,j,i); vec_rotate_v1(vec,i,j); } //case2: ab -> a(l)-a(r)-b //i becomes less else if(j<i) { swap(vec,i,2*i-length,j); vec_rotate_v1(vec,2*i-length,i); } else swap(vec,0,i,i); return 0; } int swap(char* vec,int p1,int p2, int n) { char temp; while(n>0) { temp = vec[p1]; vec[p1] = vec[p2]; vec[p2] = temp; p1++; p2++; n--; } return 0; }向量左旋演算法2:塊交換
這個演算法的缺陷是,需要對三種情況進行討論,而且下標稍不注意就會出錯。
演算法3:求逆(推薦)
延續演算法2的思路,並假定有一個輔助函式能對向量求逆。這樣,分別對a、b求逆得到arbr,再對整體求逆便獲得了ba!難怪作者也要稱之為“靈光一閃”的演算法。可能以前接觸過矩陣運算的讀者對此很快便能理解,因為(ATBT)T = BA。演算法如下:
int vec_rotate_v2(char *vec,int i,int length){ assert((i<=0)||(length<=0)) if(i>length) i = i%length; if (i==length) { printf("i equals n. DO NOTHING.\n"); return 0; } reverse(vec,0,i-1); reverse(vec,i,length-1); reverse(vec,0,length-1); return 1; } int reverse(char *vec,int first,int last){ char temp; while(first<last){ temp = vec[first]; vec[first] = vec[last]; vec[last] = temp; first++; last--; } return 0; }向量左旋演算法3:求逆
如果能想到,演算法3無疑既高效,也難以在編寫時出錯。有人曾主張把這個求逆的左旋方法當做一種常識。
來看看這種思想的應用吧:
擴充套件:(google面試題)用線性時間和常數附加空間將一篇文章的所有單詞倒序。
舉個例子:This is a paragraph for test
處理後: test for paragraph a is This
如果使用求逆的方式,先把全文整體求逆,再根據空格對每個單詞內部求逆,是不是很簡單?另外淘寶今年的實習生筆試有道題是類似的,處理的物件規模比這個擴充套件中的“一篇文章”小不少,當然解法是基本一樣的,只不過分隔符不是空格而已,這裡就不重述了。
以字串雜湊為例的雜湊表
關於雜湊表,這裡就不做解釋了,主要是演示一個基於雜湊表的用於單詞計數的程式。
typedef struct node *nodeptr; typedef struct node { char *word; int count; nodeptr next; } node;雜湊表中的結點
#define NHASH 29989 //在寬鬆“單詞”的定義下《聖經》裡也只有29131個不同的單詞 //與之可能數接近的質數 #define MULT 31//乘數 nodeptr bin[NHASH];引數選擇和雜湊表頭
unsigned int hash(char *p) { unsigned int h = 0; for(;*p;p++) h = MULT *h +*p; return h%NHASH; }字串常用的雜湊函式
void incword(char *s) { nodeptr p; int h= hash(s); for(p=bin[h];p!=NULL;p=p->next) if(strcmp(s,p->word)==0) { (p->count)++; return; } p = malloc(sizeof(node)); p->count = 1; p->word = malloc(strlen(s)+1); strcpy(p->word,s); p->next = bin[h]; bin[h] = p; }單詞計數函式
int main(void) { int i; nodeptr p; char buf[100]; for(i=0;i<NHASH;i++) bin[i] = NULL; while(scanf("%s",buf)!=EOF) incword(buf); for(i=0;i<NHASH;i++) for(p=bin[i];p!=NULL;p=p->next) printf("%s\t%d\n",p->word,p->count); return 0; }主程式
最長重複子序列問題的字尾陣列解法
最長重複子序列問題除了使用窮舉法,還可以使用字尾陣列和字尾樹來求解。這裡給出使用字尾陣列解決的最長重複子序列的過程,並以“banana”為例進行演示。首先寫下一個比較兩個字串從頭開始共同部分的長度的函式:
int comlen(char *p, char *q) { int i = 0; while(*p&&(*p++ == *q++)) i++; return i; }comlen
設定該程式最多處理MAXN個字元,並存放在陣列c中,a是對應的字尾陣列:
#define MAXN 5000000 char c[MAXN],*a[MAXN];
讀取輸入時,對a進行初始化:
//n是已讀入的字元數目 int input(int n) { int ch; while((ch = getchar())!=EOF) { a[n] = &c[n]; c[n++] = ch; } c[n] = 0; return n; }
這樣,對於“banana”,對應的字尾陣列為:
a[0]:banana
a[1]:anana
a[2]:nana
a[3]:ana
a[4]:na
a[5]:a
它們是"banana"的所有後綴,這也是“字尾陣列”命名原因。
如果某個長字串在陣列c中出現了兩次,那麼它必然出現在兩個不同的字尾中,更準確的說,是兩個不同字尾的同一字首。通過排序可以尋找相同的字首,排序後的字尾陣列為:
a[0]:a
a[1]:ana
a[2]:anana
a[3]:banana
a[4]:na
a[5]:nana
掃描排序後的陣列的相鄰元素就能得到最長的重複字串,本例為“ana”。
這裡做一個擴充套件:(習題16.8)如何尋找至少出現過n次的最長重複子序列?
解法是比較a[i...i+n]中第一個和最後一個的最長公共字首長度,上文是對n=1的特例。因此寫出一般化的掃描函式:
int scan(int n,int k) { int maxi=0,i; int temp,maxlen = 0; for(i=0;i<n-k;i++) { temp = comlen(a[i],a[i+k]); if(temp>maxlen) { maxlen = temp; maxi = i; } } printf("%d times the longest:%.*s\n",k,maxlen,a[maxi]); return 0; }
以及主程式:
int pstrcmp(char **p, char **q) { return strcmp(*p, *q); } int main(void) { int i,n; n = input(0); qsort(a,n,sizeof(char *),pstrcmp); printf("\n"); for(i=0;i<n;i++) printf("%s\n",a[i]); scan(n,1); scan(n,2); return 0; }
這種字尾陣列排序的方法同樣可以解兩個字串最長公共字串的問題,如習題15.6和習題15.9。
最大連續子序列
基本問題:
(《程式設計珠璣》第八章,同樣的問題見於《程式設計之美》2.14節)輸入是具有n個浮點數的向量x,輸出時輸入向量的任何連續子向量的最大和。為了避免不能處理最大和小於0的情況,這裡直接把習題8.9的處理方法拿來,將最大和初值設為一個很小的負數,這裡用NI表示。同時為了簡單起見,這裡的陣列使用int型而不是要求的浮點型表示,maxsum()用於求兩個數的最大值。
1.直接解法
最直接的方式是遍歷所有可能的連續子向量,用i和j分別表示向量的首元和最後的尾元,k表示真實的尾元:
int max_array_v1(int *array,int length) { int sum,maxsofar = NI; int i,j,k; for(i=0;i<length;i++) for(j=i;j<length;j++) { sum = 0; for(k=i;k<=j;k++) { sum += array[k]; maxsofar = maxnum(maxsofar,sum); } } return maxsofar; }
2.O(n2)的解法
第1種方法的程式碼具有顯而易見的浪費:對於一個子序列可能重複計算了多次。並且具有O(n3)的時間複雜度。其實k是多餘的,依靠首尾兩個變數i、j足以表示一個子向量。同時,j增長時,可以直接使用上一次的計算和與新增元素相加。因此改寫為:
int max_array_v2_1(int *array,int length) { int sum,maxsofar = NI; int i,j; for(i=0;i<length;i++) { sum = 0; for(j=i;j<length;j++) { sum += array[j]; maxsofar = maxnum(maxsofar,sum); } } return maxsofar; }
另外一方面,由這個避免重複計算累加和的角度出發,構造一個累加和陣列cumarr,cumarr[i]表示array[0...i]各個數的累加和,這樣,array[i...j]的和就可以用cumarr[j]-cumarr[i-1]來表示了。考慮到邊界值,令cumarr[-1]=0,(習題8.5)在C中的做法是令cumarr指向一個數組的第1個元素,cumarr = recumarr +1。有了cumarr[]就可以遍歷所有的i、j來求最大值了:
int max_array_v2_2(int *array,int length) { int sum,maxsofar; int i,j; int *realcumarr,*cumarr; realcumarr = (int *)malloc((length+1)*sizeof(int)); if(realcumarr == NULL) return -1; cumarr = realcumarr + 1; cumarr[-1] = 0; for(i=0;i<length;i++) cumarr[i] = cumarr[i-1] + array[i]; maxsofar = NI; for(i=0;i<length;i++) for(j=i;j<length;j++) { sum = cumarr[j] - cumarr[i-1]; maxsofar = maxnum(maxsofar,sum); } return maxsofar; }
雖然這個累加和陣列的解法與後面兩個相比,時間複雜度遠不是最優的,然而這種資料結構很有用,在後面會看到這一點。
3.分治法(nlogn)
分治法的基本思想是,把n個元素的向量分成兩個n/2的子向量,遞迴地解決問題再把答案合併。
分容易,合併就要花點心思了。因為對於初始大小為n的向量,它的最大連續子向量可能整體在分成的兩個子向量中之一,也可能跨越了兩個子向量。每次合併都需要計算這個跨越分界點的最大連續子向量,佔據了很大的開銷。
int max_array_v3(int *array,int l,int u) { int i,m; int lmax,rmax,sum; lmax = rmax = NI; if(l>u) return 0; else if(l == u) return maxnum(NI,array[l]); m = (l+u)/2; sum = 0; for(i=m;i>=1;i--) { sum += array[i]; lmax = maxnum(sum,lmax); } sum = 0; for(i=m+1;i<=u;i++) { sum += array[i]; rmax = maxnum(sum,rmax); } return maxnum(lmax+rmax,maxnum(max_array_v3(array,l,m),max_array_v3(array,m+1,u))); }
這種解法使我聯想到了《演算法導論》用分治法求解最近點對的問題:通過將區域劃分成兩個子區域,遞迴地求解。然而合併時更加複雜:對於左邊區域和右邊區域獲得的最近距離δ,需要找到是否存在距離小於δ的兩個點,一個在左邊區域,另一個在右邊區域。而且這兩個點都在距離分界線為δ的區域內。同時可以證明,對於這個區域的每個點,只需考慮後續的7個點即可。具體的思路和證明可以參考《演算法導論》第33.4節,這個問題也說明了對於分治法,合併是難點。雖然看上去與最大子序列的形式很像,但是合併操作要複雜得多。同時,最近點對問題在《程式設計之美》2.11節也出現了,如果沒心思去翻《演算法導論》,看看《程式設計之美》上的說明也可以。
延伸:分治法的最壞情況討論
根據合併過程,如果每次的最長子向量都恰好位於邊界,即下圖中灰色部分,兩者其中之一:
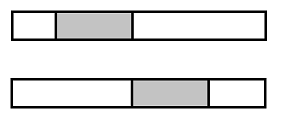
結果導致每次合併時都重複計算了在左邊和右邊的最長子向量,相當的浪費。解決方法是返回值中給出邊界,如果邊界在分界點上,合併時就不需要重複計算了。
4.掃描演算法
從頭到尾掃描陣列,掃描至array[i]時,可能的最長子向量有兩種情況:要麼在前i-1個元素中,要麼以i結尾。前者的大小記為maxsofar,後者記為maxendinghere。
int max_array_v4(int *array,int length) { int i; int maxsofar = NI; int maxendinghere = 0; for(i=0;i<length;i++) { maxendinghere = maxnum(maxendinghere + array[i],array[i]); //分析:maxendinghere必須包含array[i] //當maxendinghere>0且array[i]>0,maxendinghere更新為兩者和 //當maxendinghere>0且array[i]<0,maxendinghere更新為兩者和 //當maxendinghere<0且array[i]<0,maxendinghere更新為array[i] //當maxendinghere<0且array[i]>0,maxendinghere更新為array[i] maxsofar = maxnum(maxsofar,maxendinghere); } return maxsofar; }
這個演算法可以看做是動態規劃,把長度為n的陣列化成了遞迴的子結構,並從首開始掃描求解。時間複雜度只有O(n)。
附加討論:
Q:maxsofar的初值不設為一個很大的負數而是0會有什麼結果?
