
機器學習--線性迴歸R語言
迴歸分析就是利用樣本,產生擬合方程,從而進行預測。簡而言之,就是你用你手頭上的資料進行模型的訓練,然後用你得到的模型對於新資料進行預測。
一元線性迴歸:
例子:
y<- c(61,57,58,40,90,35,68)#weight
x<-c(170,168,175,153,185,135,172) #height
plot(x,y)
z<- lm(y~x+1)#假設y=ax+b
lines(x,fitted(z))#新增擬合值對x的散點圖並連線
coef(z)#求模型係數
formula(z)#提取模型公式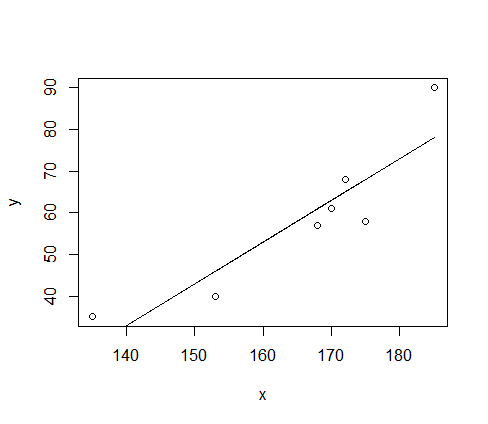
這是模型的概括
Call:
lm(formula = y ~ x + 1)
Residuals:
1 2 3 4 5 6 7 解讀上述:
Residuals:
1 2 3 4 5 6 7
-2.003 -4.002 -10.006 -5.992 11.988 7.019 2.996 這是表示殘差
1 和 -2.003表示在第一個樣本點的時候,殘差為-2.003,也就是y1-y1’為-2.003
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -107.1018 34.8642 -3.072 0.02772 *
x 1.0006 第一列代表-107.1018代表的是截距,1.0006代表斜率
第二列:推算的係數的標準差
第三列:t值
第四列:p值,是一個驗證假設是否成立的值。比如上面的身高體重模型,我假設身高height與weight無關係,也就是在原始的模型中呢,體重=常數+0*height,height前面係數為0,由此我們可以通過R算出一個統計量t值,Pr表示t值以外的面積,如果p>0.05我們就可以說拒絕原假設,也就是我們不能說height與weight無關係,為什麼這個pr>0.05呢,而不是pr>0.01或者pr>0.0001呢,這個是關於一個t分佈的面積問題吧,詳細的百度谷歌吧。
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1顯著性標記,* * * 極度顯著,* * 高度顯著,*顯著,圓點不太顯著,沒有記號不顯著
簡而言之,*越多代表效果越好
(Intercept) -107.1018
x 1.0006 表示x的係數為1.0006,截距是-107.1018,也就是身高體重的一元線性模型方程是 y = 1.0006*x-107.1018
F-statistic: 22.73 on 1 and 5 DF, p-value: 0.005024這是對整個模型的一個檢驗,原理與上面的pr差不多,都屬於假設檢驗。
用最小二乘法求解:

迴歸問題擅長於內推插值,而不擅長於外推歸納。所以在使用迴歸模型做預測時需要注意x的取值範圍
內推值:即在圖中存在的範圍之內的點
外推值:即不在圖中存在的範圍之內的點
比如說剛剛的身高/體重模型,y = 1.0006*x-107.1018 ;我要預測一個170身高的人的體重,可以擬合比較準確,這個170就是內推值。
而身高比如說是20cm,那麼體重是負數嗎?顯然不可能,那麼這個20cm就是外推值
多元線性迴歸:
顧名思義,就是自變數多了,影響因素不唯一,比如說商品銷售額,它可能跟廣告投入、市場因素、節氣變化等有關聯(我自己臆想的),所以這個時候,就會用到多元線性迴歸模型。
例子:
使用R語言內建swiss資料集,
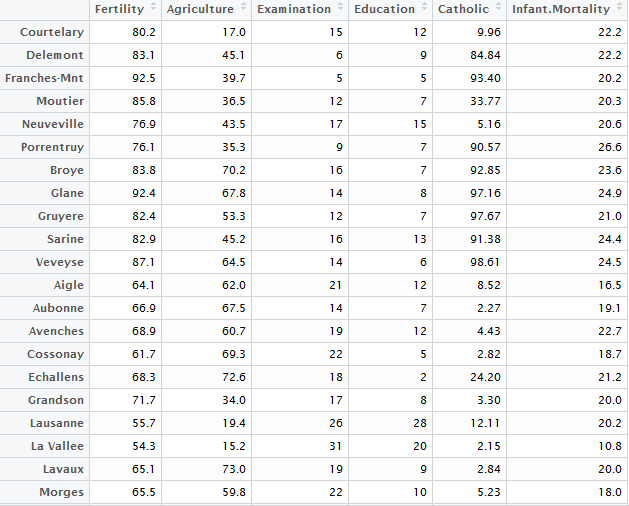
swiss資料集介紹

