
簡易資料分析 02 | Web Scraper 的下載與安裝

這是簡易資料分析系列的第 2 篇文章。
上篇說了資料分析在生活中的重要性,從這篇開始,我們就要進入分析的實戰內容了。資料分析資料分析,沒有資料怎麼分析?所以我們首先要學會採集資料。
我調研了很多采集資料的軟體,綜合評定下來發現最好用的還是 Web Scraper,這是一款 Chrome 瀏覽器外掛。

推薦的理由有這幾個:
- 門檻足夠低,只要你電腦上安裝了 Chrome 瀏覽器就可以用
- 永久免費,無付費功能,無需註冊
- 操作簡單,點幾次滑鼠就能爬取網頁,真正意義上的 0 行程式碼寫爬蟲
既然這麼棒,當然是立馬安裝啦。
因為 Web Scraper 是 Chrome 瀏覽器外掛,我當然是首推使用 Chrome。但是限於國內的網路環境,可能訪問 Chrome 外掛應用商店不是很方便,如果第一條路走不通,我們可以嘗試第二條路,用 QQ 瀏覽器曲線救國(360 瀏覽器暫時不提供 Web Scraper 外掛)。
這兩個瀏覽器核心都是一樣的,只是介面不一樣。我後續的教程都將以 Chrome 瀏覽器為主力,QQ 瀏覽器可能會稍有一點點的不同,如果有不一樣的地方,還需讀者自行分辨差異。
1. 在 Chrome 瀏覽器上安裝 Web Scraper 外掛
1.1 安裝 Chrome 瀏覽器
這個沒啥好說的,Windows 電腦的各大應用商店都有最新版的 Chrome 瀏覽器,或者百度一下,首頁一般都會有安裝包地址,下載安裝就好;