A:如果最大子向量為負數,將檢測不出來。雖然原書正文中是將初值設為0並在習題8.9給與提醒,但很容易讓人迷惑。
Q:為什麼這些演算法在處理int陣列時工作的很好,但處理float型時結果不一致?
A:這是由於浮點數的近似,當兩個浮點數的差別不大時,是可以認為它們相等的。(習題8.7)
相關問題:
1.(習題8.10)查詢總和最接近0的連續子序列,儘量用最優方法。進一步地,查詢總和最接近某一給定實數t的子向量。
分析:
延續對以上幾種方法的思路進行討論。
平方方法遍歷每對可能的i和j組成的array[i...j]是最直接的,但肯定不是最快。
對於分治法,跨越分界點的子序列總要全部遍歷一次,但是形式是類似的,雖然使用O(nlongn)能夠解決,仍並非最佳。
對於掃描演算法,如果其他不變,在更新maxendinghere時遇到了困難:在增加array[i]時,如何確定前面的幾個連續元素的去留情況?掃描演算法無法簡單地解決這個問題。
這時考慮累加和陣列的方法。對於累加和,可以看出如果array[l-1]和array[u]的值越接近,那麼array[l...u]就越近0。為了在陣列中尋找兩個最接近的數,有一個簡單方法是排序,用O(n)時間遍歷每一對相鄰元素。根據這個思路,僅僅需要把累加陣列中的結果排序遍歷一次,就能獲得結果了。但是要注意的是,如果想從排序後的陣列中獲得原向量的子向量的下標,需要比較大小,較小的是首元,較大的是尾元。
另外,考慮一般情況:查詢總和最接近某一給定實數t的子向量,我是按照平移的思想來處理的,比如t=25,那麼50到t的距離是50-t=25,-50到t的距離是-50-25=-75,把原向量做了一個變化。
#include <stdio.h> #include <stdlib.h> #define UT 32768 typedef struct ap ap; struct ap { //array plus int key; int pos; }; int comp(const void *ap1,const void *ap2){ if(((ap*)ap1)->key > ((ap*)ap2)->key) return 1; else if(((ap*)ap1)->key < ((ap*)ap2)->key) return -1; else return 0; } int rabs(int x,int n) { if(x>n) return x-n; else return n-x; } int most_close_array(int *array,int length,int n){ int i,j,k; int offset = UT; int temp; ap *realcumarr,*cumarr; realcumarr = (ap *)malloc((length+1)*(sizeof(ap))); cumarr = realcumarr + 1; (cumarr-1)->key = 0; (cumarr-1)->pos = -1; for(i=0;i<length;i++) { (cumarr+i)->key = (cumarr+i-1)->key + array[i] - n; //n for shifting to array[i] (cumarr+i)->pos = i; } qsort(cumarr,length,sizeof(ap), comp); //cumarr is in increasement order for(i=0;i<length;i++) printf("i:%d key:%d pos:%d\n",i,(cumarr+i)->key,(cumarr+i)->pos); i=j=0; for(k=0;k<length-2;k++) { //complex fix if((cumarr+k+1)->pos > (cumarr+k)->pos) { //u = (cumarr+k+1)->pos //l-1 = (cumarr+k)->pos temp = rabs((cumarr+k+1)->key - (cumarr+k)->key,n); if(temp<offset) { offset = temp; i = (cumarr+k)->pos +1; j = (cumarr+k+1)->pos; } } else { temp = rabs((cumarr+k)->key - (cumarr+k+1)->key,n); if(temp<offset) { offset = temp; i = (cumarr+k+1)->pos +1; j = (cumarr+k)->pos; } } } //[l,u] = c[u] - c[l-1] (not c[l]) printf("[%d,%d]\n",i,j); return 0; } int main(){ int n; int a[] = {31,-41,59,26,-53,58,97,-93,-23,84}; printf("please input a base:\n"); scanf("%d",&n); most_close_array(a,sizeof(a)/sizeof(int),n); return 0; }能解決一般情況下t的完整程式
2.(習題8.12)對陣列array[0...n-1]初始化為全0後,執行n次運算:for i = [l,u] {x[i] += v;},其中l,u,v是每次運算的引數,0<=l<=u<=n-1。直接用這個偽碼需要O(n2)的時間,請給出更快的演算法。
分析:
每次運算時取一個子向量進行所有元素相同的操作,那麼可以把這個子向量的開始和結尾作為操作的定界,把所有操作疊加起來一次性地完成。
即,用下面的程式碼來代替for i = [l,u] {x[i] += v;},只使用了O(n)就能完成:
for(...) {//每次迭代 cum[u]+=v; cum[l-1]-=v; } for(i=n-1;i>=0;i--) x[i] = x[i+1]+cum[i];
3.(習題8.14)給定m、n和陣列array[n],請找出使總和array[i...i+m]最接近0的整數i。(0<=i<n-m)
分析:
經過上面多次使用累加和陣列,這個應該非常簡單了。只需要計算出array[0...m],對一個i,更新sumnew = sumold- array[i-1] +array[i+m]足矣。
4.(習題8.13,同樣的問題見於《程式設計之美》2.15)求m*n實數陣列的矩形子陣列最大和。(即求矩陣最大元素和的子矩陣)
分析:
初看這個問題簡直無從下手(當然,除了暴力解法),這裡的提示是,它和之前的一維陣列中的類似問題有什麼關係?
其實這才是一維陣列求最大連續子陣列問題的最初形式,當時為了簡化分析,Ulf Grenander把二維形式轉化為一維,以深入瞭解其結構。當然這句話看上去並不是那麼合理:二維陣列壓成了一維,少了一維的資訊量,怎麼反而“深入”了呢?如果這麼理解,壓縮後只是在一個方向上變化,相當是對問題的抽象,才好理解。
有了這個啟發,嘗試把二維陣列壓縮了先。可以看出,每個子矩陣都對應一個一維陣列,下圖的灰色表示把這些元素壓縮成了一個,灰色的這一行就是當前處理的子矩陣:

同時這個壓縮有個好處:當處理的子矩陣在m維度上移動時,可以把灰色部分的元素和直接與新增的元素求和,就得到了新的子矩陣的壓縮後的灰色部分。處理灰色的等價一維陣列用前面的方式完成,這也是為什麼答案提示“在m的維度上使用演算法2,在n的維度上使用演算法4”。
int MaxSubMatrix(int m[4][4],int row,int col){ int i,j,k; int maxsofar=NI,maxendinghere; int *vec; vec = (int*)malloc(sizeof(int)*col); for(i=0;i<row;i++) { bzero(vec,sizeof(int)*col); for(j=i;j<row;j++) { maxendinghere = 0; for(k=0;k<col;k++) {//合併了 vec[k] += m[j][k]; maxendinghere = maxnum(maxendinghere + vec[k],vec[k]); maxsofar = maxnum(maxsofar,maxendinghere); } } } return maxsofar; }