swiss.lm<- lm(Fertility~.,data=swiss)#Fertility是因變數,.表示因變數之外的所有列
summary(swiss.lm)
Call:
lm(formula = Fertility ~ ., data = swiss)
Residuals:
Min 1Q Median 3Q Max
-15.2743 -5.2617 0.5032 4.1198 15.3213
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 66.91518 10.70604 6.250 1.91e-07 ***
Agriculture -0.17211 0.07030 -2.448 0.01873 *
Examination -0.25801 0.25388 -1.016 0.31546
Education -0.87094 0.18303 -4.758 2.43e-05 ***
Catholic 0.10412 0.03526 2.953 0.00519 **
Infant.Mortality 1.07705 0.38172 2.822 0.00734 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 7.165 on 41 degrees of freedom
Multiple R-squared: 0.7067, Adjusted R-squared: 0.671
F-statistic: 19.76 on 5 and 41 DF, p-value: 5.594e-10注意了,我們通過觀察,Multiple R-squared: 0.7067 這個資料還行,p-value: 5.594e-10 正確的可能性很高,然後看係數時發現後面的 “ * ” 號發現 Examination後面居然沒有 “ * ” ,所以會存在隱憂,應該剔除examination
那麼問題來了,變數多了,該怎麼選擇合適的變數呢?變數與變數之間是否存在共線性?
困難:
1. 選定變數(多元),因為有時候變數太多,有些對於模型是沒有幫助甚至是倒忙,所以需要篩選。
2. 多重共線性:有些變數可以由其他變數推出來,若是存在,則會產生較大誤差
3. 檢驗模型是否合理
逐步迴歸:多元線性迴歸選擇變數的方法
- 向前引入法:從一元迴歸開始,逐步增加變數,使指標達到最優
- 向後剔除法:從全變量回歸方程開始,逐步刪去某個變數,使指標值達到最優為止
- 逐步篩選法:綜合上述兩種方法
在變數選取之前,有幾個判斷指標先介紹一下
R語言有step()函式,

