
簡易資料分析 13 | Web Scraper 高階用法——抓取二級頁面

這是簡易資料分析系列的第 13 篇文章。
不知不覺,web scraper 系列教程我已經寫了 10 篇了,這 10 篇內容,基本上覆蓋了 Web Scraper 大部分功能。今天的內容算這個系列的最後一篇文章了,下一章節我會開一個新坑,說說如何利用 Excel 對收集到的資料做一些格式化的處理和分析。
Web Scraper 教程的全盤總結我放在下一篇文章,今天先開始我們的實戰教程。
在前面的課程裡,我們抓取的資料都是在同一個層級下的內容,探討的問題主要是如何應對市面上的各種分頁型別,但對於詳情頁內容資料如何抓取,卻一直沒有介紹。
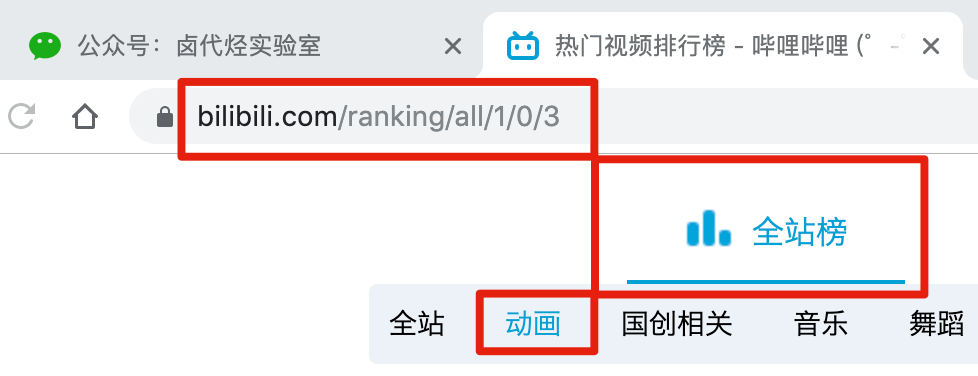
比如說我們想抓取 b 站的動畫區 TOP 排行榜的資料:
https://www.bilibili.com/ranking/all/1/0/3
按之前的抓取邏輯,我們是把這個榜單上和作品有關的資料抓取一遍,比如說下圖裡的排名、作品名字、播放量、彈幕數和作者名。

經常逛 B 站的小夥伴也知道,UP 主經常暗示觀看視訊小夥伴三連操作(點贊+投幣+收藏),由此可見,這 3 個數據對視訊的排名有一定的影響力,所以這些資料對我們來說也有一定的參考價值。

但遺憾的是,在這個排名列表裡,並沒有相關資料。這幾個資料在視訊詳情頁裡,需要我們點選連結進去才能看到:

今天的教程內容,就是教你如何利用 Web Scraper,在抓取一級頁面(列表頁)的同時,抓取二級頁面(詳情頁)的內容。
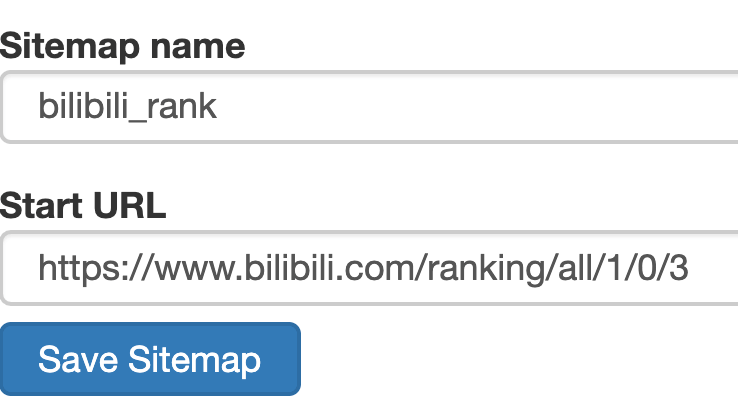
1.建立 SiteMap
首先我們找到要抓取的資料的位置,關鍵路徑我都在下圖的紅框裡標出來了,大家可以對照一下:
然後建立一個相關的 SiteMap,這裡我取了個 bilibili_rank 的名字:
2.建立容器的 selector
設定之前我們先觀察一下,發現這個網頁的排行榜資料是 100 條資料一次性載入完的,沒有分頁的必要,所以這裡的 Type 型別選為 Element 就行。
其他的引數都比較簡單,就不細說了(不太懂的可以看我之前的基礎教程)這裡截個圖大家可以做個參考:
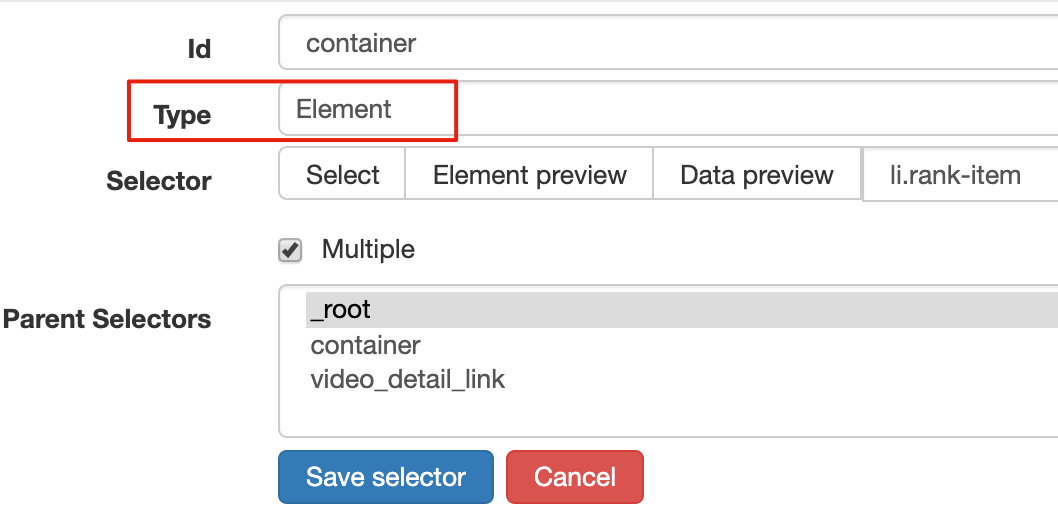
3.建立列表頁子選擇器
這次子選擇器要抓取的內容如下,也都比較簡單,截個圖大家可以參考一下:
- 排名(num)
- 作品標題(title)
- 播放量(play_amount)
- 彈幕量(danmu_count)
- 作者:(author)

如果做到這一步,其實已經可以抓到所有已知的列表資料了,但本文的重點是:如何抓取二級頁面(詳情頁)的三連資料?
跟著做了這麼多爬蟲,可能你已經發現了,Web Scraper 本質是模擬人類的操作以達到抓取資料的目的。
那麼我們正常檢視二級頁面(詳情頁)是怎麼操作的呢?其實就是點選標題連結跳轉:

Web Scraper 為我們提供了點選連結跳轉的功能,那就是 Type 為 Link 的選擇器。
感覺有些抽象?我們對照例子來理解一下。
首先在這個案例裡,我們獲取了標題的文字,這時的選擇器型別為 Text:
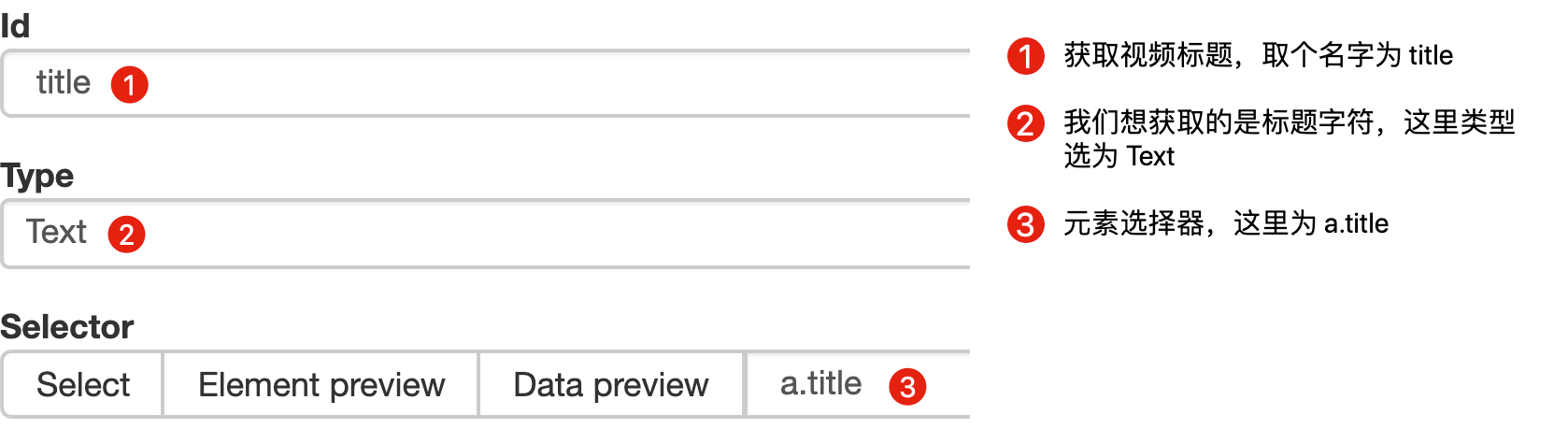
當我們要抓取連結時,就要再建立一個選擇器,選的元素是一樣的,但是 Type 型別為 Link:

建立成功後,我們點選這個 Link 型別的選擇器,進入他的內部,再建立相關的選擇器,下面我錄了個動圖,注意看我滑鼠強調的導航路由部分,可以很清晰的看出這幾個選擇器的層級關係:
4.建立詳情頁子選擇器
