
Trie樹 c++實現
1. Trie樹介紹
Trie,又稱單詞查詢樹、字首樹,是一種多叉樹結構。如下圖所示:
上圖是一棵Trie樹,表示了關鍵字集合{“a”, “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn”} 。
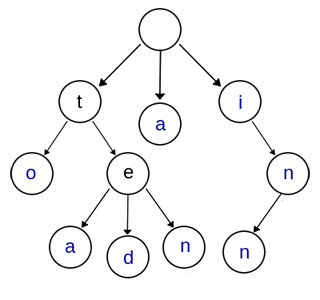
與二叉查詢樹不同,鍵不是直接儲存在節點中,而是由節點在樹中的位置決定。一個節點的所有子孫都有相同的字首,也就是這個節點對應的字串,而根節點對應空字串。
2. trie樹性質:
1.根節點不包含字元,除根節點外的每一個節點都只包含一個字元。
2.從根節點到某一節點,路徑上經過的字元連線起來,為該節點對應的字串。
3.每個節點的所有子節點包含的字元都不相同。
3. trie樹典型應用:
(1) 字串檢索
查詢某一個單詞是否在樹中。思路就是從根節點開始一個一個字元進行比較:
如果沿路比較,發現不同的字元,則表示該字串在集合中不存在。
如果所有的字元全部比較完並且全部相同,還需判斷最後一個節點的標誌位(標記該節點是否代表字串最後一個字元)。
從而trie樹可以設計為:
struct trie_node
{
bool isKey; // 標記該節點是否代表一個關鍵字
trie_node *children[26]; // 各個子節點
};
(2) 詞頻統計
Trie樹常被搜尋引擎系統用於文字詞頻統計。
思路:為了實現詞頻統計,我們可以修改節點結構,將ksKey用一個整型變數count來表示該節點為結尾的關鍵字的詞頻。對每一個關鍵字執行插入操作,若已存在,計數加1,若不存在,插入後count置1。
struct trie_node
{
int count; // 記錄該節點代表的單詞的個數
trie_node *children[26]; // 各個子節點
};
(3) 去除重複單詞
建立字典樹的過程就是給字串去重的過程。
(4) 字串排序
Trie樹可以對大量字串按字典序進行排序,思路也很簡單:遍歷一次所有關鍵字,將它們全部插入trie樹,樹的每個結點的所有兒子很顯然地按照字母表排序,然後先序遍歷輸出Trie樹中所有關鍵字即可。
(5) 最長公共字首
查詢N個單詞的最長公共字首
(6) 字首匹配:
比如要找以“an”為字首的字串
4. trie樹設計
為了計算英語字串詞頻,trie樹設計可以參考3.(2)詞頻統計。
以上設計中因為是英文字元,父節點儲存孩子節點時直接用一個數組children[26]來儲存了孩子節點。這種方式最快,但是並不是所有節點都會有很多孩子,所以這種方式浪費的空間太多。可以用一個連結串列來代替資料。這樣我們就可以省下不小的空間,但是缺點是搜尋的時候需要遍歷這個連結串列,增加了時間複雜度。如果儲存漢字,可以把連結串列代替為map,這樣既加快了速度,又不至於太浪費空間。
5. trie樹優點:
(1) 查詢快。對於長度為m的鍵值,最壞情況下只需花費O(m)的時間;而BST需要O(m log n)的時間。 雖然hash 表時間複雜度是O(1),但是,雜湊搜尋的效率通常取決於 hash 函式的好壞,若一個壞的 hash 函式導致很多的衝突,效率並不一定比Trie樹高。
(2) 當儲存大量字串時,Trie耗費的空間較少。因為鍵值並非顯式儲存的,而是與其他鍵值共享子串。
6. trie樹操作
(1) 初始化或清空:遍歷Trie,刪除所有節點,只保留根節點。
(2) 插入字串
1. 設定當前節點為根節點,設定當前字元為插入字串中的首個字元;
2. 在當前節點的子節點上搜索當前字元,若存在,則將當前節點設為值為當前字元的子節點;否則新建一個值為當前字元的子節點,並將當前結點設定為新建立的節點。
3. 將當前字元設定為串中的下個字元,若當前字元為0,則結束;否則轉2.