答案上提到還有更快的演算法,不過提升有限,執行時間為O(n3[(loglogn)/(logn)]1/2),想必很複雜,這裡也沒有進一步研究的必要了。
到本文為止,“珠璣之櫝”系列就結束了,我已經對《程式設計珠璣》上的演算法和相關的引申問題做了一個分析和介紹,希望讀者能有所收穫,也希望能作為便於速查的資料。後續和演算法相關的博文不再使用這個字首。
往期回顧:
相關推薦
[珠璣之櫝]字串和序列:左移、雜湊、最長重複子序列的字尾陣列解法、最大連續子序列
字串和陣列在儲存上是類似的,把它們歸為同一主題之下。本文主要介紹三大類問題和它們衍生的問題,以及相應演算法。 本文主要介紹和討論的問題和介紹的演算法(點選跳轉): 字串迴圈移位(左旋轉)問題 問題敘述: 將一個n元一維向量向左旋轉i個位置。例如,當n=8且i=3時,"abcde
[珠璣之櫝]位向量/點陣圖的定義和應用
位向量/點陣圖是一個很有用的資料結構,在充分利用小空間儲存大量資料方面非常具有優勢,Linux核心中很多地方都是用了點陣圖。同時,它不但基礎,而且用到了很多程式語言的知識,以及對細節的把握,常常作為面試題出現。這裡將要介紹它的實現、操作、應用。 與點陣圖(bitmap)比,我更傾向於用位向量(bit
[珠璣之櫝]淺談程式碼正確性:迴圈不變式、斷言、debug
這個主題和程式碼的實際寫作有關,而且內容和用法相互交織,以下只是對於其內容的一個劃分。《程式設計珠璣》上只用了兩個章節20頁左右的篇幅介紹,如果希望能獲得更多的例項和技巧,我比較推崇《程式設計實踐》 (Practise of Programming)、《程式設計精粹:編寫高質量C語言程式碼》(Writin
編程之法:面試和算法心得(最大連續子數組和)
參考 否則 ++ 例子 返回 log 遍歷 方法 時間 內容全部來自編程之法:面試和算法心得一書,實現是自己寫的使用的是java 題目描述 輸入一個整形數組,數組裏有正數也有負數。數組中連續的一個或多個整數組成一個子數組,每個子數組都有一個和。 求所有子數組的和的最大值,要
hdoj1003+codeup2086:Max Sum最大連續子序列和問題解法大總結
目錄 hdoj 1003求解方法 暴力求解O(n^3)/O(n^2)(不推薦,很可能會超時) 分治法(比較複雜,掌握思想即可) 遍歷求和法O(n) dp動態規劃(強推) codeup2086的求解方法 dp求解 hdoj 1003求解方法 暴力求解
機器人學筆記之——空間描述和變換:姿態的其他描述方法
0.姿態的其他描述方法 如果你也有看機器人學導論的原書的話,可能會看到這樣一個東西:正交矩陣的凱萊公式。不知道你是怎麼樣的,反正我是一臉懵逼,有這麼個東西嗎?百度好像也找不到呀,最後還是靠谷歌和原書的參考文獻才找到這麼個東西的。 正交矩陣的凱萊公式 0.0 X-Y-Z固定角座標系
機器人學筆記之——空間描述和變換:變換方程
0. 變換方程 假設,在上圖表示的眾多關係中,只有 是未知的,所以現在我們想要將其求出來。 通過觀察發現,由{U}變換到{D}的過程其實有兩種表示方式: 第一種: 第二種: 將上面兩個式子聯立起來,我們可以得到一個新的方程: 我們可以發現,在這條新的方程中,僅有一個未知量,那麼
機器人學筆記之——空間描述和變換:變換演算法
0. 變換演算法 0.0 混合變換 在上圖的中,假設每個座標系相對於前一個座標系都是已知的,現在已知cP要求aP 既然每個座標系相對前一個座標系都是已知的,那麼就意味著我們可以根據cP倒著一步步變換成aP 首先是變換成bP: 然後再由bP變換成aP: 當然,分開寫比較不
機器人學筆記之——空間描述和變換:運算元
0. 運算元:平移、旋轉和變換 用於座標系間點的對映的通用數學表示式稱為運算元,包括點的平移運算元、旋轉運算元和平移加旋轉運算元。 0.0 平移運算元 平移將空間中的一個點沿著一個已知的向量方向移動一定距離。對空間中一點實際平移的描述僅與一個座標系有關。空間