(為了減少相容性問題,最好安裝最新版本的 Chrome 瀏覽器)
1.2 安裝 Web Scraper 外掛
可以訪問外網的同學,直接訪問"Chrome 網上應用店",搜尋 Web Scraper 下載安裝就可:

暫時無條件訪問外網,我們可以手動安裝外掛曲線救國一下,當然和上面比會稍微麻煩一些:
首先,我們訪問 www.gugeapps.net 這個國內瀏覽器外掛網站,搜尋 Web Scraper,下載外掛,注意這時候外掛不是直接安裝到瀏覽器上的,而是下載到了本地:

然後,我們在瀏覽器的的網址輸入框裡輸入 chrome://extensions/ ,這樣我們就可以開啟瀏覽器的外掛管理後臺:
接下來就是解壓安裝剛剛下載的外掛了。
如果你是 Mac 使用者,首先要把這個安裝包的字尾名 .crx 改為 .zip。

再切到瀏覽器的外掛管理後臺,開啟右上角的開發者模式,把 Web Scraper.zip
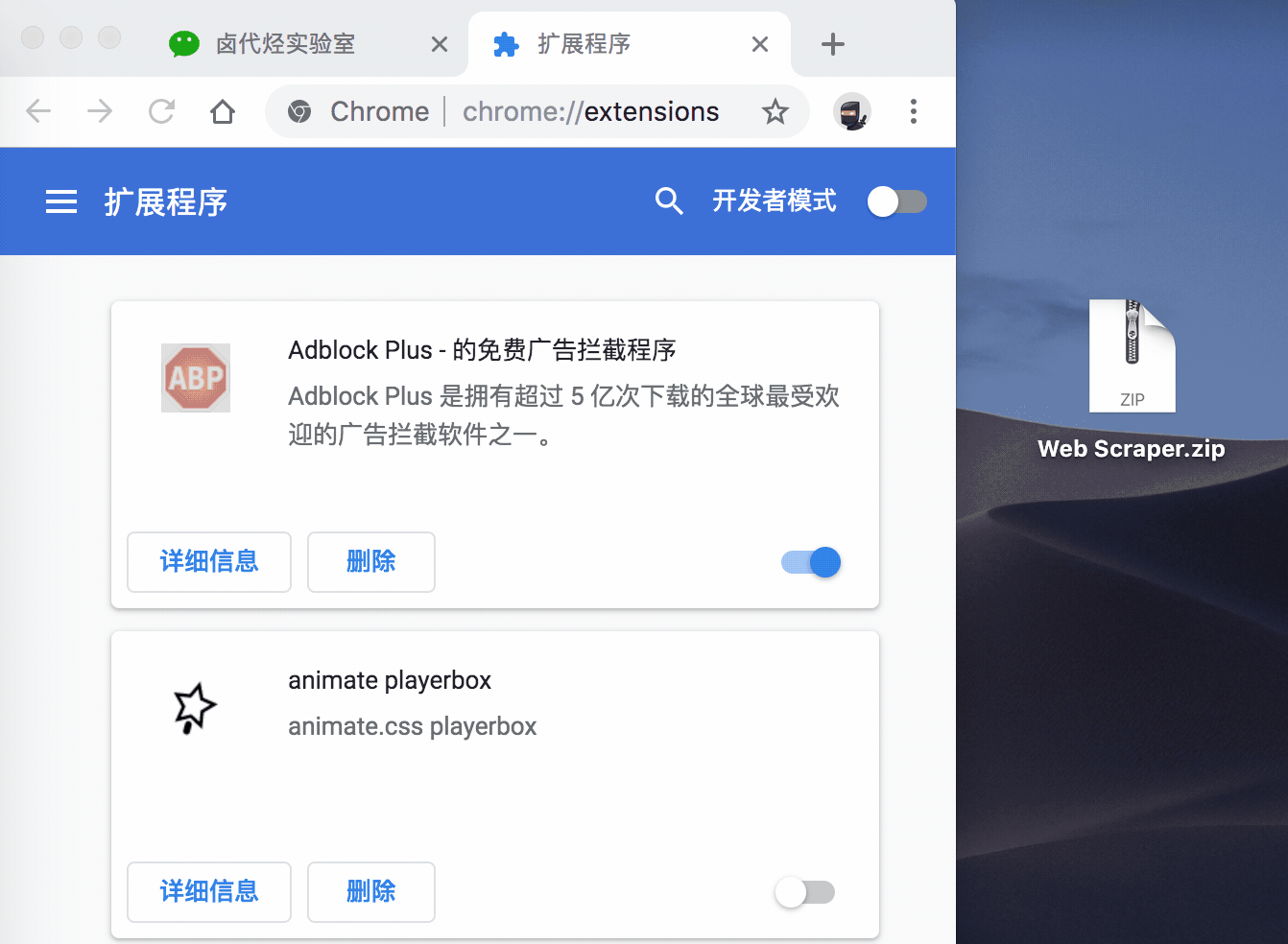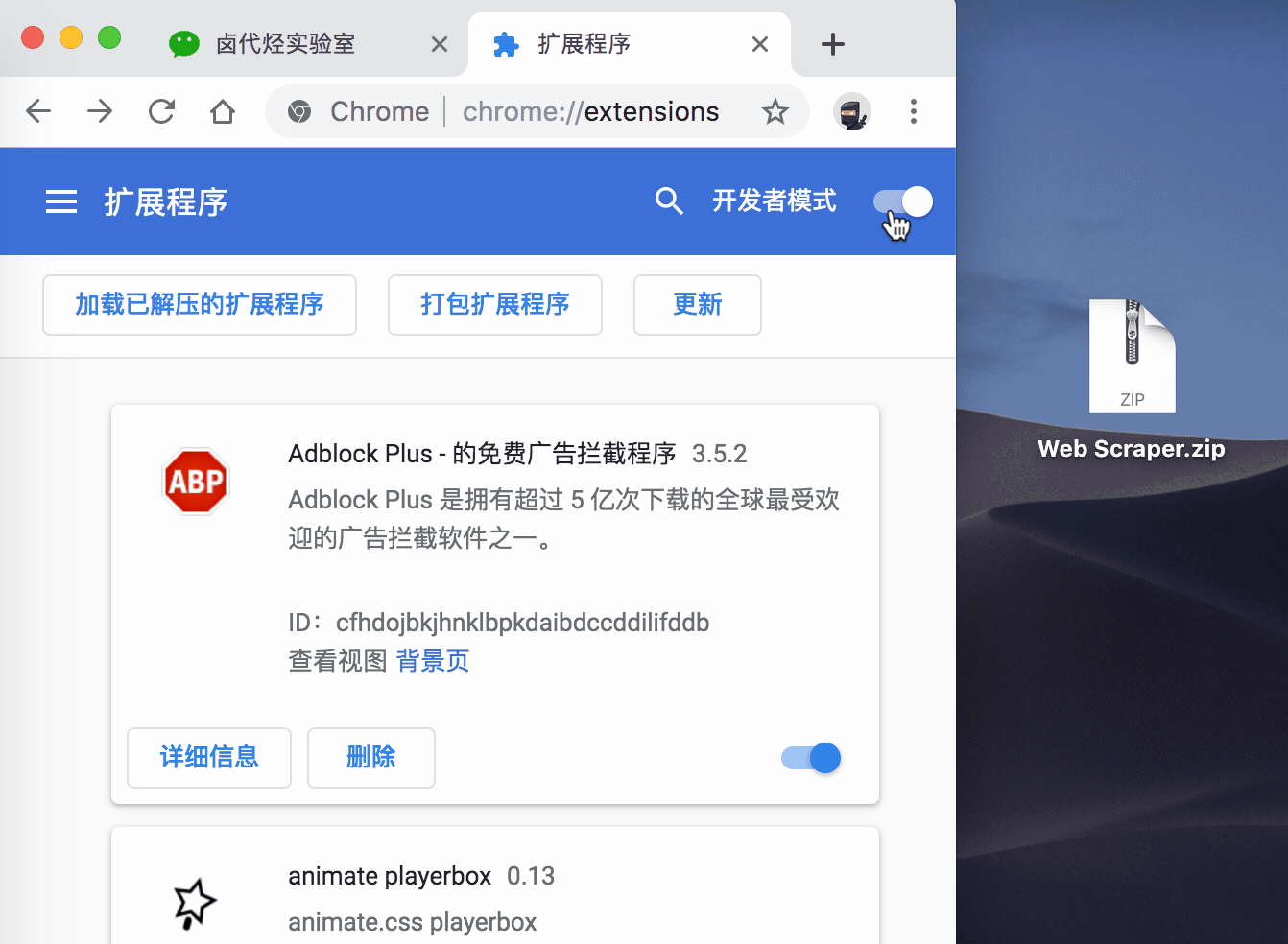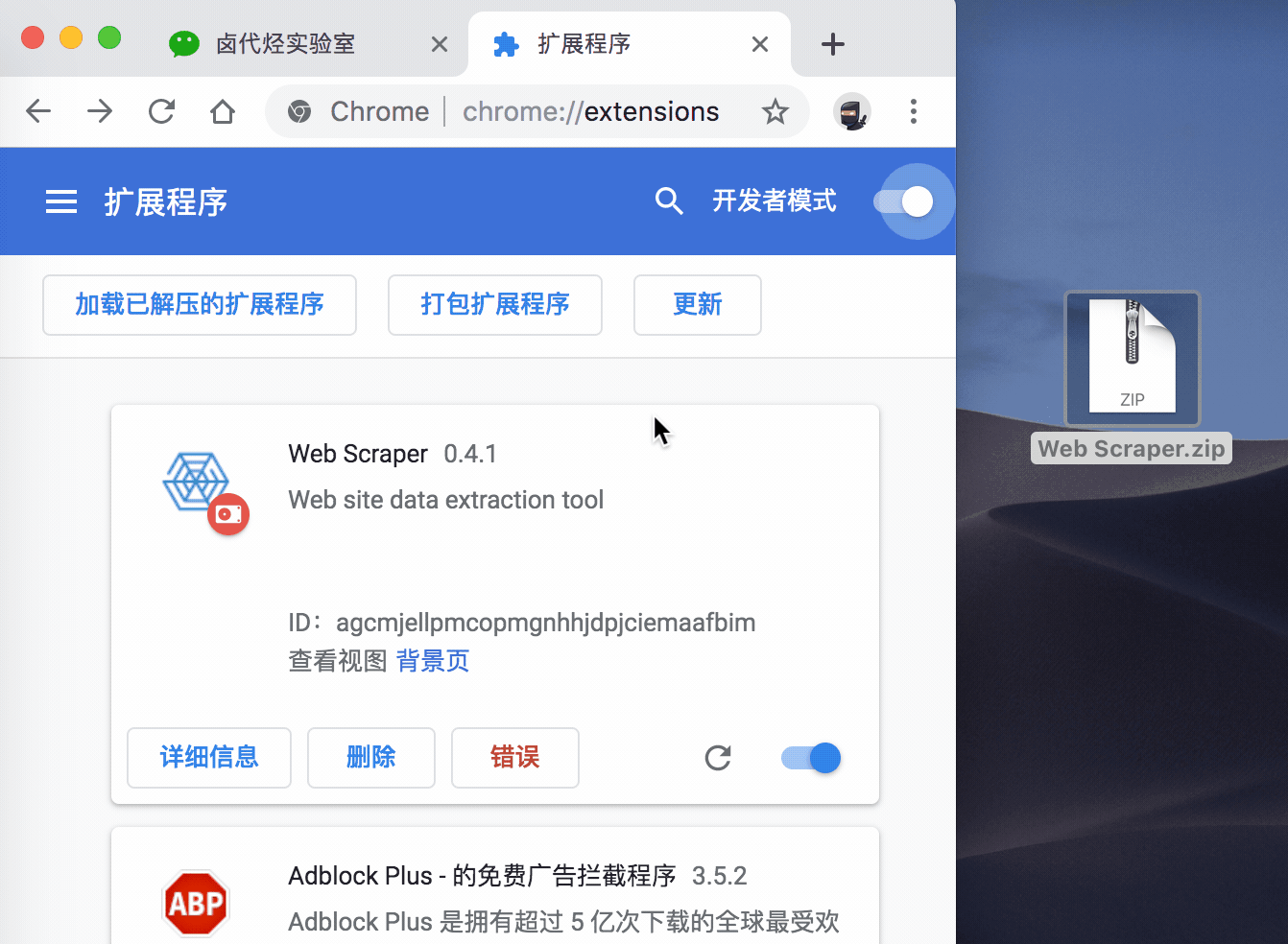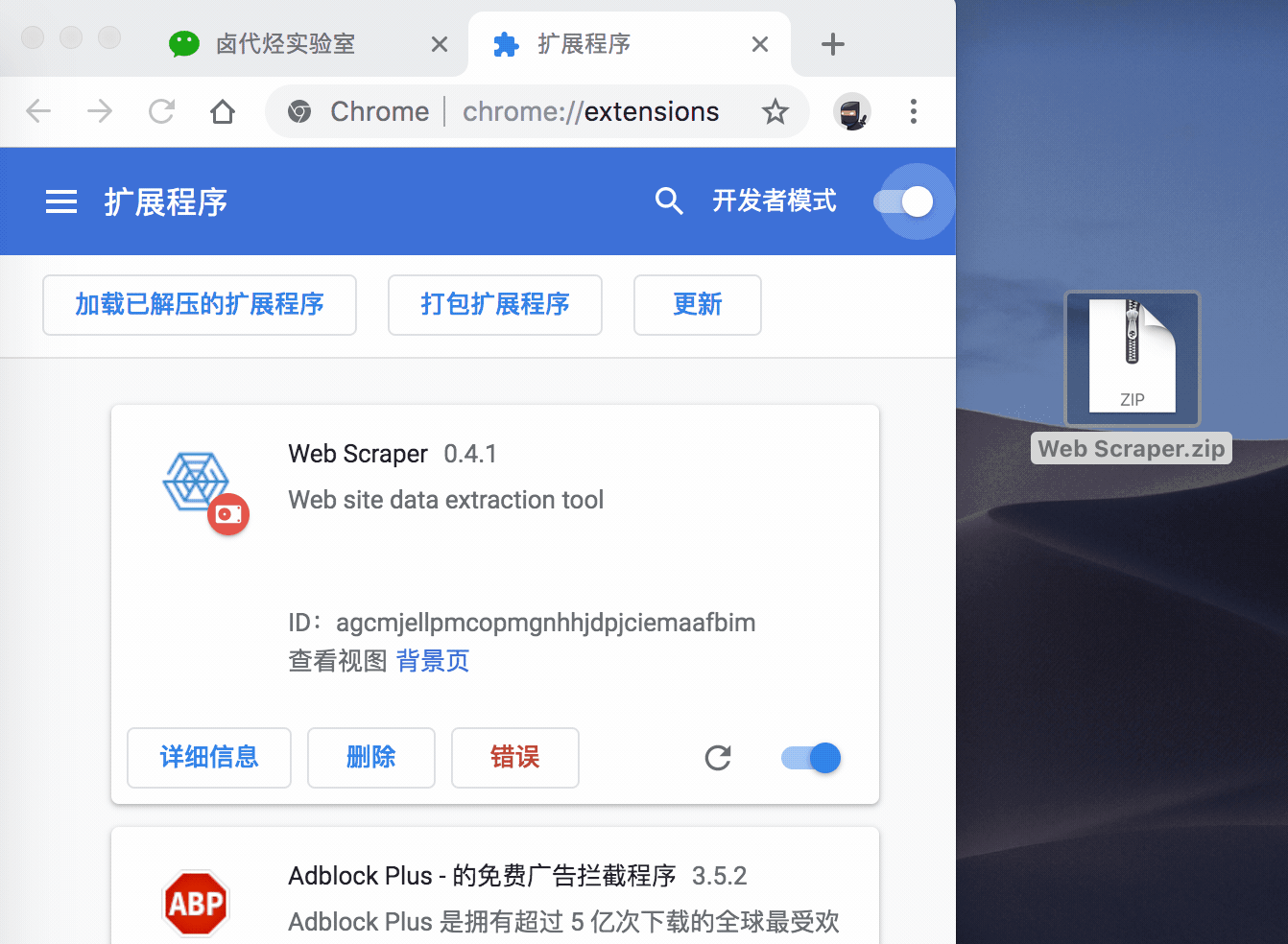
一般這樣安裝會有一個紅色的錯誤按鈕,我們不用管它,直接忽略就行。
如果你是 windows 使用者,你需要這樣做:
1.把字尾為 .crx 的外掛改為 .rar,然後解壓縮
2.進入 chrome://extensions/ 這個頁面,開啟開發者模式