(3) 查詢字串
搜尋過程與插入操作類似,當字元找不到匹配時返回假;若全部字元都存在匹配,判斷最終停留的節點是否為樹葉,若是,則返回真,否則返回假。
(4) 輸出字串詞頻
(5) 刪除字串
首先查詢該字串,邊查詢邊將經過的節點壓棧,若找不到,則返回假;否則依次判斷棧頂節點是否為樹葉,若是則刪除該節點,否則返回真。
(6) 輸出字典樹所有字串
(7) 計算所有字串的詞頻總數(包含重複或不重複)
(8) 計算字典樹中所有單詞的最長公共字首及其長度
7. 實現
//使用字典樹儲存英文單詞,使用的結構是26叉字典樹。不區分單詞的大小寫
#include <cstring>
#include <iostream>
/* trie的節點型別 */
template <int Size> //Size為字元表的大小
struct trie_node
{
int freq; //當前節點是否可以作為字串的結尾,如果是freq>0,如果存在重複單詞,freq表示該單詞的詞頻
int node; //子節點的個數
trie_node *child[Size]; //指向子節點指標
/* 建構函式 */
trie_node() : freq(0), node(0) { memset(child, 0, sizeof(child)); }
};
/* trie */
template <int Size, typename Index> //Size為字元表的大小,Index為字元表的雜湊函式
class trie
{
public:
/* 定義類型別名 */
typedef trie_node<Size> node_type;
typedef trie_node<Size>* link_type;
/* 建構函式 */
trie(Index i = Index()) : index(i){ }
/* 解構函式 */
~trie() { clear(); }
/* 清空 */
void clear()
{
clear_node(root);
for (int i = 0; i < Size; ++i)
root.child[i] = 0;
}
/* 插入字串 */
template <typename Iterator>
void insert(Iterator begin, Iterator end)
{
link_type cur = &root; //當前節點設定為根節點
for (; begin != end; ++begin)
{
if (!cur->child[index[*begin]]) //若當前字元找不到匹配,則新建節點
{
cur->child[index[*begin]] = new node_type;
++cur->node; //當前節點的子節點數加一
}
cur = cur->child[index[*begin]]; //將當前節點設定為當前字元對應的子節點
}
(cur->freq)++; //設定存放最後一個字元的節點的可終止標誌為真
}
/* 插入字串,針對C風格字串的過載版本 */
void insert(const char *str)
{
insert(str, str + strlen(str));
}
/* 查詢字串,演算法和插入類似 */
template <typename Iterator>
int getfreq(Iterator begin, Iterator end)
{
link_type cur = &root;
for (; begin != end; ++begin)
{
if (!cur->child[index[*begin]])
return false;
cur = cur->child[index[*begin]];
}
return cur->freq;
}
/* 查詢字串,針對C風格字串的過載版本 */
bool find(const char *str)
{
int freq = getfreq(str, str + strlen(str));
return freq > 0;
}
/* 查詢字串str的詞頻*/
int getfreq(const char* str)
{
return getfreq(str,str + strlen(str));
}
/* 刪除字串 */
template <typename Iterator>
bool erase(Iterator begin, Iterator end)
{
bool result; //用於存放搜尋結果
erase_node(begin, end, root, result);
return result;
}
/* 刪除字串,針對C風格字串的過載版本 */
bool erase(const char *str)
{
return erase(str, str + strlen(str));
}
/* 按字典序遍歷單詞樹的所有單詞 */
template <typename Functor>
void traverse( Functor execute = Functor())
{
char word[100] = {0};
traverse_node(root, execute,word,0);
}
/*輸出字典樹單詞的總個數,包含重複字串*/
int sizeAll()
{
sizeAll(root);
}
int sizeAll(node_type& cur)
{
int size = cur.freq;
for(int i=0;i < Size; ++i)
{
if(cur.child[i] == 0)
continue;
size += sizeAll(*cur.child[i]);
}
return size;
}
/*輸出字典樹單詞的總個數,重複字串按一個處理*/
int sizeNoneRedundant()
{
sizeNoneRedundant(root);
}
int sizeNoneRedundant(node_type& cur)
{
int size = cur.freq>0?1:0;
for(int i=0;i < Size;++i)
{
if(cur.child[i] == 0)
continue;
size += sizeNoneRedundant(*cur.child[i]);
}
return size;
}
/*求字串最長的公共字首的長度*/
int maxPrefix_length()
{
int length = maxPrefix_length(root);
return length - 1; //因為length包含了根節點,需要刪除。
}
int maxPrefix_length(node_type& cur)
{
int length = 0;
for(int i=0;i<Size;++i)
{
if(cur.child[i] != 0)
{
int tmp = maxPrefix_length(*cur.child[i]);
if(tmp > length)
{
length = tmp;
}
}
}
if(length > 0 || cur.node >1 || cur.freq >0 && cur.node>0) //cur.node >1 處理"abcde"與"abcdf"這種情況;cur.freq>0 && cur.node>0處理"abcde"與"abcdef"這種情況
{
length++;
}
return length;
}
/*求字串最長的最共字首*/
void maxPrefix(std::string& prefix)
{
maxPrefix(root,prefix);
std::string word(prefix);
int size = word.size();
for(int i=0;i<size;++i)
prefix[i] = word[size-1-i];
