
CTC loss 理解
前言:理解了很久的CTC,每次都是點到即止,所以一直沒有很明確,現在重新整理。
定義
CTC (Connectionist Temporal Classification)是一種loss function
對比
傳統方法
在傳統的語音識別的模型中,我們對語音模型進行訓練之前,往往都要將文字與語音進行嚴格的對齊操作。這樣就有兩點不太好:
1. 嚴格對齊要花費人力、時間。
2. 嚴格對齊之後,模型預測出的label只是區域性分類的結果,而無法給出整個序列的輸出結果,往往要對預測出的label做一些後處理才可以得到我們最終想要的結果。
雖然現在已經有了一些比較成熟的開源對齊工具供大家使用,但是隨著deep learning越來越火,有人就會想,能不能讓我們的網路自己去學習對齊方式呢?因此CTC(Connectionist temporal classification)就應運而生啦。
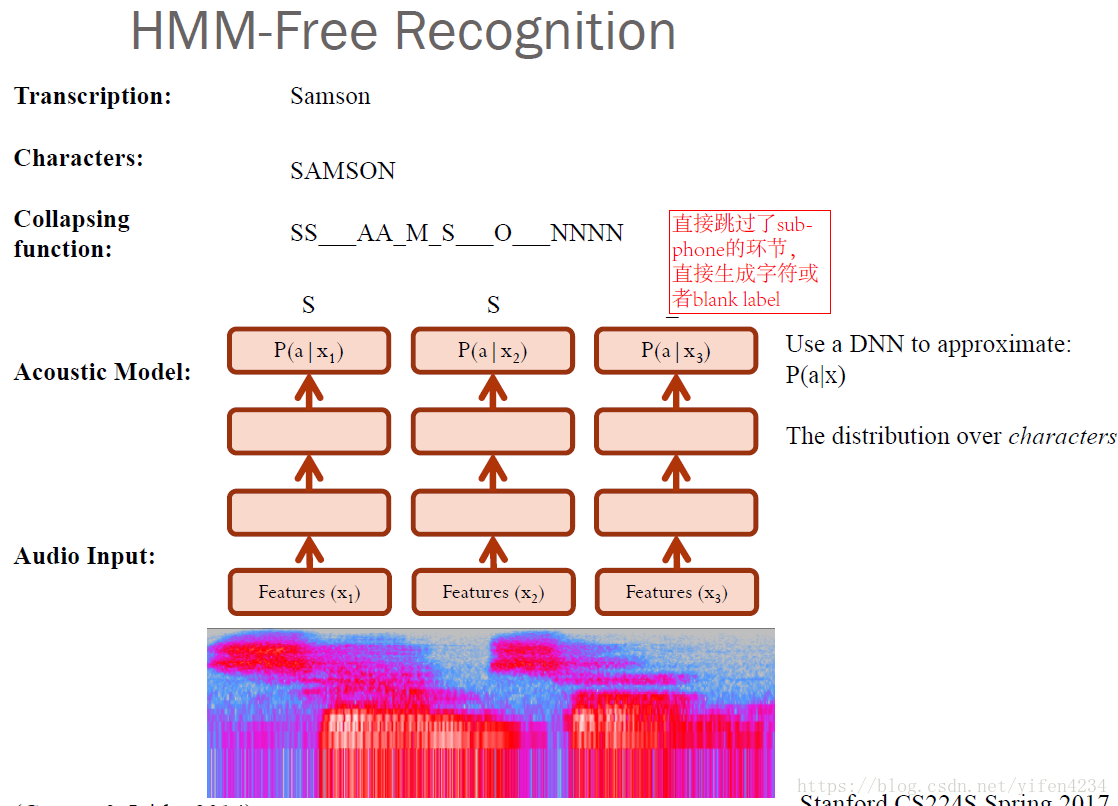
想一想,為什麼CTC就不需要去對齊語音和文字呢?因為CTC它允許我們的神經網路在任意一個時間段預測label,只有一個要求:就是輸出的序列順序只要是正確的就ok啦~這樣我們就不在需要讓文字和語音嚴格對齊了,而且CTC輸出的是整個序列標籤,因此也不需要我們再去做一些後處理操作。
對一段音訊使用CTC和使用文字對齊的例子如下圖所示:
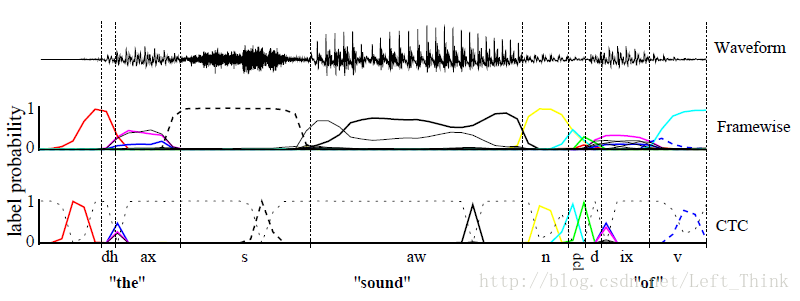
主要區別
訓練流程和傳統的神經網路類似,構建loss function,然後根據BP演算法進行訓練,不同之處在於傳統的神經網路的訓練準則是針對每幀資料,即每幀資料的訓練誤差最小,而CTC的訓練準則是基於序列(比如語音識別的一整句話)的,比如最大化 ,序列化的概率求解比較複雜,因為一個輸出序列可以對應很多的路徑,所有引入前後向演算法來簡化計算。



演算法細節
符號定義

概率計算
誤差反傳
參考文獻
實現程式碼
#coding=utf-8
import time
import 相關推薦
CTC loss 理解
前言:理解了很久的CTC,每次都是點到即止,所以一直沒有很明確,現在重新整理。 定義 CTC (Connectionist Temporal Classification)是一種loss function 對比 傳統方法 在傳統的
語音識別:深入理解CTC Loss原理