3.點選"載入已解壓的擴充套件程式",選擇第一步中解壓的資料夾,正常情況下就安裝成功了。
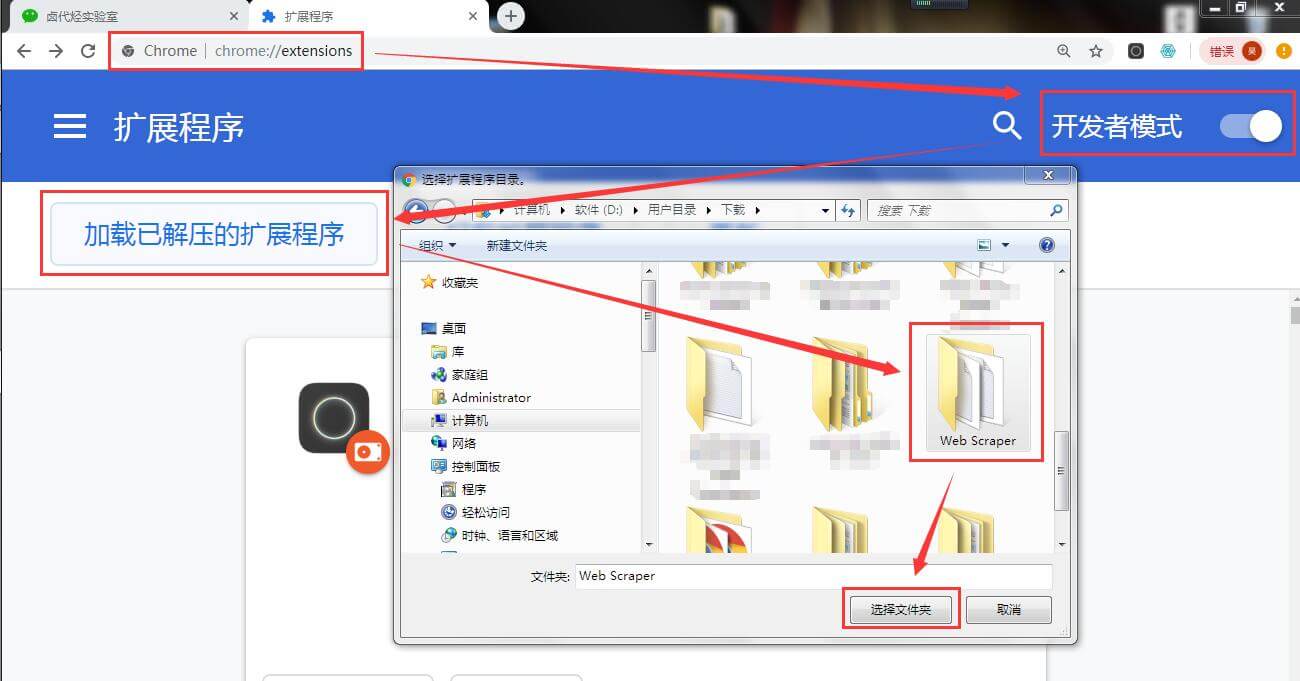
到這裡我們的 Chrome 瀏覽器就成功安裝好 Web Scraper 外掛了。
2.在 QQ 瀏覽器上安裝 Web Scraper 外掛
2.1 安裝 QQ 瀏覽器
去各大應用商店或者訪問 QQ 瀏覽器官網下載安裝就可。
QQ 瀏覽器 PC 版官網下載地址:https://browser.qq.com/
QQ 瀏覽器 Mac 版官網下載地址:https://browser.qq.com/mac/
2.2 安裝 Web Scraper 外掛
Mac 使用者直接訪問瀏覽器左上角的"應用中心",點選進入並搜尋 Web Scraper 安裝即可。

Windows 使用者要先點選瀏覽器左上角的 ≡ 選單欄,在彈出的選單欄裡選擇"應用中心",點選進入並搜尋 Web Scraper 安裝即可。
到這裡我們的 Web Scraper 外掛就安裝成功啦,下一篇我們要探索一些瀏覽器的騷操作,為我們的後續學習打個好的基礎。
推廣一下我的公眾號:鹵代烴實驗室,同步更新內容,覺得我寫的不錯的同學可以點個關注,在微信裡可以及時收到訊息。

相關推薦
簡易資料分析 02 | Web Scraper 的下載與安裝
