
簡易資料分析 07 | Web Scraper 抓取多條內容

這是簡易資料分析系列的第 7 篇文章。
在第 4 篇文章裡,我講解了如何抓取單個網頁裡的單類資訊;
在第 5 篇文章裡,我講解了如何抓取多個網頁裡的單類資訊;
今天我們要講的是,如何抓取多個網頁裡的多類資訊。
這次的抓取是在簡易資料分析 05的基礎上進行的,所以我們一開始就解決了抓取多個網頁的問題,下面全力解決如何抓取多類資訊就可以了。
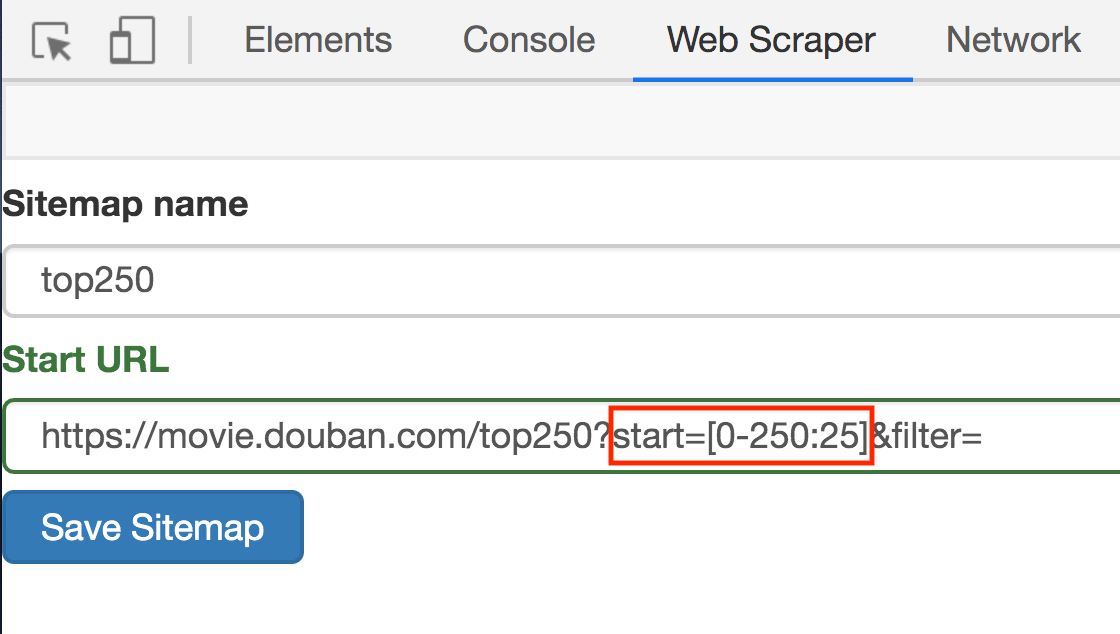
我們在實操前先把邏輯理清:
上幾篇只抓取了一類元素:電影名字。這期我們要抓取多類元素:排名,電影名,評分和一句話影評。
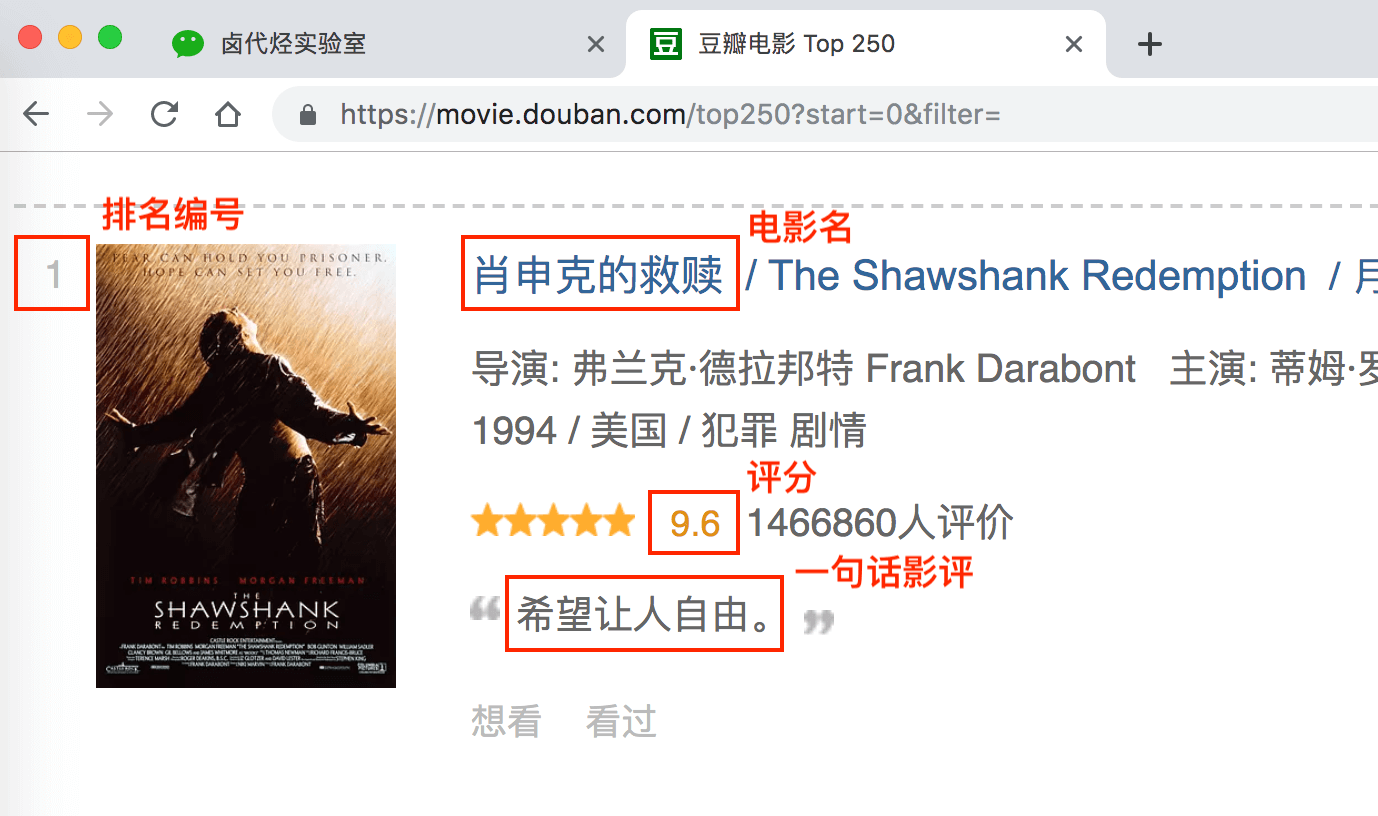
根據 Web Scraper 的特性,想抓取多類資料,首先要抓取包裹多類資料的容器,然後再選擇容器裡的資料,這樣才能正確的抓取。我畫一張圖演示一下:

我們首先要抓取多個 container(容器),再抓取 container 裡的元素:編號、電影名、評分和一句話影評,當爬蟲執行完後,我們就會成功抓取資料。
概念上搞清楚了,我們就可以講實際操作了。
如果對以下的操作有疑問,可以看 簡易資料分析 04 的內容,那篇文章詳細圖解了如何用 Web Scraper 選擇元素的操作
1.點選 Stiemaps,在新的面板裡點選 ID 為 top250 的這列資料

2.刪除掉舊的 selector,點選 Add new selector 增加一個新的 selector

3.在新的 selector 內,注意把 Type 型別改為 Element(元素),因為在 Web Scraper 裡,只有元素型別才能包含多個內容。

我們勾選的元素區域如下圖所示,確認無誤後點擊 Save selector 按鈕,就會回退到上一個操作面板。
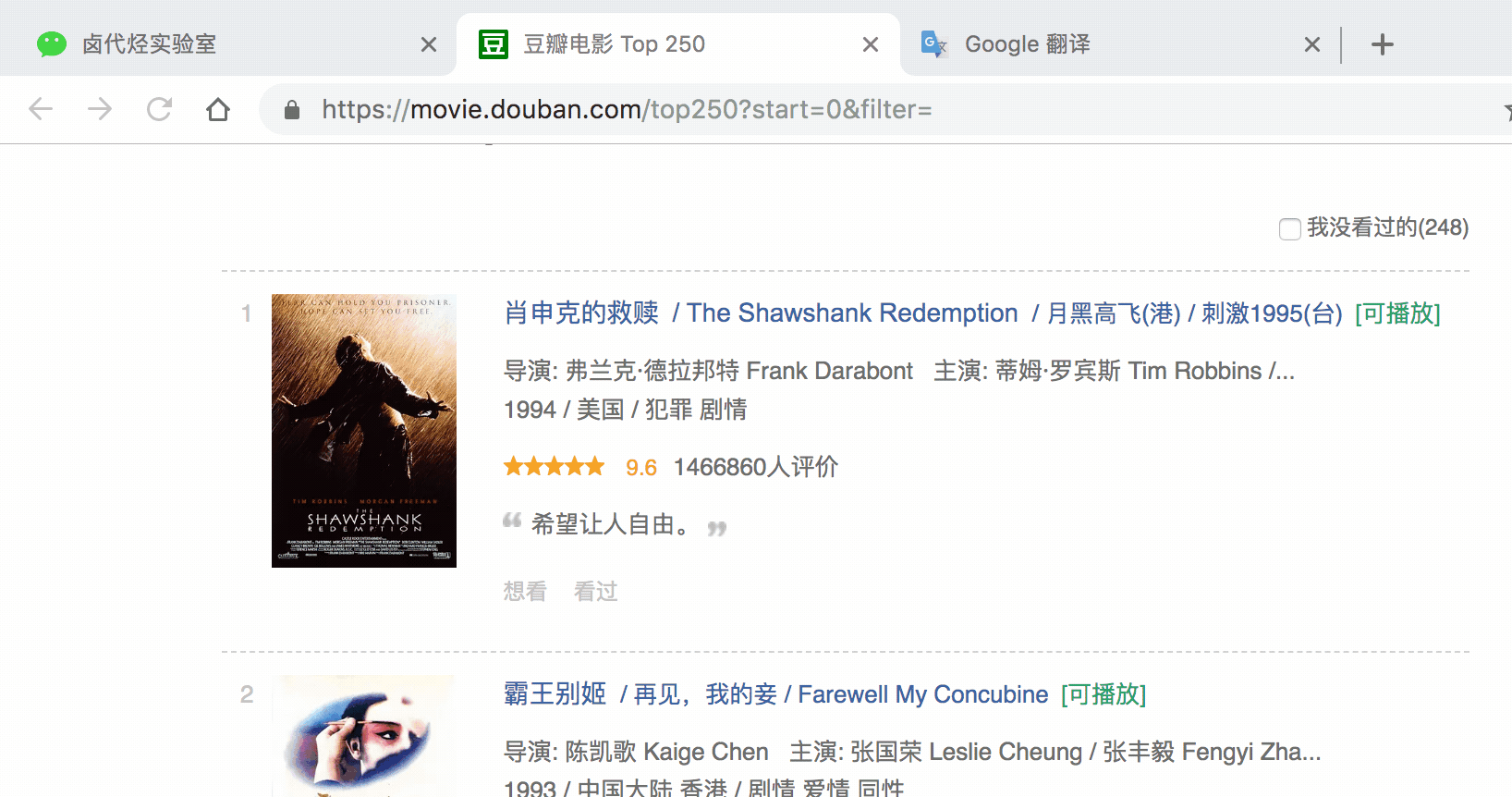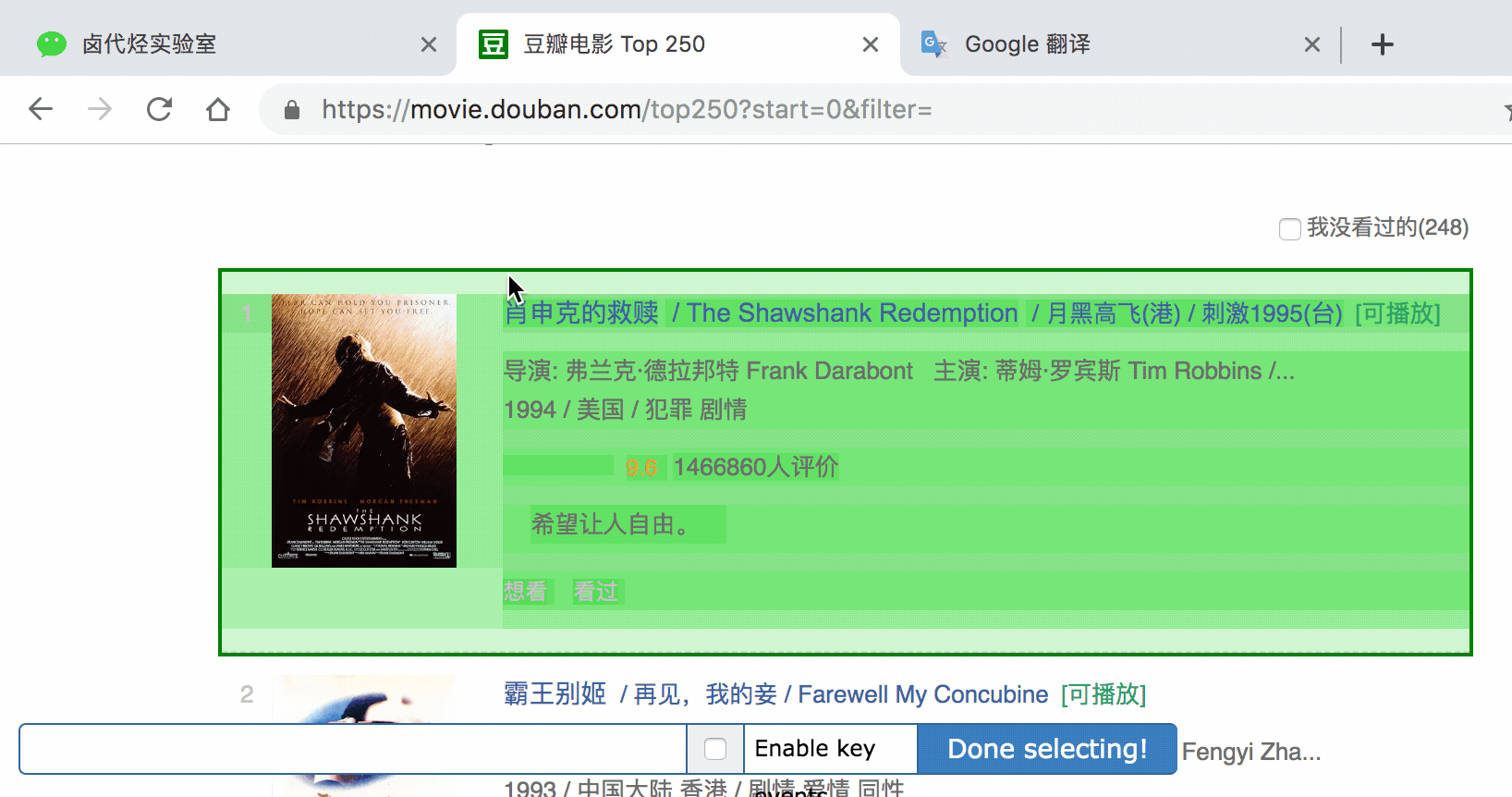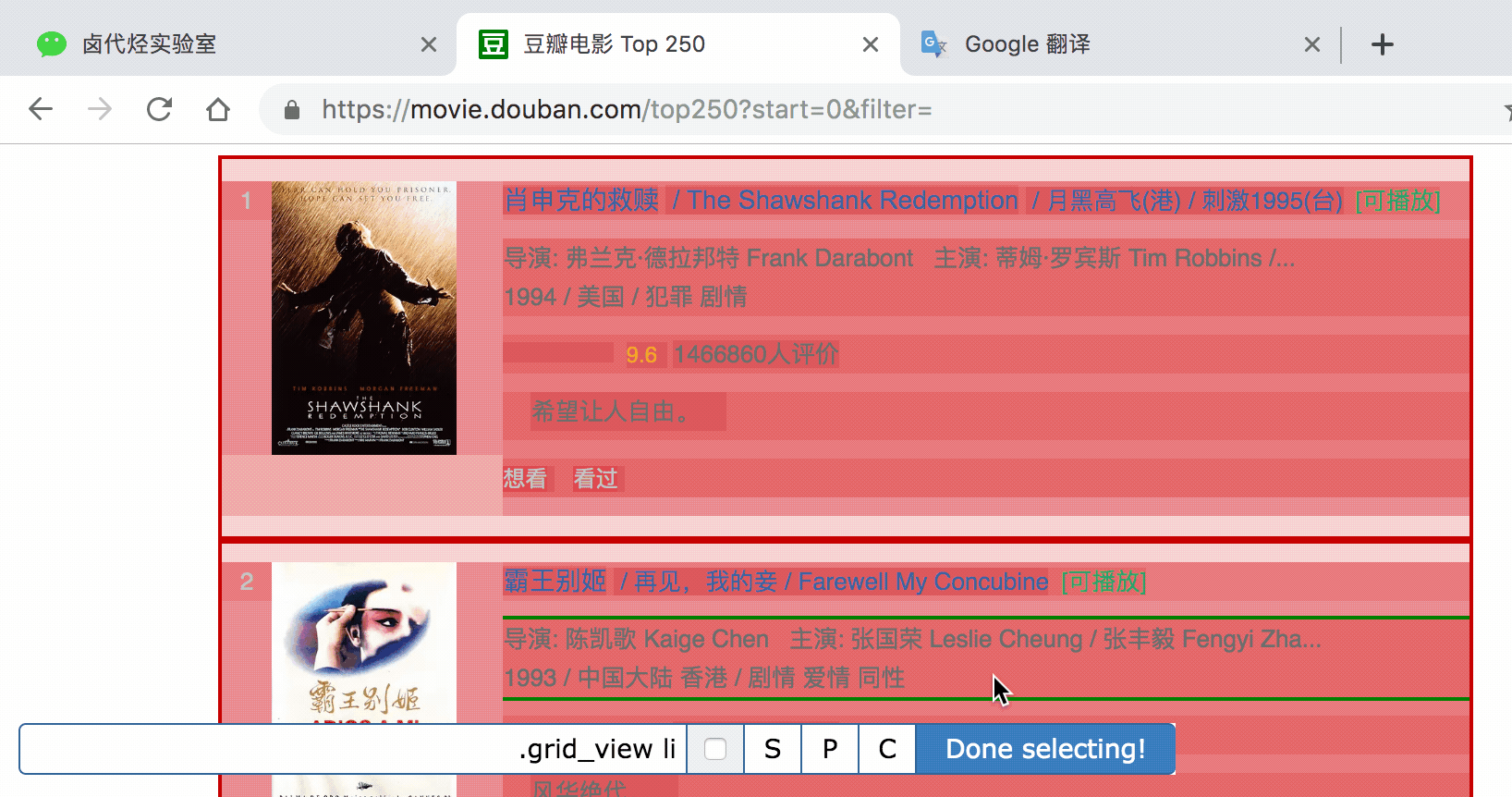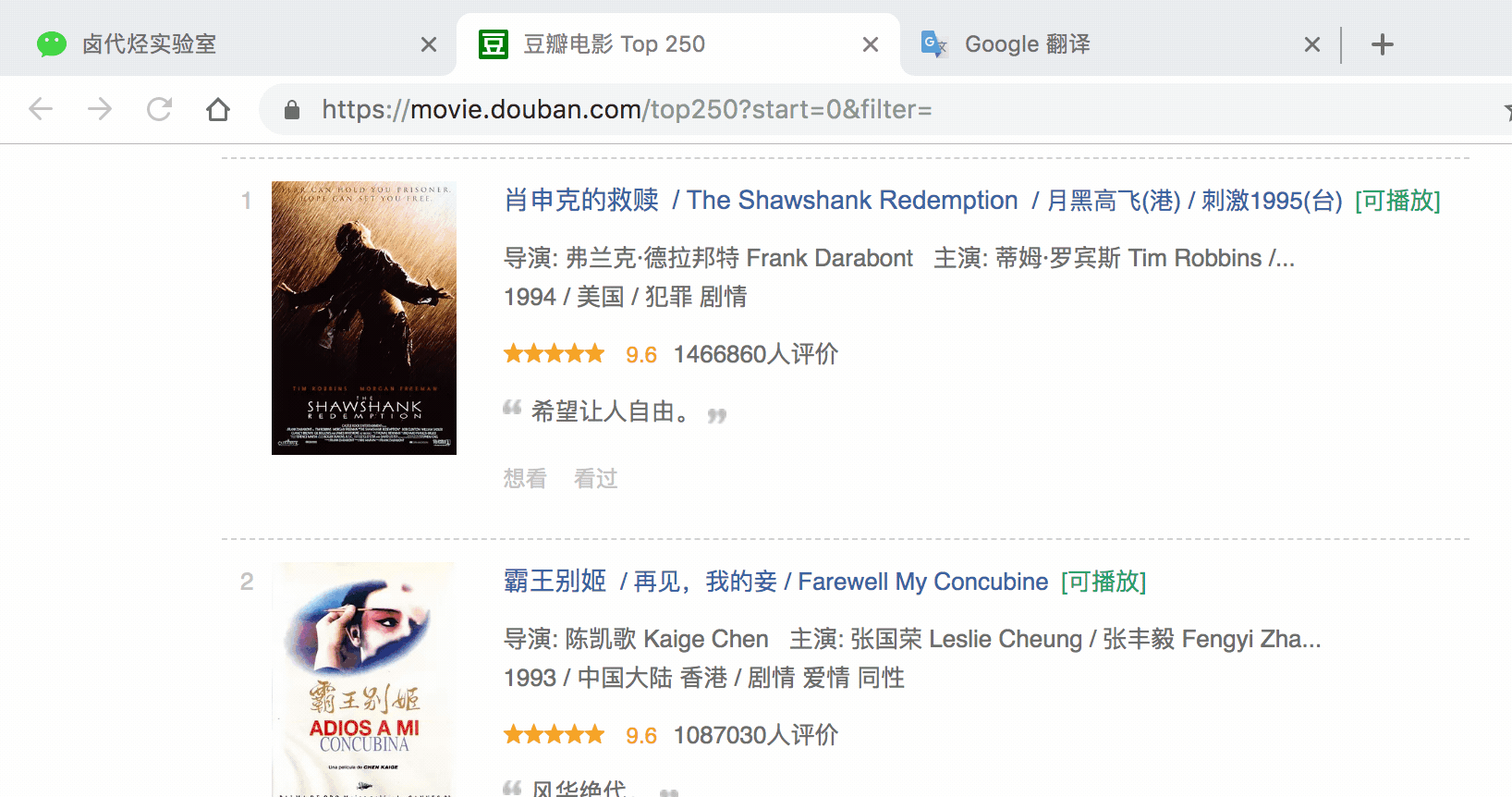
在新的面板裡,點選剛剛建立的 selector 那行資料:

點選後我們就會進入一個新的面板,根據導航我們可知在 container 內部。

在新的面板裡,我們點選 Add new selector,新建一個 selector,用來抓取電影名,型別為 Text,值得注意的是,因為我們是在 container 內選擇文字的,一個 container 內只有一個電影名,所以多選不要勾選,要不然會抓取失敗。

選擇電影名的時候你會發現 container 黃色高亮,我們就在黃色的區域裡選擇電影名就好了。
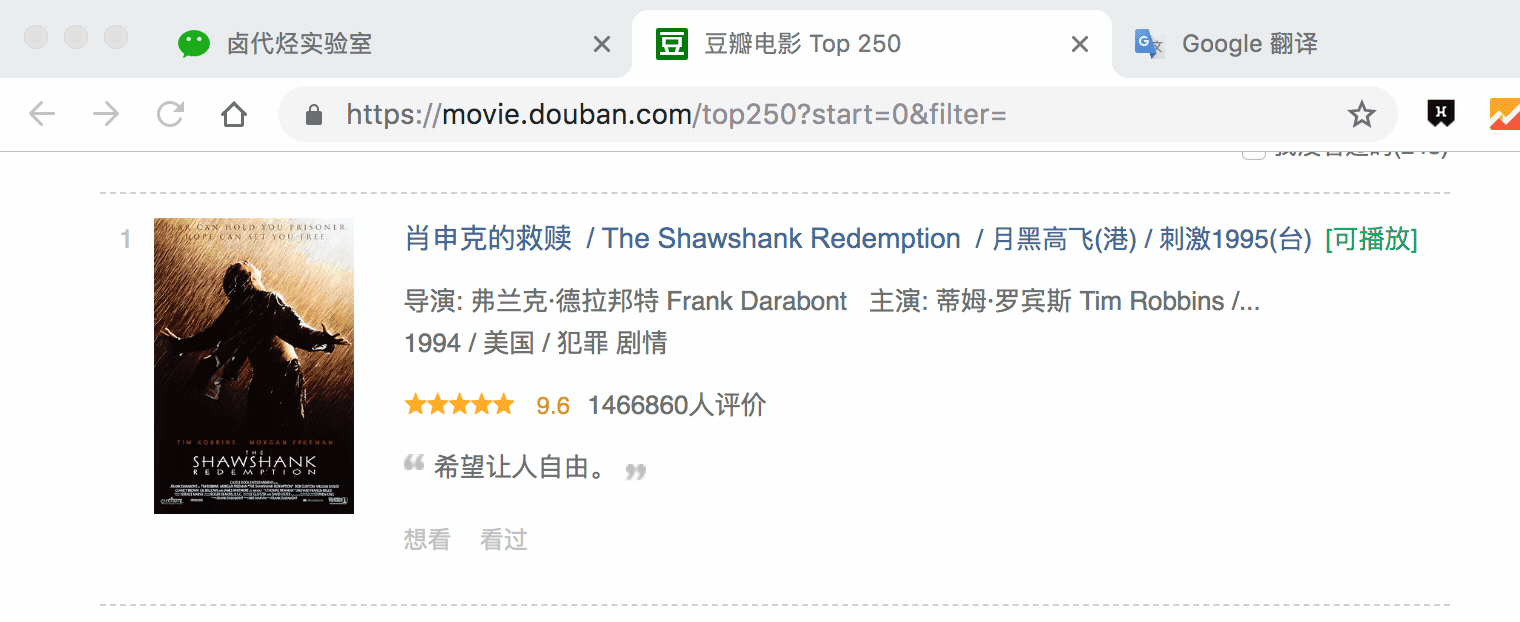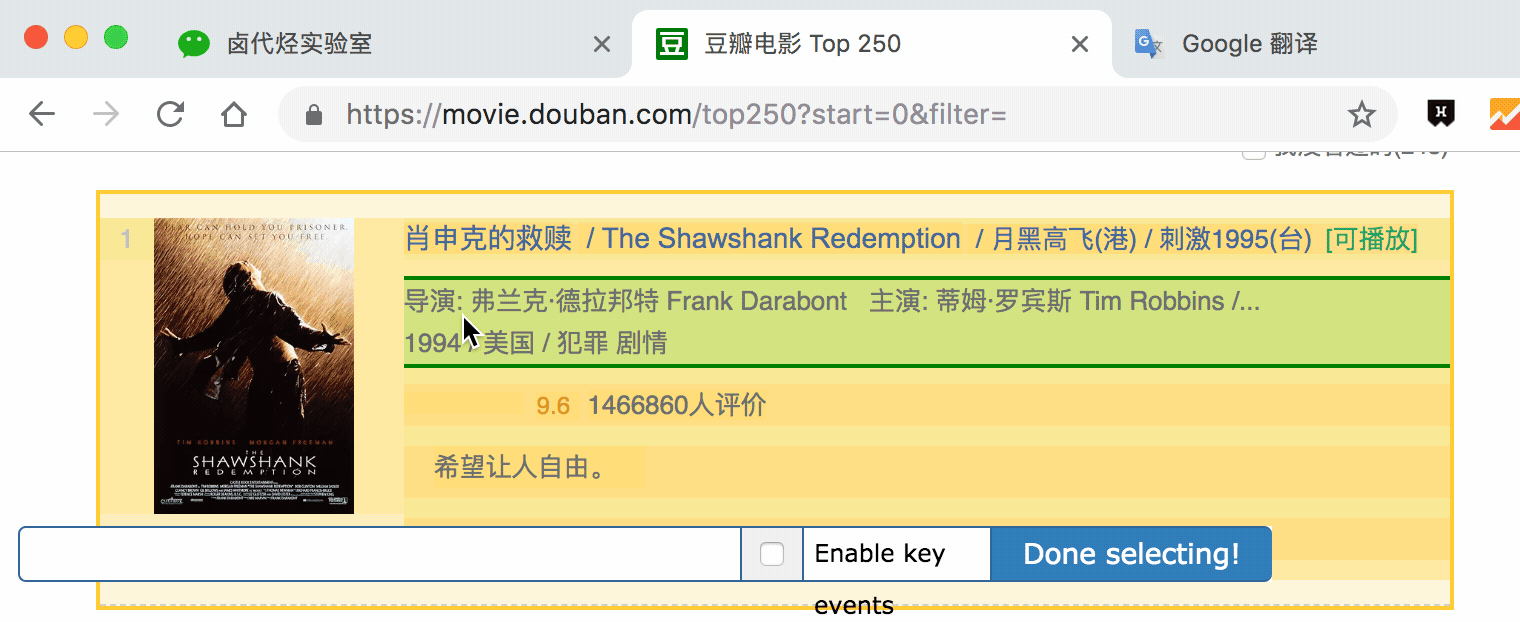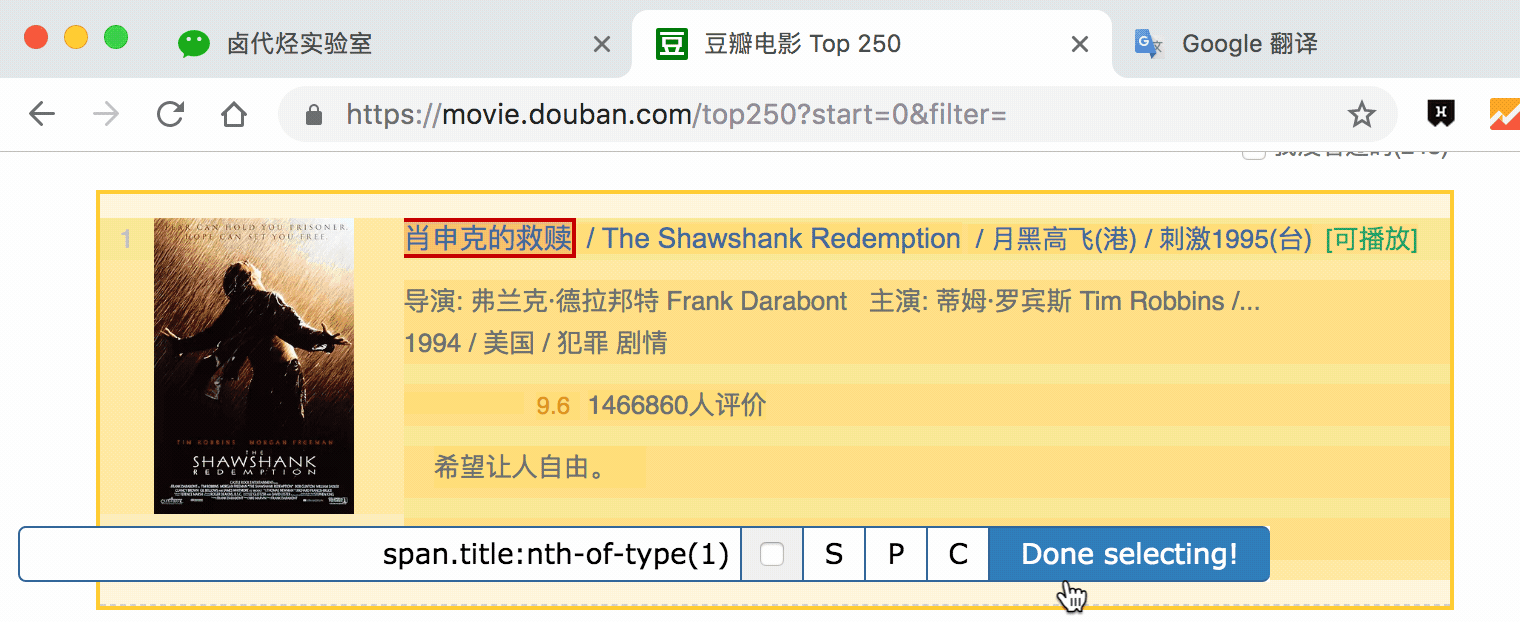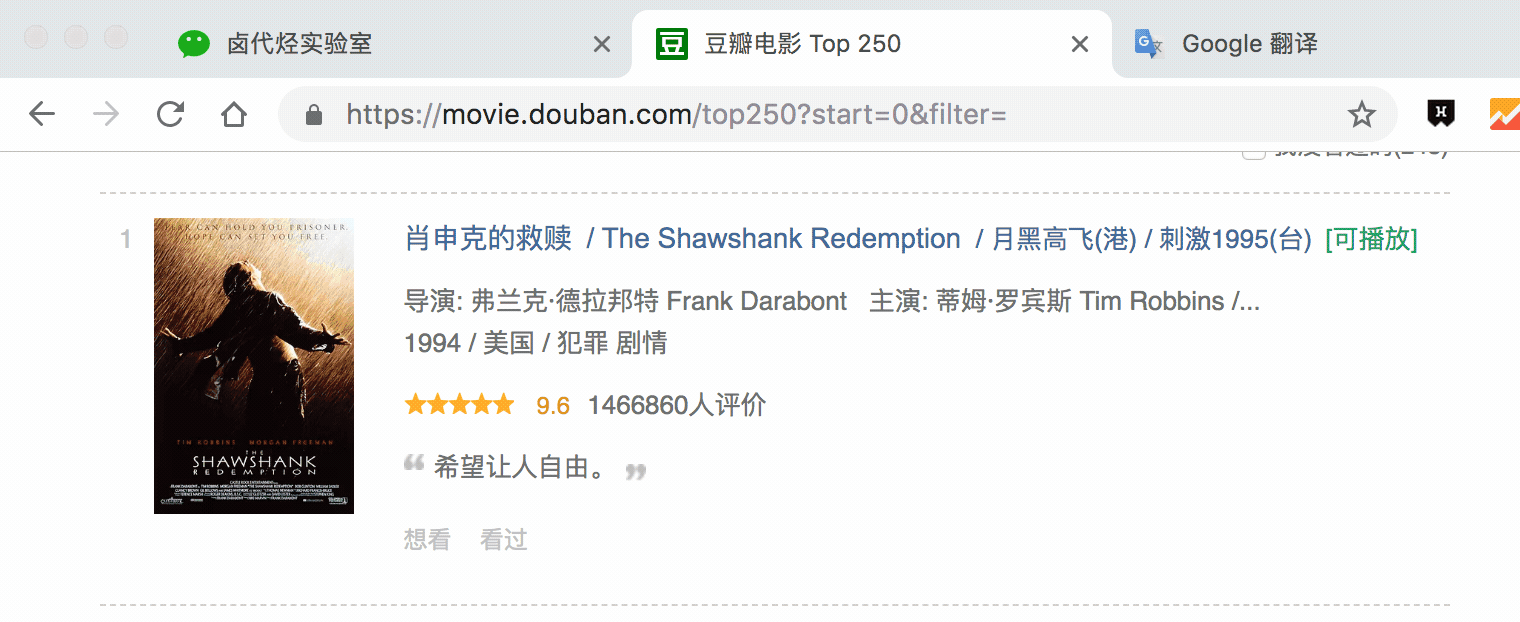
點選 Save selector 儲存選擇器後,我們再建立三個選擇器,分別選擇編號、評分和一句話影評,因為操作和上面一模一樣,我這裡就省略講解了。
排名編號:

評分:

一句話影評:

我們可以在面板裡觀察我們選擇的多個元素,一共有四個元素:分別為 name、number、score 和 review,型別都是 Text,不需要多選,父選擇器都是 container。

我們可以點選 點選 Stiemap top250 下的 selector graph,檢視我們爬蟲選擇元素的層級關係,確認正確後我們再點選 Stiemap top250 下的 Selectors,回到選擇器展示面板。
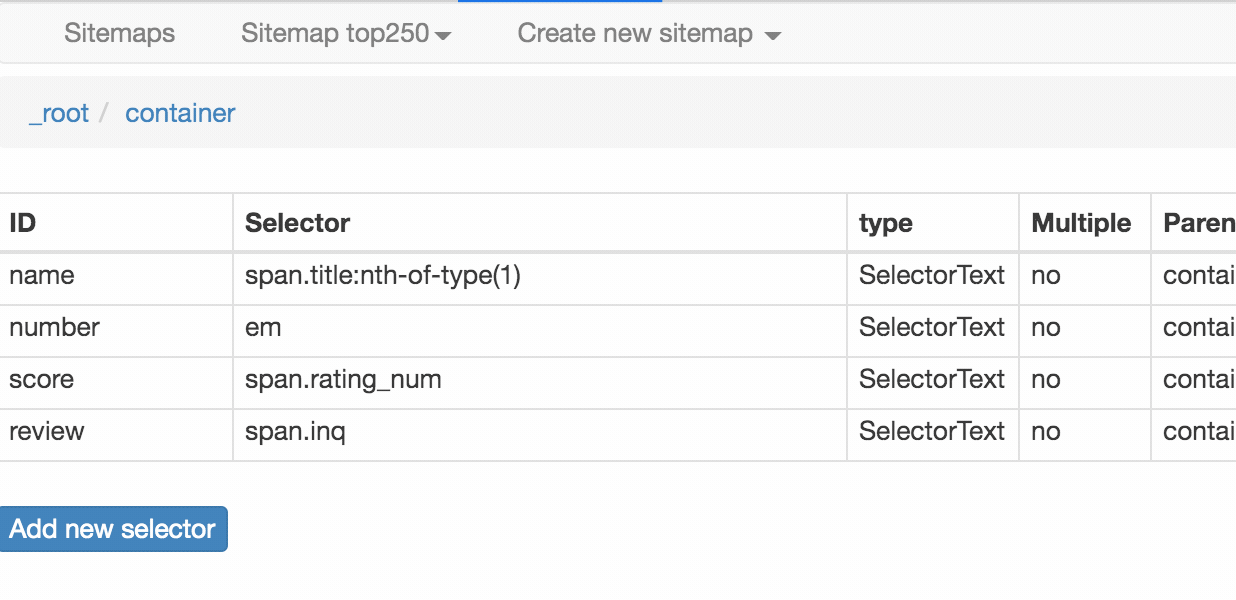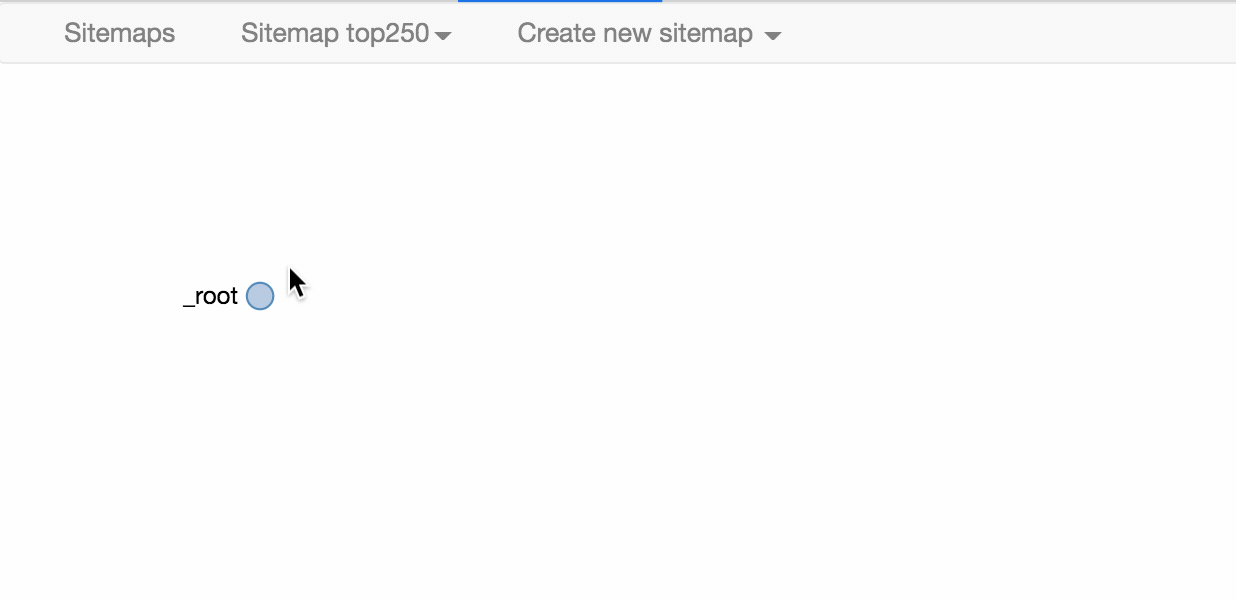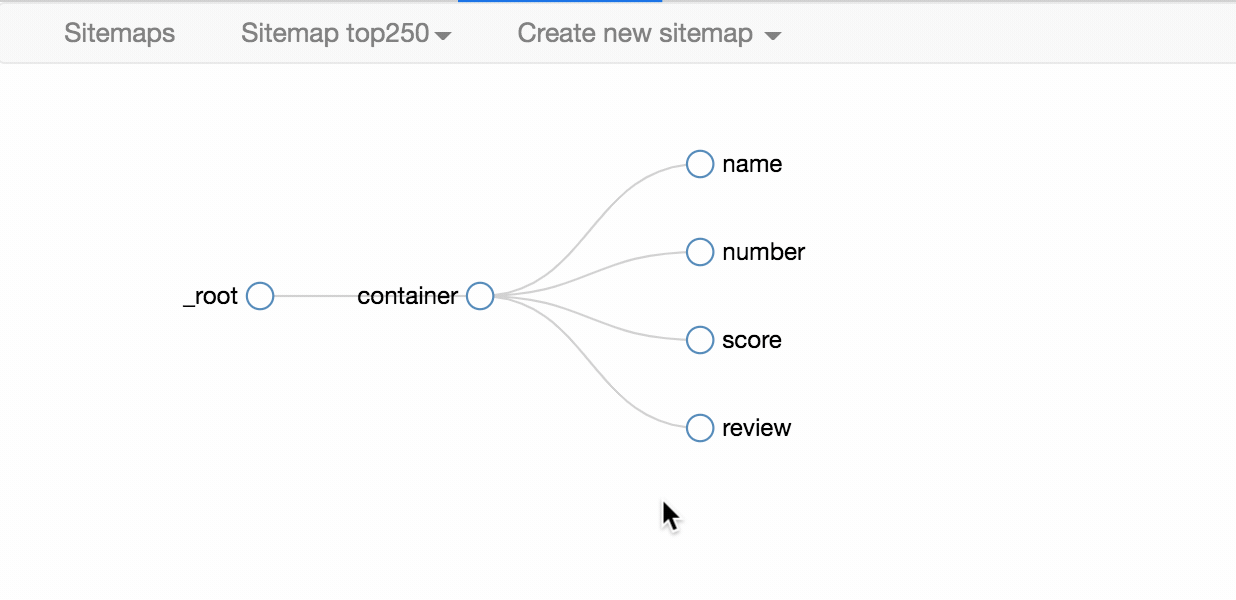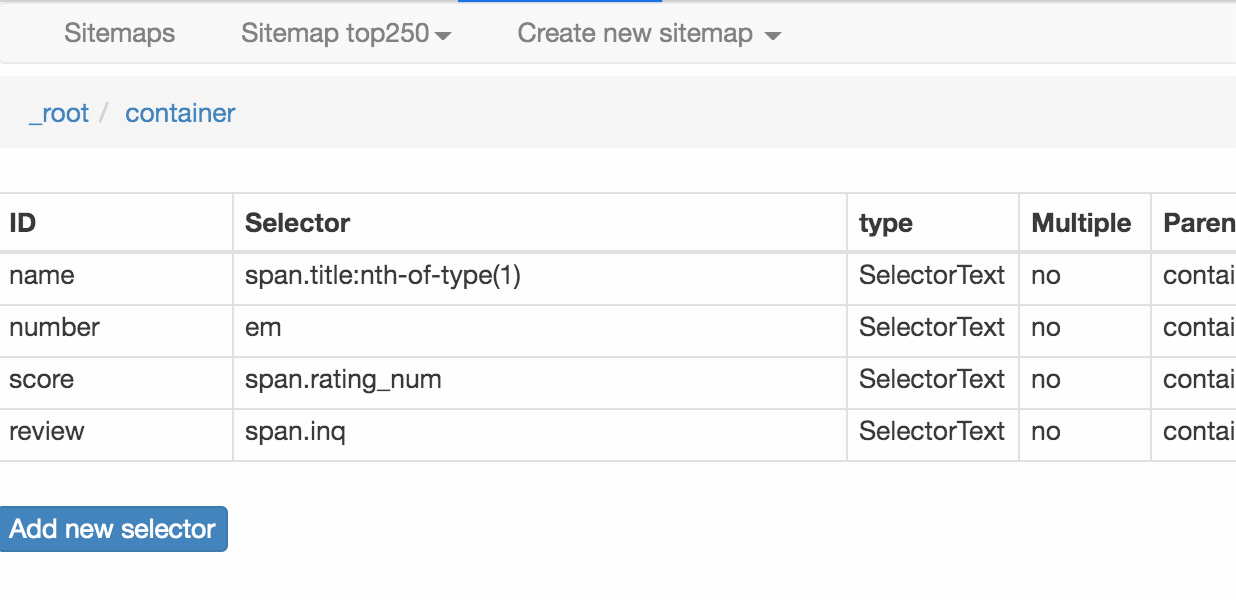
下圖就是我們這次爬蟲的層級關係,是不是和我們之前理論分析的一樣?