當你點選連結後就會發現,瀏覽器會在一個新的 Tab 頁開啟詳情頁,但是 Web Scraper 的選擇視窗開在列表頁,無法跨頁面選擇想要的資料。
處理這個問題也很簡單,你可以複製詳情頁的連結,拷貝到列表頁所在的 Tab 頁裡,然後回車重新載入,這樣就可以在當前頁面選擇了。
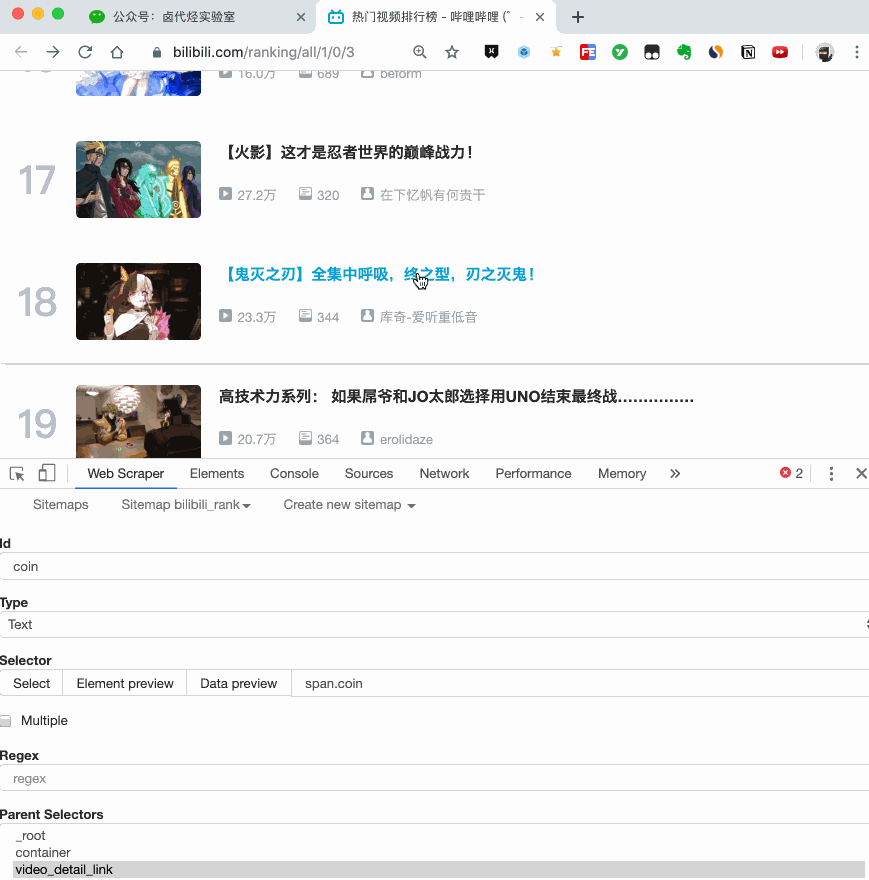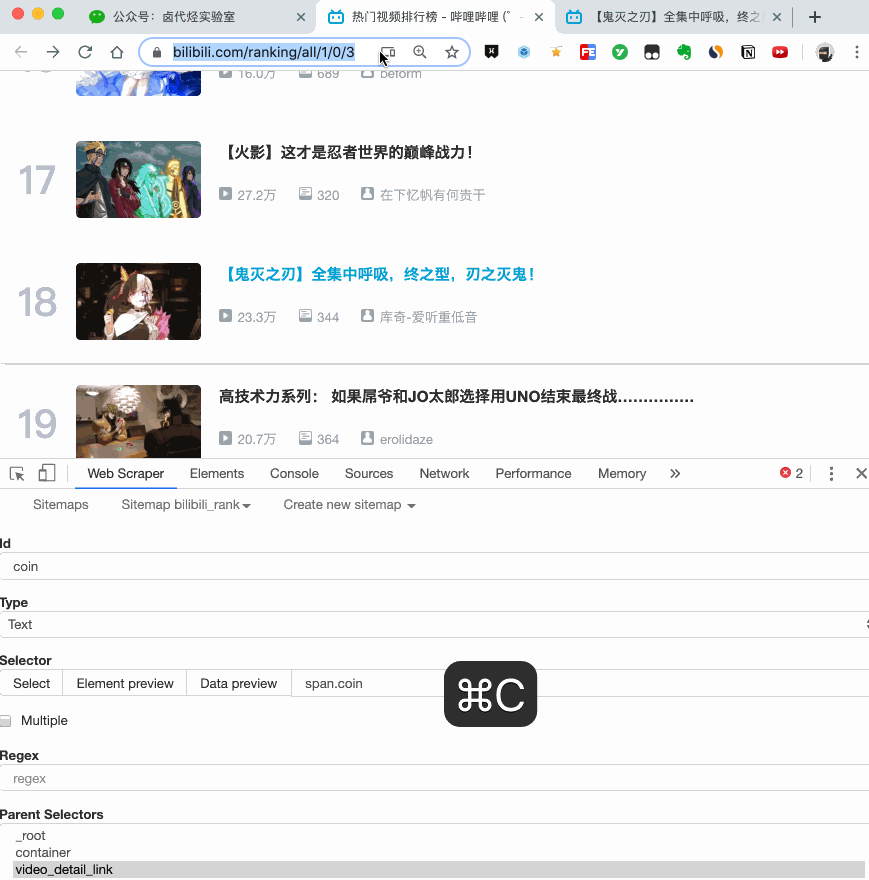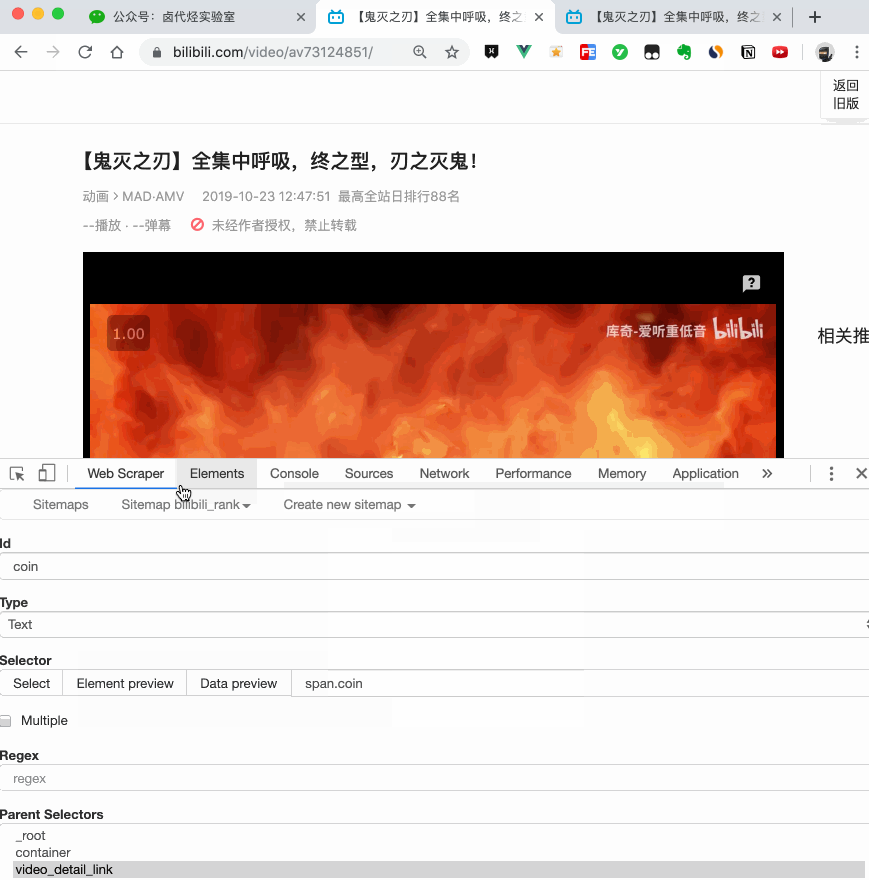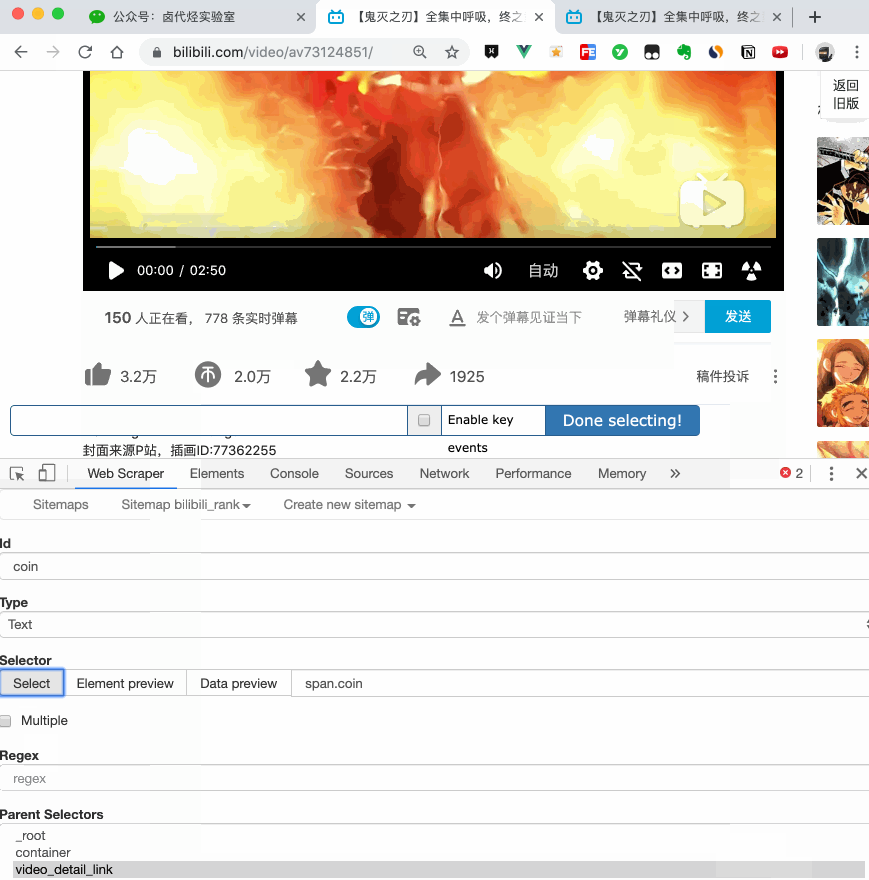
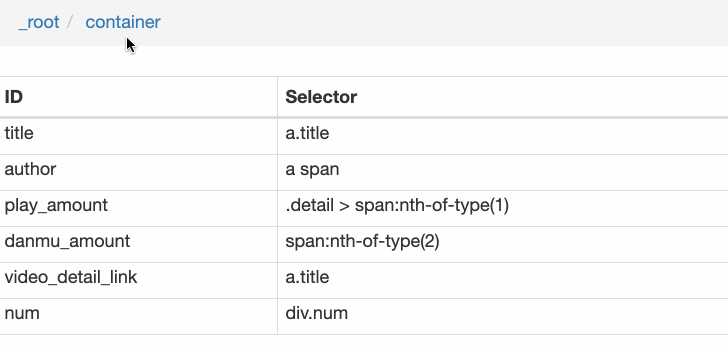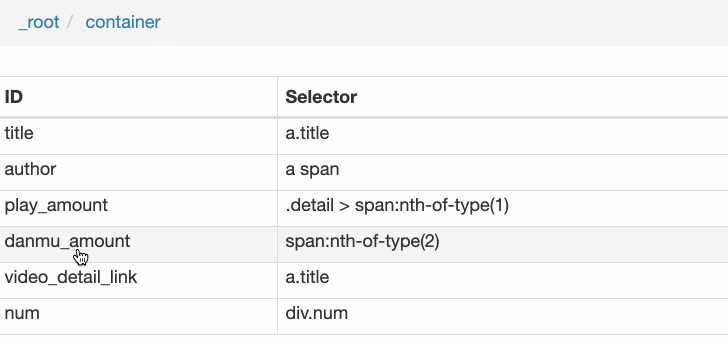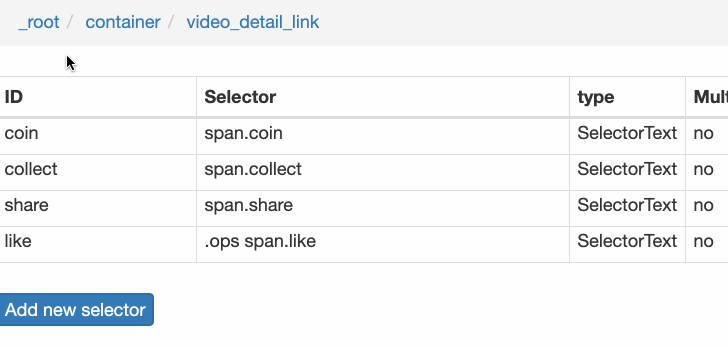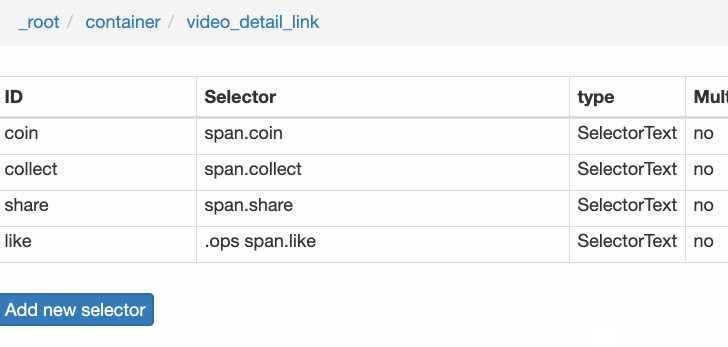
我們在型別為 Link 的選擇器內部多建立幾個選擇器,這裡我選擇了點贊數、硬幣數、收藏數和分享數 4 個數據,這個操作也很簡單,這裡我就不詳細說了。

所有選擇器的結構圖如下:
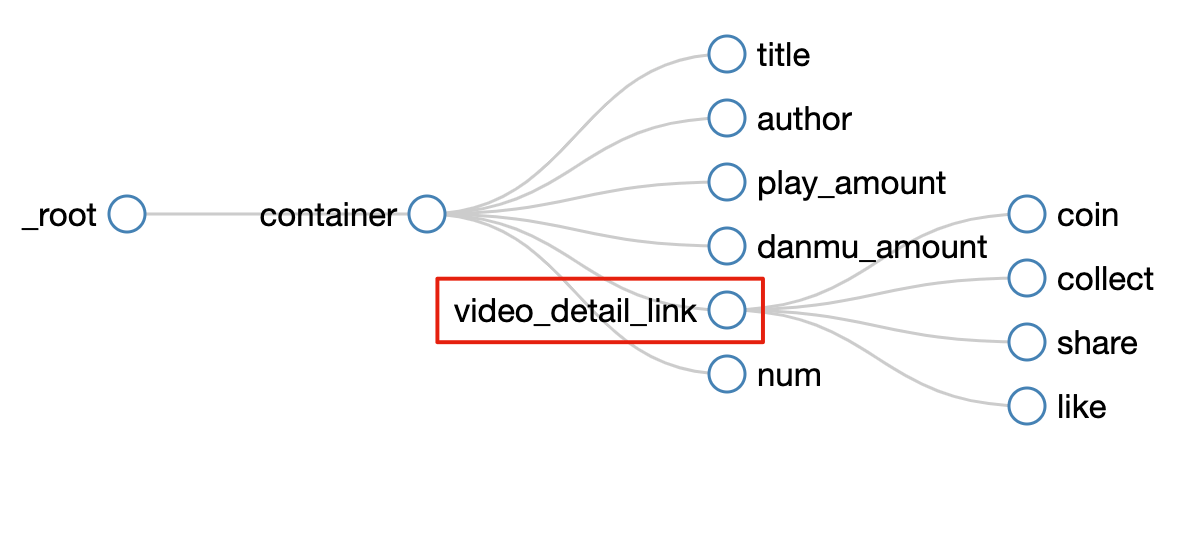
我們可以看到 video_detail_link 這個節點包含 4 個二級頁面(詳情頁)的資料,到此為止,我們的子選擇器已經全部建立好了。
5.抓取資料
終於到了激動人心的環節了,我們要開始抓取資料了。但是抓取前我們要把等待時間調整得大一些,預設時間是 2000 ms,我這裡改成了 5000 ms。

為什麼這麼做?看了下圖你就明白了:

首先,每次開啟二級頁面,都是一個全新的頁面,這時候瀏覽器載入網頁需要花費時間;