這是簡易資料分析系列的第 2 篇文章。 上篇說了資料分析在生活中的重要性,從這篇開始,我們就要進入分析的實戰內容了。資料分析資料分析,沒有資料怎麼分析?所以我們首先要學會採集資料。 我調研了很多采集資料的軟體,綜合評定下來發現最好用的還是 Web Scraper,這是一款 Chrome 瀏覽器外掛。
簡易資料分析 04 | Web Scraper 初嘗--抓取豆瓣高分電影
這是簡易資料分析系列的第 4 篇文章。 今天我們開始資料抓取的第一課,完成我們的第一個爬蟲。因為是剛剛開始,操作我會講的非常詳細,可能會有些囉嗦,希望各位不要嫌棄啊:) 有人之前可能學過一些爬蟲知識,總覺得這是個複雜的東西,什麼 HTTP、HTML、IP 池,在這裡我們都不考慮這些東西。一是小的資料量根本
簡易資料分析 07 | Web Scraper 抓取多條內容
這是簡易資料分析系列的第 7 篇文章。 在第 4 篇文章裡,我講解了如何抓取單個網頁裡的單類資訊; 在第 5 篇文章裡,我講解了如何抓取多個網頁裡的單類資訊; 今天我們要講的是,如何抓取多個網頁裡的多類資訊。 這次的抓取是在簡易資料分析 05的基礎上進行的,所以我們一開始就解決了抓取多個網頁的問題,下面全
簡易資料分析 08 | Web Scraper 翻頁——點選「更多按鈕」翻頁
這是簡易資料分析系列的第 8 篇文章。 我們在Web Scraper 翻頁——控制連結批量抓取資料一文中,介紹了控制網頁連結批量抓取資料的辦法。 但是你在預覽一些網站時,會發現隨著網頁的下拉,你需要點選類似於「載入更多」的按鈕去獲取資料,而網頁連結一直沒有變化。 所以控制連結批量抓去資料的方案失效了,所以