機器人學筆記之——空間描述和變換:對映
0. 對映 在機器人學的許多問題中,都需要使用不同的參考座標系來表達同一個量,為了描述從一個座標到另一個座標的變換,機器人學引入了對映的概念。 0.0 平移座標系的對映 如下圖所示,座標系{A}和{B}的姿態是相同的,在空間中有一個點m,我們希望使用座標系{A}來表示點m,由於兩
機器人學筆記之——空間描述和變換:位置、姿態與座標系
0.空間描述:位置、姿態與座標系 0.0 位置描述: 位置描述這個沒什麼好說的,就是用矩陣的方式表示空間座標系中的向量,如上圖,在座標系{A}中有向量 aP ,其矩陣表示如下圖,其數值就是向量在當前座標系下的模長。 0.1 姿態描述: 我們可以很直觀地明白一個道理,在空間
劍指offer:動態規劃---求最大連續子序列的和
問題描述:給一個數組,返回它的最大連續子序列的和 例如:{6,-3,-2,7,-15,1,2,2},連續子向量的最大和為8(從第0個開始,到第3個為止)。 演算法思想:當全為正數的時候,問題很好解決。但是,如果陣列中包含負數,是否應該向後擴充套件某個負數,並期望負數後面的
最大連續子序列和:遞迴和動態規劃
問題描述: 給定一個整數序列,a0, a1, a2, …… , an(項可以為負數),求其中最大的子序列和。如果所有整數都是負數,那麼最大子序列和為0; 方法一: 用了三層迴圈,因為要找到這個子序列,肯定是需要起點和終點的,所以第一層迴圈確定起點,第二層迴圈確定終點,第三層
最大連續子序列和:動態規劃經典題目(2)
問題描述: 連續子序列最大和,其實就是求一個序列中連續的子序列中元素和最大的那個。 比如例如給定序列: { -2, 11, -4, 13, -5, -2 } 其最大連續子序列為{
動態規劃dp經典題目:最大連續子序列和
最大連續子序列和問題 給定k個整數的序列{N1,N2,...,Nk },其任意連續子序列可表示為{ Ni, Ni+1, ..., Nj },其中 1 <= i <= j <= k。最大連續子序列是所有連續子序中元素和最大的一個,例如給
程式設計珠璣: 15章 字串 15.2尋找字串中的最長重複子串 -------解題總結
#include <iostream> #include <stdio.h> #include <sstream> #include <stdlib.h>//qsort using namespace std; /* 問題:
“珠璣之櫝”系列簡介與索引
系列博文主要目的: 收集《程式設計珠璣》和《程式設計珠璣(續)》(以下簡稱《續》)上的演算法和思想,幷包括了一些自己的思考和對相關問題的引申,以備複習和查用。 內容提要: 主要是演算法收集,結合了《程式設計實踐》 (Practise of Programming)、《程式設計精粹:編寫高質量C語
[珠璣之櫝]隨機數函式取樣與概率
本節主要受到《程式設計珠璣》第12章隨機取樣問題的啟發,但不僅僅限於隨機取樣問題,進一步地,研究討論了一些在筆試面試中常見的和隨機函式以及概率相關的問題。 閱讀本文所需的知識: 1.對C語言中或其他語言中等價的rand()、srand()有所瞭解。本文不討論種子的設定和偽隨機數的問題;
[珠璣之櫝]二分思想與分治法、排序思想
#include <stdio.h> #include <assert.h> int BitCheck(int total,int n,int last) { FILE *input,*output0,*output1; char filename[10
[珠璣之櫝]估算的應用與Little定律
估算的資料主要依賴於所能獲得的資料和常識,有時還包括實踐而不僅僅是理論。它常常作為一個大問題中的子問題,恰當地估算可以省去精確計算的時間和開銷。在計算機領域,所謂常識的內容很寬泛,比如硬碟的傳輸速度、CPU每秒能執行多少指令、各種資料結構的大小甚至每分鐘錄入的單詞數。有些資料是能夠從各種資料中查得的,但僅