其次,我們可以觀察一下要抓取的點贊量等資料,頁面剛剛載入的時候,它的值是 「--」,等待一會兒後才會變成數字。
所以,我們直接等待 5000 ms,等頁面和資料載入完成後,再統一抓取。
配置好引數後,我們就可以正式抓取並下載了。下圖是我抓取資料的一部分,特此證明此方法有用:
6.總結
這次的教程可能有些難度,我把我的 SiteMap 分享出來,製作的時候如果遇到難題,可以參考一下我的配置,SiteMap 匯入的功能我在第 6 篇教程裡詳細說明了,大家可以配合食用:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}當你掌握了二級頁面的抓取方式後,三級頁面、四級頁面也不在話下。因為套路都是一樣的:都是在 Link 選擇器指向的下一個頁面抓取資料,因為原理是一樣的,我就不演示了。
7.推薦閱讀
簡易資料分析 06 | 如何匯入別人已經寫好的 Web Scraper 爬蟲
簡易資料分析 05 | Web Scraper 翻頁——控制連結批量抓取資料
簡易資料分析 08 | Web Scraper 翻頁——點選「更多按鈕」翻頁
簡易資料分析 10 | Web Scraper 翻頁——抓取「滾動載入」型別網頁
簡易資料分析 12 | Web Scraper 翻頁——抓取分頁器翻頁的網頁

相關推薦
簡易資料分析 13 | Web Scraper 高階用法——抓取二級頁面
這是簡易資料分析系列的第 13 篇文章。 不知不覺,web scraper 系列教程我已經寫了 10 篇了,這 10 篇內容,基本上覆蓋了 Web Scraper 大部分功能。今天的內容算這個系列的最後一篇文章了,下一章節我會開一個新坑,說說如何利用 Excel 對收集到的資料做一些格式化的處理和分析。
簡易資料分析 04 | Web Scraper 初嘗--抓取豆瓣高分電影
