
機器學習演算法及程式碼實現--迴歸演算法
機器學習演算法及程式碼實現–迴歸演算法
1 線性迴歸
線性迴歸假設特徵和結果滿足線性關係。其實線性關係的表達能力非常強大,每個特徵對結果的影響強弱可以由前面的引數體現,而且每個特徵變數可以首先對映到一個函式,然後再參與線性計算。這樣就可以表達特徵與結果之間的非線性關係。
假設有一個房屋銷售的資料如下:

我們可以做出一個圖,x軸是房屋的面積。y軸是房屋的售價,如下:

我們用X1,X2..Xn 去描述feature裡面的分量,比如x1=房間的面積,x2=房間的朝向,等等,我們可以做出一個估計函式:
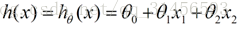
θ在這兒稱為引數,在這的意思是調整feature中每個分量的影響力,就是到底是房屋的面積更重要還是房屋的地段更重要。為了如果我們令X0 = 1,就可以用向量的方式來表示了:
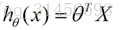
我們程式也需要一個機制去評估我們θ是否比較好,所以說需要對我們做出的h函式進行評估,一般這個函式稱為損失函式(loss function)或者錯誤函式(error function),描述h函式不好的程度,在下面,我們稱這個函式為J函式
在這兒我們可以認為錯誤函式如下:
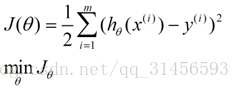
這個錯誤估計函式是去對x(i)的估計值與真實值y(i)差的平方和作為錯誤估計函式,前面乘上的1/2是為了在求導的時候,這個係數就不見了。
至於為何選擇平方和作為錯誤估計函式,講義後面從概率分佈的角度講解了該公式的來源。
如何調整θ以使得J(θ)取得最小值有很多方法,其中有最小二乘法(min square),是一種完全是數學描述的方法,和梯度下降法。
2 梯度下降法
在選定線性迴歸模型後,只需要確定引數θ,就可以將模型用來預測。然而θ需要在J(θ)最小的情況下才能確定。因此問題歸結為求極小值問題,使用梯度下降法。梯度下降法最大的問題是求得有可能是全域性極小值,這與初始點的選取有關。
梯度下降法是按下面的流程進行的:
1)首先對θ賦值,這個值可以是隨機的,也可以讓θ是一個全零的向量。
2)改變θ的值,使得J(θ)按梯度下降的方向進行減少。
梯度方向由J(θ)對θ的偏導數確定,由於求的是極小值,因此梯度方向是偏導數的反方向。結果為
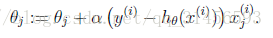
迭代更新的方式有兩種,一種是批梯度下降,也就是對全部的訓練資料求得誤差後再對θ進行更新,另外一種是增量梯度下降,每掃描一步都要對θ進行更新。前一種方法能夠不斷收斂,後一種方法結果可能不斷在收斂處徘徊。
一般來說,梯度下降法收斂速度還是比較慢的。
另一種直接計算結果的方法是最小二乘法。
3 最小二乘法
將訓練特徵表示為X矩陣,結果表示成y向量,仍然是線性迴歸模型,誤差函式不變。那麼θ可以直接由下面公式得出
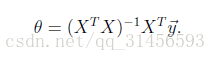
但此方法要求X是列滿秩的,而且求矩陣的逆比較慢。
4 選用誤差函式為平方和的概率解釋
假設根據特徵的預測結果與實際結果有誤差 ,那麼預測結果 和真實結果 滿足下式:
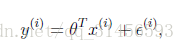
一般來講,誤差滿足平均值為0的高斯分佈,也就是正態分佈。那麼x和y的條件概率也就是
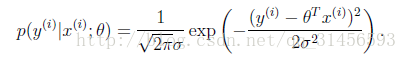
這樣就估計了一條樣本的結果概率,然而我們期待的是模型能夠在全部樣本上預測最準,也就是概率積最大。注意這裡的概率積是概率密度函式積,連續函式的概率密度函式與離散值的概率函式不同。這個概率積成為最大似然估計。我們希望在最大似然估計得到最大值時確定θ。那麼需要對最大似然估計公式求導,求導結果既是
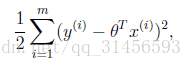
這就解釋了為何誤差函式要使用平方和。
當然推導過程中也做了一些假定,但這個假定符合客觀規律。
5 帶權重的線性迴歸
上面提到的線性迴歸的誤差函式裡系統都是1,沒有權重。帶權重的線性迴歸加入了權重資訊。
基本假設是
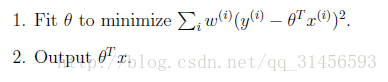
其中假設 符合公式
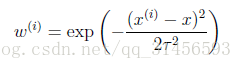
其中x是要預測的特徵,這樣假設的道理是離x越近的樣本權重越大,越遠的影響越小。這個公式與高斯分佈類似,但不一樣,因為 不是隨機變數。
此方法成為非引數學習演算法,因為誤差函式隨著預測值的不同而不同,這樣θ無法事先確定,預測一次需要臨時計算,感覺類似KNN。
6 分類和logistic迴歸
一般來說,迴歸不用在分類問題上,因為迴歸是連續型模型,而且受噪聲影響比較大。如果非要應用進入,可以使用logistic迴歸。
logistic迴歸本質上是線性迴歸,只是在特徵到結果的對映中加入了一層函式對映,即先把特徵線性求和,然後使用函式g(z)將最為假設函式來預測。g(z)可以將連續值對映到0和1上。
logistic迴歸的假設函式如下,線性迴歸假設函式只是 。
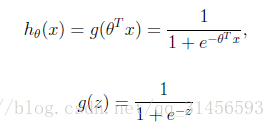
logistic迴歸用來分類0/1問題,也就是預測結果屬於0或者1的二值分類問題。這裡假設了二值滿足伯努利分佈,也就是
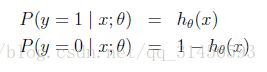
當然假設它滿足泊松分佈、指數分佈等等也可以,只是比較複雜,
仍然求的是最大似然估計,然後求導,得到迭代公式結果為
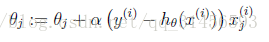
可以看到與線性迴歸類似,只是 換成了 ,而 實際上就是 經過g(z)對映過來的。
邏輯迴歸演算法實現
import numpy as np
import random
# m denotes the number of examples here, not the number of features
def gradientDescent(x, y, theta, alpha, m, numIterations):
xTrans = x.transpose()
for i in range(0, numIterations):
hypothesis = np.dot(x, theta)
loss = hypothesis - y
# avg cost per example (the 2 in 2*m doesn't really matter here.
# But to be consistent with the gradient, I include it)
cost = np.sum(loss ** 2) / (2 * m)
print("Iteration %d | Cost: %f" % (i, cost))
# avg gradient per example
gradient = np.dot(xTrans, loss) / m
# update
theta = theta - alpha * gradient
return theta
def genData(numPoints, bias, variance):
x = np.zeros(shape=(numPoints, 2))
y = np.zeros(shape=numPoints)
# basically a straight line
for i in range(0, numPoints):
# bias feature
x[i][0] = 1
x[i][1] = i
# our target variable
y[i] = (i + bias) + random.uniform(0, 1) * variance
return x, y
# gen 100 points with a bias of 25 and 10 variance as a bit of noise
x, y = genData(100, 25, 10)
m, n = np.shape(x)
numIterations= 100000
alpha = 0.0005
theta = np.ones(n)
theta = gradientDescent(x, y, theta, alpha, m, numIterations)
print(theta)