最近看了百度的Deep Speech,看到語音識別使用的損失函式是CTC loss。便整理了一下有關於CTC loss的一些定義和推導。由於個人水平有限,如果文章有錯誤,還懇請各位指出,萬分感謝~ 附上我的github主頁,歡迎各位的follow~~~
facenet:triplet-loss理解與train_tripletloss.py程式碼理解
對於Facenet進行人臉特徵提取,演算法內容較為核心和比較難以理解的地方在於三元損失函式Triplet-loss。 神經網路所要學習的目標是:使得Anchor到Positive的距離要比Anchor到Negative的距離要短(Anchor為一個樣本,Positive為與Anchor同類的
用於CTC loss的幾種解碼方法:貪心搜尋 (greedy search)、束搜尋(Beam Search)、字首束搜尋(Prefix Beam Search)
在CTC網路中我們可以訓練出一個對映: 假如序列目標為字串(詞表大小為 n),則Nw輸出為n維多項概率分佈。 網路輸出為:y=Nw,其中,表示t時刻輸出是第k項的概率。 但是這個輸出只是一組組概率,我們要由這個Nw得到我們預測的標籤,這就涉及到一個解碼的問題。 &nbs
解讀CTC LOSS原理
為什麼要使用CTC(Connectionist temporal classification): 在傳統的語音識別的聲學模型訓練中,對於每一幀的資料,我們需要知道對應的label才能進行有效的訓練,在訓練資料之前需要做語音對齊的預處理。對齊的預處理要花費大量的人力和時間,而且對齊之後,模型
YOLO loss理解
自己理解的YOLO loss 是 對於label有物體的框,不管預測有沒有,都需要計算位置(座標)損失,權重大一點。所有框都計算判別概率損失,無物體的框 權重小一點,對於label有物體的框,計算預測損失。
關於對比損失(contrasive loss)的理解(相似度越大越相似的情況):
def contro_loss(self): ''' 總結下來對比損失的特點:首先看標籤,然後標籤為1是正對,負對部分損失為0,最小化總損失就是最小化類內損失(within_loss)部分, 讓s逼近margin的過程,是個增大的過程;標籤為0
理解contrastive loss
因為最近看normL2face 看到中途發現作者其中有個創新點是對contrastive loss 和triple loss 進行了改動,由於之前只是草草的瞭解了contrastive loss ,為了更好地探究作者的創新出發點 ,看了contrastive loss 的論文 Dimensi
何愷明大神的「Focal Loss」,如何更好地理解?