簡易資料分析 09 | Web Scraper 自動控制抓取數量 & Web Scraper 父子選擇器
這是簡易資料分析系列的第 9 篇文章。 今天我們說說 Web Scraper 的一些小功能:自動控制 Web Scraper 抓取數量和 Web Scraper 的父子選擇器。 如何只抓取前 100 條資料? 如果跟著上篇教程一步一步做下來,你會發現這個爬蟲會一直運作,根本停不下來。網頁有 1000 條資
簡易資料分析 10 | Web Scraper 翻頁——抓取「滾動載入」型別網頁
這是簡易資料分析系列的第 10 篇文章。 友情提示:這一篇文章的內容較多,資訊量比較大,希望大家學習的時候多看幾遍。 我們在刷朋友圈刷微博的時候,總會強調一個『刷』字,因為看動態的時候,當把內容拉到螢幕末尾的時候,APP 就會自動載入下一頁的資料,從體驗上來看,資料會源源不斷的加載出來,永遠沒有盡頭。
簡易資料分析 11 | Web Scraper 抓取表格資料
這是簡易資料分析系列的第 11 篇文章。 今天我們講講如何抓取網頁表格裡的資料。首先我們分析一下,網頁裡的經典表格是怎麼構成的。 First Name 所在的行比較特殊,是一個表格的表頭,表示資訊分類 2-5 行是表格的主體,展示分類內容 經典表格就這些知識點,沒了。下面我們寫個簡單的表格 Web
簡易資料分析 12 | Web Scraper 翻頁——抓取分頁器翻頁的網頁