這是簡易資料分析系列的第 4 篇文章。 今天我們開始資料抓取的第一課,完成我們的第一個爬蟲。因為是剛剛開始,操作我會講的非常詳細,可能會有些囉嗦,希望各位不要嫌棄啊:) 有人之前可能學過一些爬蟲知識,總覺得這是個複雜的東西,什麼 HTTP、HTML、IP 池,在這裡我們都不考慮這些東西。一是小的資料量根本
簡易資料分析 09 | Web Scraper 自動控制抓取數量 & Web Scraper 父子選擇器
這是簡易資料分析系列的第 9 篇文章。 今天我們說說 Web Scraper 的一些小功能:自動控制 Web Scraper 抓取數量和 Web Scraper 的父子選擇器。 如何只抓取前 100 條資料? 如果跟著上篇教程一步一步做下來,你會發現這個爬蟲會一直運作,根本停不下來。網頁有 1000 條資
簡易資料分析 10 | Web Scraper 翻頁——抓取「滾動載入」型別網頁
這是簡易資料分析系列的第 10 篇文章。 友情提示:這一篇文章的內容較多,資訊量比較大,希望大家學習的時候多看幾遍。 我們在刷朋友圈刷微博的時候,總會強調一個『刷』字,因為看動態的時候,當把內容拉到螢幕末尾的時候,APP 就會自動載入下一頁的資料,從體驗上來看,資料會源源不斷的加載出來,永遠沒有盡頭。
簡易資料分析 12 | Web Scraper 翻頁——抓取分頁器翻頁的網頁
這是簡易資料分析系列的第 12 篇文章。 前面幾篇文章我們介紹了 Web Scraper 應對各種翻頁的解決方法,比如說修改網頁連結載入資料、點選“更多按鈕“載入資料和下拉自動載入資料。今天我們說說一種更常見的翻頁型別——分頁器。 本來想解釋一下啥叫分頁器,翻了一堆定義覺得很繁瑣,大家也不是第一年上網了,
Web Scraper 高階用法——抓取屬性資訊 | 簡易資料分析 16