轉自:http://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/78920998 作者丨蘇劍林 單位丨廣州火焰資訊科技有限公司 研究方向丨NLP,神經網路 個人主頁丨kexue.fm 前言
focal loss 兩點理解
png 感覺 技術 src 類別 com 大量 。。 ima 博客給出了三個算例。 可以看出,focal loss 對可很好分類的樣本賦予了較小的權重,但是對分錯和不易分的樣本添加了較大的權重。 對於類別不平衡,使用了$\alpha_t$進行加權,文章中提到較好的值是0
深度學習基礎--loss與啟用函式--CTC(Connectionist temporal classification)的loss
CTC(Connectionist temporal classification)的loss 用在online sequence。由於需要在分類結果中新增一個{no gesture}的類別,如果用在segmented video的分類時,需要去掉這類(因為視訊總屬於某個類)。
交叉熵在loss函式中使用的理解
交叉熵(cross entropy)是深度學習中常用的一個概念,一般用來求目標與預測值之間的差距。以前做一些分類問題的時候,沒有過多的注意,直接呼叫現成的庫,用起來也比較方便。最近開始研究起對抗生成網路(GANs),用到了交叉熵,發現自己對交叉熵的理解有些模糊,不夠深入。遂花了幾天的時間從頭梳理了一下相關
hinge loss/支援向量損失的理解
線性分類器損失函式與最優化 假設有3類 cat car frog 第一列第二行的5.1表示真實類別為cat,然後分類器判斷為car的的分數為5.1。 那這裡的這個loss怎麼去計算呢? 這裡就要介紹下SVM的損失函式,叫hinge loss。 如上圖所示,我
Focal Loss 的理解
論文:《Focal Loss for Dense Object Detection》 Focal Loss 是何愷明設計的為了解決one-stage目標檢測在訓練階段前景類和背景類極度不均衡(如1:1000)的場景的損失函式。它是由二分類交叉熵改造而來的。 標準交叉熵 其中,p是模型預測屬於類別y=
【論文理解】ArcFace: Additive Angular Margin Loss for Deep Face Recognition(InsightFace)
這篇論文基本介紹了近期較為流行的人臉識別模型,loss變化從softmax一路捋到CosFace,然後提出ArcFace,可以說起到很好的綜述作用。論文評價對比方面也做了非常詳細的對比策略方案分析。資料清洗工作也對後續研究應用有較大意義。資料和程式碼都開源,相當良心。本文主要
pytorch中網路loss傳播和引數更新理解
相比於2018年,在ICLR2019提交論文中,提及不同框架的論文數量發生了極大變化,網友發現,提及tensorflow的論文數量從2018年的228篇略微提升到了266篇,keras從42提升到56,但是pytorch的數量從87篇提升到了252篇。 TensorFlow: 228--->
Focal Loss 論文理解及公式推導
作者: Tsung-Yi, Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollar 團隊: FAIR 精度最高的目標檢測器往往基於 RCNN 的 two-stage 方法,對候選目標位置再採用
GAN的Loss的比較研究(1)——傳統GAN的Loss的理解1
GAN(Generative Adversarial Network)由兩個網路組成:Generator網路(生成網路,簡稱G)、Discriminator網路(判別網路,簡稱D),如圖: 圖1 GAN概念圖 因而有兩個Loss:Loss_D(判別網路損失函式
【論文筆記4】深入理解行人重識別網路的Loss
打完天池比賽後,可能由於長時間的持續輸出,精神上有些疲憊感,於是選擇去幹一些不是很費腦力的活兒,比如繼續充充電,看些論文補充一些理論知識。這兩天看了幾篇羅老師部落格裡總結的Person Re-Identification這塊的論文,包括羅老師自己發的兩篇論文。幾篇論文中都用到
從極大似然估計的角度理解深度學習中loss函式
從極大似然估計的角度理解深度學習中loss函式 為了理解這一概念,首先回顧下最大似然估計的概念: 最大似然估計常用於利用已知的樣本結果,反推最有可能導致這一結果產生的引數值,往往模型結果已經確定,用於反推模型中的引數.即在引數空間中選擇最有可能導致樣本結果發生的引數.因為結果已知,則某一引數使得結果產生的概率