這是簡易資料分析系列的第 12 篇文章。 前面幾篇文章我們介紹了 Web Scraper 應對各種翻頁的解決方法,比如說修改網頁連結載入資料、點選“更多按鈕“載入資料和下拉自動載入資料。今天我們說說一種更常見的翻頁型別——分頁器。 本來想解釋一下啥叫分頁器,翻了一堆定義覺得很繁瑣,大家也不是第一年上網了,
簡易資料分析 13 | Web Scraper 高階用法——抓取二級頁面
這是簡易資料分析系列的第 13 篇文章。 不知不覺,web scraper 系列教程我已經寫了 10 篇了,這 10 篇內容,基本上覆蓋了 Web Scraper 大部分功能。今天的內容算這個系列的最後一篇文章了,下一章節我會開一個新坑,說說如何利用 Excel 對收集到的資料做一些格式化的處理和分析。
Web Scraper 翻頁——利用 Link 選擇器翻頁 | 簡易資料分析 14
這是簡易資料分析系列的第 14 篇文章。 今天我們還來聊聊 Web Scraper 翻頁的技巧。 這次的更新是受一位讀者啟發的,他當時想用 Web scraper 爬取一個分頁器分頁的網頁,卻發現我之前介紹的分頁器翻頁方法不管用。我研究了一下才發現我漏講了一種很常見的翻頁場景。 在 web scraper
Web Scraper 高階用法——抓取屬性資訊 | 簡易資料分析 16
這是簡易資料分析系列的第 16 篇文章。 這期課程我們講一個用的較少的 Web Scraper 功能——抓取屬性資訊。 網頁在展示資訊的時候,除了我們看到的內容,其實還有很多隱藏的資訊。我們拿豆瓣電影250舉個例子: 電影圖片正常顯示的時候是這個樣子: 如果網路異常,圖片載入失敗,就會顯示圖片的預設文