step(object, scope, scale = 0,
direction = c("both", "backward", "forward"),
trace = 1, keep = NULL, steps = 1000, k = 2, ...)
具體資訊可以help一下這個函式,下面我們使用step來做direction:both表示綜合兩種方法,backward表示向後剔除,forward表示向前引入
step(object = swiss.lm,direction = "backward")#object表示模型,按照規範主要為lm(線性)或者glm(廣義線性)模型
Start: AIC=190.69
Fertility ~ Agriculture + Examination + Education + Catholic +
Infant.Mortality
Df Sum of Sq RSS AIC
- Examination 1 53.03 2158.1 189.86
<none> 2105.0 190.69
- Agriculture 1 307.72 2412.8 195.10
- Infant.Mortality 1 408.75 2513.8 197.03
- Catholic 1 447.71 2552.8 197.75
- Education 1 1162.56 3267.6 209.36
Step: AIC=189.86
Fertility ~ Agriculture + Education + Catholic + Infant.Mortality
Df Sum of Sq RSS AIC
<none> 2158.1 189.86
- Agriculture 1 264.18 2422.2 193.29
- Infant.Mortality 1 409.81 2567.9 196.03
- Catholic 1 956.57 3114.6 205.10
- Education 1 2249.97 4408.0 221.43
Call:
lm(formula = Fertility ~ Agriculture + Education + Catholic +
Infant.Mortality, data = swiss)
Coefficients:
(Intercept) Agriculture Education Catholic Infant.Mortality
62.1013 -0.1546 -0.9803 0.1247 1.0784 分析:
從上面來看,初始狀態下 Start: AIC=190.69,
模型:
Fertility ~ Agriculture + Examination + Education + Catholic + Infant.Mortality,
當剔除- Examination 1 53.03 2158.1 189.86 後,AIC=189.86
然後,step會繼續進行剔除,然而,剔除任何變數AIC都不會變小,由此得到最終模型以及相關係數
Step: AIC=189.86
Fertility ~ Agriculture + Education + Catholic + Infant.Mortality
Df Sum of Sq RSS AIC
<none> 2158.1 189.86
- Agriculture 1 264.18 2422.2 193.29
- Infant.Mortality 1 409.81 2567.9 196.03
- Catholic 1 956.57 3114.6 205.10
- Education 1 2249.97 4408.0 221.43
Call:
lm(formula = Fertility ~ Agriculture + Education + Catholic + Infant.Mortality, data = swiss)
Coefficients:
(Intercept) Agriculture Education Catholic Infant.Mortality
62.1013 -0.1546 -0.9803 0.1247 1.0784
方程:
Fertility = 62.1013*Agriculture-0.1546*Education-0.9803*Catholic+0.1247*Infant.Mortalitystep函式both自己嘗試,forward這個由於所有變數都已經在模型當中了,所以沒法使用。
除step以外,R語言中還有兩個函式可以做逐步迴歸,分別是drop1,add1
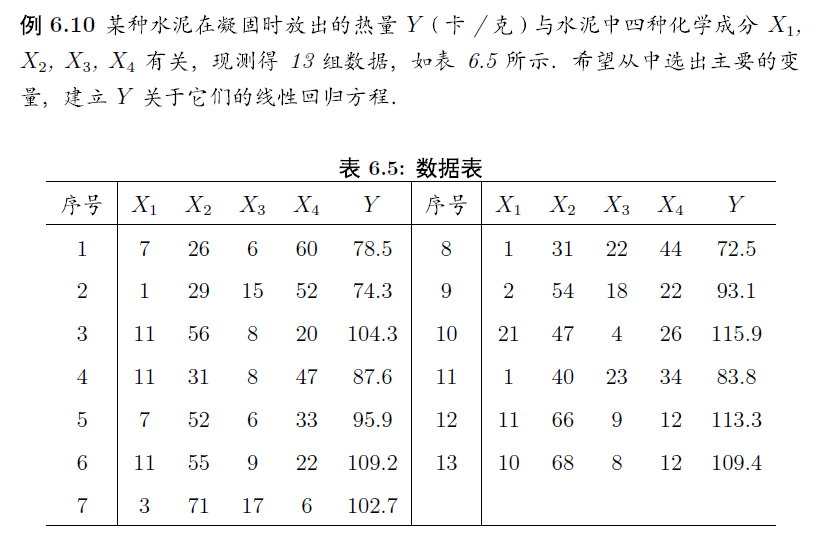
有時候,AIC準則並太適用,這裡我們使用書中的內容來說明問題





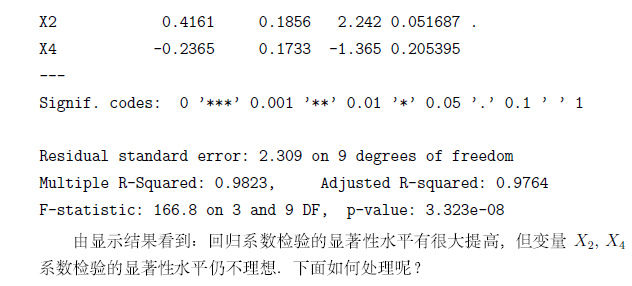



如有錯誤,請指出,謝謝!