prefix.erase(size-1); //因為prefix包含了根節點字元,需要把它刪除。
}
void maxPrefix(node_type& cur,std::string& prefix)
{
std::string word;
int length =0 ;
int k = 0;
for(int i=0;i<Size;++i)
{
if(cur.child[i] != 0)
{
maxPrefix(*cur.child[i],word);
if(word.size() > length)
{
length = word.size();
prefix.swap(word);
k = i;
}
}
}
if(length > 0 || cur.node >1 || cur.freq >0 && cur.node>0) //cur.node >1 處理"abcde"與"abcdf"這種情況;cur.freq>0 && cur.node>0處理"abcde"與"abcdef"這種情況
{
prefix.push_back(k + 'a');
}
}
private:
template<typename Functor>
void traverse_node(node_type& cur, Functor execute,char* word,int index)
{
if(cur.freq)
{
std::string str = word;
execute(str,cur.freq);
}
for(int i=0; i < Size; ++i)
{
if(cur.child[i] != 0)
{
word[index++] = 'a' + i;
traverse_node(*cur.child[i],execute,word,index);
word[index] = 0;
index--;
}
}
}
/* 清除某個節點的所有子節點 */
void clear_node(node_type& cur)
{
for (int i = 0; i < Size; ++i)
{
if (cur.child[i] == 0) continue;
clear_node(*cur.child[i]);
delete cur.child[i];
cur.child[i] = 0;
if (--cur.node == 0) break;
}
}
/* 邊搜尋邊刪除冗餘節點,返回值用於向其父節點宣告是否該刪除該節點 */
template <typename Iterator>
bool erase_node(Iterator begin, Iterator end, node_type &cur, bool &result)
{
if (begin == end) //當到達字串結尾:遞迴的終止條件
{
result = (cur.freq > 0); //如果當前節點的頻率>0,則當前節點可以作為終止字元,那麼結果為真
if(cur.freq)
cur.freq --; //如果當前節點為終止字元,詞頻減一
return cur.freq == 0 && cur.node == 0; //若該節點為樹葉,那麼通知其父節點刪除它
}
//當無法匹配當前字元時,將結果設為假並返回假,即通知其父節點不要刪除它
if (cur.child[index[*begin]] == 0) return result = false;
//判斷是否應該刪除該子節點
else if (erase_node((++begin)--, end, *(cur.child[index[*begin]]), result))
{
delete cur.child[index[*begin]]; //刪除該子節點
cur.child[index[*begin]] = 0; //子節點數減一
//若當前節點為樹葉,那麼通知其父節點刪除它
if (--cur.node == 0 && cur.freq == 0) return true;
}
return false; //其他情況都返回假
}
/* 根節點 */
node_type root;
/* 將字元轉換為索引的轉換表或函式物件 */
Index index;
};
//index function object
class IndexClass
{
public:
int operator[](const char key)
{
if(key>='a' && key <= 'z')
return key - 'a';
else if(key >= 'A' && key <= 'Z')
return key - 'A';
}
};
class StringExe
{
public:
void operator()(std::string& str,int freq)
{
std::cout<<str<<":"<<freq<<std::endl;
}
};
int main()
{
trie<26,IndexClass> t;
t.insert("tree");
t.insert("tree");
t.insert("tea");
t.insert("A");
t.insert("BABCDEGG");
t.insert("BABCDEFG");
t.traverse<StringExe>();
int sizeall = t.sizeAll();
std::cout<<"sizeAll:"<<sizeall<<std::endl;
int size = t.sizeNoneRedundant();
std::cout<<"size:"<<size<<std::endl;
std::string prefix;
int deep = t.maxPrefix_length();
t.maxPrefix(prefix);
std::cout<<"deep:"<<deep<<" prefix:"<<prefix<<std::endl;
if(t.find("tree"))
std::cout<<"find tree"<<std::endl;
else
std::cout<<"not find tree"<<std::endl;
int freq = t.getfreq("tree");
std::cout<<"tree freq:"<<freq<<std::endl;
if(t.erase("tree"))
std::cout<<"delete tree"<<std::endl;
else
std::cout<<"not find tree"<<std::endl;
freq = t.getfreq("tree");
std::cout<<"tree freq:"<<freq<<std::endl;
if(t.erase("tree"))
std::cout<<"delete tree"<<std::endl;
else
std::cout<<"not find tree"<<std::endl;
if(t.erase("tree"))
std::cout<<"delete tree"<<std::endl;
else
std::cout<<"not find tree"<<std::endl;
sizeall = t.sizeAll();
std::cout<<"sizeAll:"<<sizeall<<std::endl;
size = t.sizeNoneRedundant();
std::cout<<"size:"<<size<<std::endl;
if(t.find("tre"))
std::cout<<"find tre"<<std::endl;
else
std::cout<<"not find tre"<<std::endl;
t.traverse<StringExe>();
return 0;
}