這是簡易資料分析系列的第 16 篇文章。 這期課程我們講一個用的較少的 Web Scraper 功能——抓取屬性資訊。 網頁在展示資訊的時候,除了我們看到的內容,其實還有很多隱藏的資訊。我們拿豆瓣電影250舉個例子: 電影圖片正常顯示的時候是這個樣子: 如果網路異常,圖片載入失敗,就會顯示圖片的預設文
簡易資料分析 02 | Web Scraper 的下載與安裝
這是簡易資料分析系列的第 2 篇文章。 上篇說了資料分析在生活中的重要性,從這篇開始,我們就要進入分析的實戰內容了。資料分析資料分析,沒有資料怎麼分析?所以我們首先要學會採集資料。 我調研了很多采集資料的軟體,綜合評定下來發現最好用的還是 Web Scraper,這是一款 Chrome 瀏覽器外掛。
簡易資料分析 07 | Web Scraper 抓取多條內容
這是簡易資料分析系列的第 7 篇文章。 在第 4 篇文章裡,我講解了如何抓取單個網頁裡的單類資訊; 在第 5 篇文章裡,我講解了如何抓取多個網頁裡的單類資訊; 今天我們要講的是,如何抓取多個網頁裡的多類資訊。 這次的抓取是在簡易資料分析 05的基礎上進行的,所以我們一開始就解決了抓取多個網頁的問題,下面全
簡易資料分析 08 | Web Scraper 翻頁——點選「更多按鈕」翻頁
這是簡易資料分析系列的第 8 篇文章。 我們在Web Scraper 翻頁——控制連結批量抓取資料一文中,介紹了控制網頁連結批量抓取資料的辦法。 但是你在預覽一些網站時,會發現隨著網頁的下拉,你需要點選類似於「載入更多」的按鈕去獲取資料,而網頁連結一直沒有變化。 所以控制連結批量抓去資料的方案失效了,所以
簡易資料分析 11 | Web Scraper 抓取表格資料
這是簡易資料分析系列的第 11 篇文章。 今天我們講講如何抓取網頁表格裡的資料。首先我們分析一下,網頁裡的經典表格是怎麼構成的。 First Name 所在的行比較特殊,是一個表格的表頭,表示資訊分類 2-5 行是表格的主體,展示分類內容 經典表格就這些知識點,沒了。下面我們寫個簡單的表格 Web