確認選擇無誤後,我們就可以抓取資料了,操作在 簡易資料分析 04 、 簡易資料分析 05 裡都說過了,忘記的朋友可以看舊文回顧一下。下圖是我抓取的資料:

還是和以前一樣,資料是亂序的,不過這個不要緊,因為排序屬於資料清洗的內容了,我們現在的專題是資料抓取。先把相關的知識點講完,再攻克下一個知識點,才是更合理的學習方式。
今天的內容其實還是比較多的,大家可以先消化一下,下一篇我們講講,如何抓取點選「載入更多」載入資料的網頁內容。
sitemap 分享:
這次的 sitemap 就分享給大家,大家可以匯入到 Web Scraper 中進行實驗,具體方法可以看我上一篇教程文章。
Sitemap:
{"_id":"top250","startUrl":["https://movie.douban.com/top250?start=[0-250:25]&filter="],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple":false,"regex":"","delay":0},{"id":"score","type":"SelectorText","parentSelectors":["container"],"selector":"span.rating_num","multiple":false,"regex":"","delay":0},{"id":"review","type":"SelectorText","parentSelectors":["container"],"selector":"span.inq","multiple":false,"regex":"","delay":0}]}
推薦閱讀:
簡易資料分析 04 | Web Scraper 初嘗--抓取豆瓣高分電影
簡易資料分析 05 | Web Scraper 翻頁——控制連結批量抓取資料