Web Scraper 高階用法——利用正則表示式篩選文字資訊 | 簡易資料分析 17
 這是簡易資料分析系列的**第 17 篇**文章。 學習了這麼多課,我想大家已經發現了,web scraper 主要是用來爬取**
Python資料分析基礎 PDF中文版下載
想深入應用手中的資料?還是想在上千份檔案上重複同樣的分析過程?沒有程式設計經驗的非程式設計師們如何能在zui短的時間內學會用當今炙手可熱的Python語言進行資料分析? 來自Facebook的資料專家Clinton Brownley可以幫您解決上述問題。在他的這本書裡,讀者將能掌握
cgmodel簡易資料分析
CG模型網(www.cgmodel.com / www.cgmodel.cn)是一個以3D模型為主,針對所有CG設計行業使用者的互動、展示平臺。2006年6月創立於湖南長沙,現有註冊設計師/藝術家120萬,網站秉承“分享”的理念,通過整合優質的模型資源,
跟我一起學Spark之——《Spark快速大資料分析》pdf版下載
連結:https://pan.baidu.com/s/1vjQCJLyiXzIj6gnCCDyv3g 提取碼:ib01 國慶第四天,去逛了半天的王府井書店,五層出電梯右邊最裡面,倒數第三排《資料結構》,找到了一本很不錯的書《Spark快速大資料分析》,試讀了下,我很喜歡,也很適合
資料分析02
2.線型,線寬和顏色 mp.plot( ..., linestyle=線型, linewidth=線寬, color=顏色, ...) 程式碼:資料分析01 3.設定座標範圍 mp.xlim(水平座標最小值,水平座標最大值) mp.ylim(垂直座標