Web Scraper 高階用法——利用正則表示式篩選文字資訊 | 簡易資料分析 17
 這是簡易資料分析系列的**第 17 篇**文章。 學習了這麼多課,我想大家已經發現了,web scraper 主要是用來爬取**
Web Scraper 翻頁——利用 Link 選擇器翻頁 | 簡易資料分析 14
這是簡易資料分析系列的第 14 篇文章。 今天我們還來聊聊 Web Scraper 翻頁的技巧。 這次的更新是受一位讀者啟發的,他當時想用 Web scraper 爬取一個分頁器分頁的網頁,卻發現我之前介紹的分頁器翻頁方法不管用。我研究了一下才發現我漏講了一種很常見的翻頁場景。 在 web scraper
cgmodel簡易資料分析
CG模型網(www.cgmodel.com / www.cgmodel.cn)是一個以3D模型為主,針對所有CG設計行業使用者的互動、展示平臺。2006年6月創立於湖南長沙,現有註冊設計師/藝術家120萬,網站秉承“分享”的理念,通過整合優質的模型資源,
資料分析和web後端選哪個?
WEB開發中“前端”和“後端”的區別如下: 一、Web前端: 1)精通HTML,能夠書寫語義合理,結構清晰,易維護的HTML結構。 2)精通CSS,能夠還原視覺設計,併兼容業界承認的主流瀏覽器。 3)熟悉JavaScript,瞭解ECMAScript基
Python資料分析 | (9)NumPy陣列高階操作---變型、重塑、扁平、合併拆分以及重複
本篇部落格所有示例使用Jupyter NoteBook演示。 Python資料分析系列筆記基於:利用Python進行資料分析(第2版) 目錄 1.陣列轉置和軸對換 2.陣列重塑 3.陣列扁平化 4.陣列的合併和拆分 5.元素的重複操作:tile/r