相關推薦
簡易資料分析 07 | Web Scraper 抓取多條內容
這是簡易資料分析系列的第 7 篇文章。 在第 4 篇文章裡,我講解了如何抓取單個網頁裡的單類資訊; 在第 5 篇文章裡,我講解了如何抓取多個網頁裡的單類資訊; 今天我們要講的是,如何抓取多個網頁裡的多類資訊。 這次的抓取是在簡易資料分析 05的基礎上進行的,所以我們一開始就解決了抓取多個網頁的問題,下面全
簡易資料分析 11 | Web Scraper 抓取表格資料
這是簡易資料分析系列的第 11 篇文章。 今天我們講講如何抓取網頁表格裡的資料。首先我們分析一下,網頁裡的經典表格是怎麼構成的。 First Name 所在的行比較特殊,是一個表格的表頭,表示資訊分類 2-5 行是表格的主體,展示分類內容 經典表格就這些知識點,沒了。下面我們寫個簡單的表格 Web
簡易資料分析 04 | Web Scraper 初嘗--抓取豆瓣高分電影
這是簡易資料分析系列的第 4 篇文章。 今天我們開始資料抓取的第一課,完成我們的第一個爬蟲。因為是剛剛開始,操作我會講的非常詳細,可能會有些囉嗦,希望各位不要嫌棄啊:) 有人之前可能學過一些爬蟲知識,總覺得這是個複雜的東西,什麼 HTTP、HTML、IP 池,在這裡我們都不考慮這些東西。一是小的資料量根本
簡易資料分析 09 | Web Scraper 自動控制抓取數量 & Web Scraper 父子選擇器
這是簡易資料分析系列的第 9 篇文章。 今天我們說說 Web Scraper 的一些小功能:自動控制 Web Scraper 抓取數量和 Web Scraper 的父子選擇器。 如何只抓取前 100 條資料? 如果跟著上篇教程一步一步做下來,你會發現這個爬蟲會一直運作,根本停不下來。網頁有 1000 條資
簡易資料分析 10 | Web Scraper 翻頁——抓取「滾動載入」型別網頁
這是簡易資料分析系列的第 10 篇文章。 友情提示:這一篇文章的內容較多,資訊量比較大,希望大家學習的時候多看幾遍。 我們在刷朋友圈刷微博的時候,總會強調一個『刷』字,因為看動態的時候,當把內容拉到螢幕末尾的時候,APP 就會自動載入下一頁的資料,從體驗上來看,資料會源源不斷的加載出來,永遠沒有盡頭。
簡易資料分析 12 | Web Scraper 翻頁——抓取分頁器翻頁的網頁
這是簡易資料分析系列的第 12 篇文章。 前面幾篇文章我們介紹了 Web Scraper 應對各種翻頁的解決方法,比如說修改網頁連結載入資料、點選“更多按鈕“載入資料和下拉自動載入資料。今天我們說說一種更常見的翻頁型別——分頁器。 本來想解釋一下啥叫分頁器,翻了一堆定義覺得很繁瑣,大家也不是第一年上網了,
簡易資料分析 13 | Web Scraper 高階用法——抓取二級頁面
這是簡易資料分析系列的第 13 篇文章。 不知不覺,web scraper 系列教程我已經寫了 10 篇了,這 10 篇內容,基本上覆蓋了 Web Scraper 大部分功能。今天的內容算這個系列的最後一篇文章了,下一章節我會開一個新坑,說說如何利用 Excel 對收集到的資料做一些格式化的處理和分析。
簡易資料分析 02 | Web Scraper 的下載與安裝
這是簡易資料分析系列的第 2 篇文章。 上篇說了資料分析在生活中的重要性,從這篇開始,我們就要進入分析的實戰內容了。資料分析資料分析,沒有資料怎麼分析?所以我們首先要學會採集資料。 我調研了很多采集資料的軟體,綜合評定下來發現最好用的還是 Web Scraper,這是一款 Chrome 瀏覽器外掛。
簡易資料分析 08 | Web Scraper 翻頁——點選「更多按鈕」翻頁
這是簡易資料分析系列的第 8 篇文章。 我們在Web Scraper 翻頁——控制連結批量抓取資料一文中,介紹了控制網頁連結批量抓取資料的辦法。 但是你在預覽一些網站時,會發現隨著網頁的下拉,你需要點選類似於「載入更多」的按鈕去獲取資料,而網頁連結一直沒有變化。 所以控制連結批量抓去資料的方案失效了,所以
web scraper 抓取資料並做簡單資料分析
其實 web scraper 說到底就是那點兒東西,所有的網站都是大同小異,但是都還不同。這也是好多同學總是遇到問題的原因。因為沒有統一的模板可用,需要理解了 web scraper 的原理並且對目標網站加以分析才可以。 今天再介紹一篇關於 web scraper 抓取資料的文章,除了 web scraper
Web Scraper 高階用法——抓取屬性資訊 | 簡易資料分析 16
這是簡易資料分析系列的第 16 篇文章。 這期課程我們講一個用的較少的 Web Scraper 功能——抓取屬性資訊。 網頁在展示資訊的時候,除了我們看到的內容,其實還有很多隱藏的資訊。我們拿豆瓣電影250舉個例子: 電影圖片正常顯示的時候是這個樣子: 如果網路異常,圖片載入失敗,就會顯示圖片的預設文
Web Scraper 翻頁——利用 Link 選擇器翻頁 | 簡易資料分析 14
這是簡易資料分析系列的第 14 篇文章。 今天我們還來聊聊 Web Scraper 翻頁的技巧。 這次的更新是受一位讀者啟發的,他當時想用 Web scraper 爬取一個分頁器分頁的網頁,卻發現我之前介紹的分頁器翻頁方法不管用。我研究了一下才發現我漏講了一種很常見的翻頁場景。 在 web scraper
Web Scraper 高階用法——利用正則表示式篩選文字資訊 | 簡易資料分析 17
 這是簡易資料分析系列的**第 17 篇**文章。 學習了這麼多課,我想大家已經發現了,web scraper 主要是用來爬取**
分析Ajax請求並抓取今日頭條街拍美圖
mage param word esp 信息 ons import src on() 準備工作 requests、Beautiful Soup、MongoDB 抓取分析 在抓取之前首先分析抓取的邏輯,打開今日頭條的首頁https://www.toutiao.com/如
Web站點抓取工具webhttrack
bubuko 能夠 image 啟動 很好 http 技術 AC 一個 近來發現Ubuntu下一個很好用的web站點抓取工具webhttrack,能夠將給定網址的站點抓取到本地的目錄中,並實現離線瀏覽,很實用。 1、安裝webhttrack ubuntu 16.04的官方源
cgmodel簡易資料分析
CG模型網(www.cgmodel.com / www.cgmodel.cn)是一個以3D模型為主,針對所有CG設計行業使用者的互動、展示平臺。2006年6月創立於湖南長沙,現有註冊設計師/藝術家120萬,網站秉承“分享”的理念,通過整合優質的模型資源,
資料分析07
基於傅立葉變換的頻域濾波 ____________________IFFT_____________________ |
python資料分析07--matplotlib繪圖和視覺化
python資料分析07–matplotlib繪圖和視覺化 一、簡介 資訊視覺化(也叫繪圖)是資料分析中最重要的工作之一。它可能是探索過程的一部分,例 如,幫助我們找出異常值、必要的資料轉換、得出有關模型的idea等。另外,做一個可互動的 資料視覺化也許是工作的最終目標。 m
Python資料抓取——多執行緒,非同步
作業系統可以同時執行多個任務。首先,考慮單核CPU是如何執行多工的:作業系統輪流讓各個任務交替執行,任務1執行0.01秒,切換到任務2,任務2執行0.01秒,再切換到任務3,執行0.01秒……這樣反覆執行下去。表面上看,每個任務都是交替執行的,但是,由於CP
利用charles 抓取ios app的https資料包-----軟體配置和抓取步驟
背景:最近在做資料快取相關的工作;我們的裝置是放在高鐵裡面的,主要是提供wifi服務。然而我們的wifi是由sim卡4g網路撥號提供的,使用者在上網時需要下載我們的APP:掌上高鐵;所以領導提出一個要求,要在自己伺服器做一個快取,使用者在ios app-store下載掌上高