ActiveReports 大資料分析報告:貿易爭端與中國企業數字化轉型
2018年11月12日至18日,亞太經合組織(APEC)領導人非正式會議首次在南太平洋最大島國巴布亞紐幾內亞的首都莫爾茲比港舉行,本次會議的主題是:“把握包容性機遇,擁抱數字化未來”。 面對全球不斷變化的貿易環境,中國企業如何加快數字化轉型以應對更大的挑戰?又是如何在國際貿易爭端中不斷重塑企業韌性以適應
(87)--Python資料分析:指數密度函式與指數分佈圖
# 指數密度函式與指數分佈圖 lambd = 0.5 x = np.arange(0,15,0.1) y = lambd*np.exp(-lambd*x) plt.plot(x,y) plt.title
資料分析和web後端選哪個?
WEB開發中“前端”和“後端”的區別如下: 一、Web前端: 1)精通HTML,能夠書寫語義合理,結構清晰,易維護的HTML結構。 2)精通CSS,能夠還原視覺設計,併兼容業界承認的主流瀏覽器。 3)熟悉JavaScript,瞭解ECMAScript基
《Spark快速大資料分析》pdf格式下載電子書免費下載
內容簡介 本書由 Spark 開發者及核心成員共同打造,講解了網路大資料時代應運而生的、能高效迅捷地分析處理資料的工具——Spark,它帶領讀者快速掌握用 Spark 收集、計算、簡化和儲存海量資料的方法,學會互動、迭代和增量式分析,解決分割槽、資料本地化和