python資料分析二:numpy的常規用法(file,隨機漫步)
要知道的數學名詞線性代數 行列式 行列式的計算 矩陣的乘法矩陣的轉置 矩陣的逆 矩陣*矩陣的逆=單位陣 矩陣QR分解隨機漫步隨機生成1或者-1,每次生成進行疊加,存入陣列,檢視關係# -*- coding: utf-8 -*- import numpy as np ''' 將
【簡易采集】美團數據抓取方法 八爪魚
方法 IT 情況下 根據 規則 內置 教程 關鍵詞 查看 【簡易采集】美團數據抓取方法 最近學習了 一下 如何爬取數據 然後就接觸了 八爪魚 數據分析 這個軟件 詳細信息訪問這個:http://www.bazhuayu.com/tutorial/hottutoria
“我插入MongoDB的資料都去哪了?”——明明抓取到了資料,為啥不見了?
是因為抓取速度太頻繁被封了IP嘛? 不應該呀,明明設定了10幾秒的睡眠時間的呀 是因為資料大小超過了一定的大小嘛?聽說MongoDB要求單個Document要小於16Mb 最
資料探勘_多執行緒抓取
在這一篇文章中,我們主要來介紹多執行緒抓取資料。 多執行緒是以併發的方式執行的,在這裡要注意,Python的多執行緒程式只能執行在一個單核上以併發的方式執行,即便是多核的機器,所以說,使用多執行緒抓取可以極大地提高抓取效率下面我們以requests為例介紹多執行緒抓取,然後在
高階網頁抓取:如何繞過雷區,抓取成功
介紹我不會真的考慮網站刮我的愛好或任何東西,但我想我做了很多。看起來我所處理的許多事情都要求我掌握不能以任何其他方式獲得的資料。我需要對Intoli的遊戲進行靜態分析,因此我需要搜尋Google Play商店才能找到新遊戲並下載遊戲。該尖尖的球擴充套件需要從不同的網站和最簡單