
簡易資料分析 09 | Web Scraper 自動控制抓取數量 & Web Scraper 父子選擇器

這是簡易資料分析系列的第 9 篇文章。
今天我們說說 Web Scraper 的一些小功能:自動控制 Web Scraper 抓取數量和 Web Scraper 的父子選擇器。
如何只抓取前 100 條資料?
如果跟著上篇教程一步一步做下來,你會發現這個爬蟲會一直運作,根本停不下來。網頁有 1000 條資料,他就會抓取 1000 條,有 10W 條,就會抓取 10W 條。如果我們的需求很小,只想抓取前 200 條怎麼辦?
如果你手動關閉抓取資料的網頁,就會發現資料全部丟失,一條都沒有儲存下來,所以說這種暴力的方式不可取。我們目前有兩種方式停止 Web Scraper 的抓取。
1.斷網大法
當你覺得資料抓的差不多了,直接把電腦的網路斷了。網路一斷瀏覽器就載入不了資料,Web Scraper 就會誤以為資料抓取完了,然後它會自動停止自動儲存。
斷網大法簡單粗暴,雖不優雅,但是有效。缺點就是你得在旁邊盯著,關鍵點手動操作,不是很智慧。
2.通過資料編號控制條數
比如說上篇文章的少數派熱門文章爬蟲,container 的 Selector 為 dl.article-card,他會抓取網頁裡所有編號為 dl.article-card 的資料。

我們可以在這個 Selector 後加一個 :nth-of-type(-n+100),表示抓取前 100 條資料,前 200 條就為 :nth-of-type(-n+200),1000 條為 :nth-of-type(-n+1000),以此類推。

這樣,我們就可以通過控制資料的編號來控制需要抓取的資料。
抓取連結資料時,頁面跳轉怎麼辦?
在上文抓取資料時,可能會遇到一些問題,比如說抓取標題時,標題本身就是個超連結,點選圈選內容後打開了新的網頁,干擾我們確定圈選的內容,體驗不是很好。
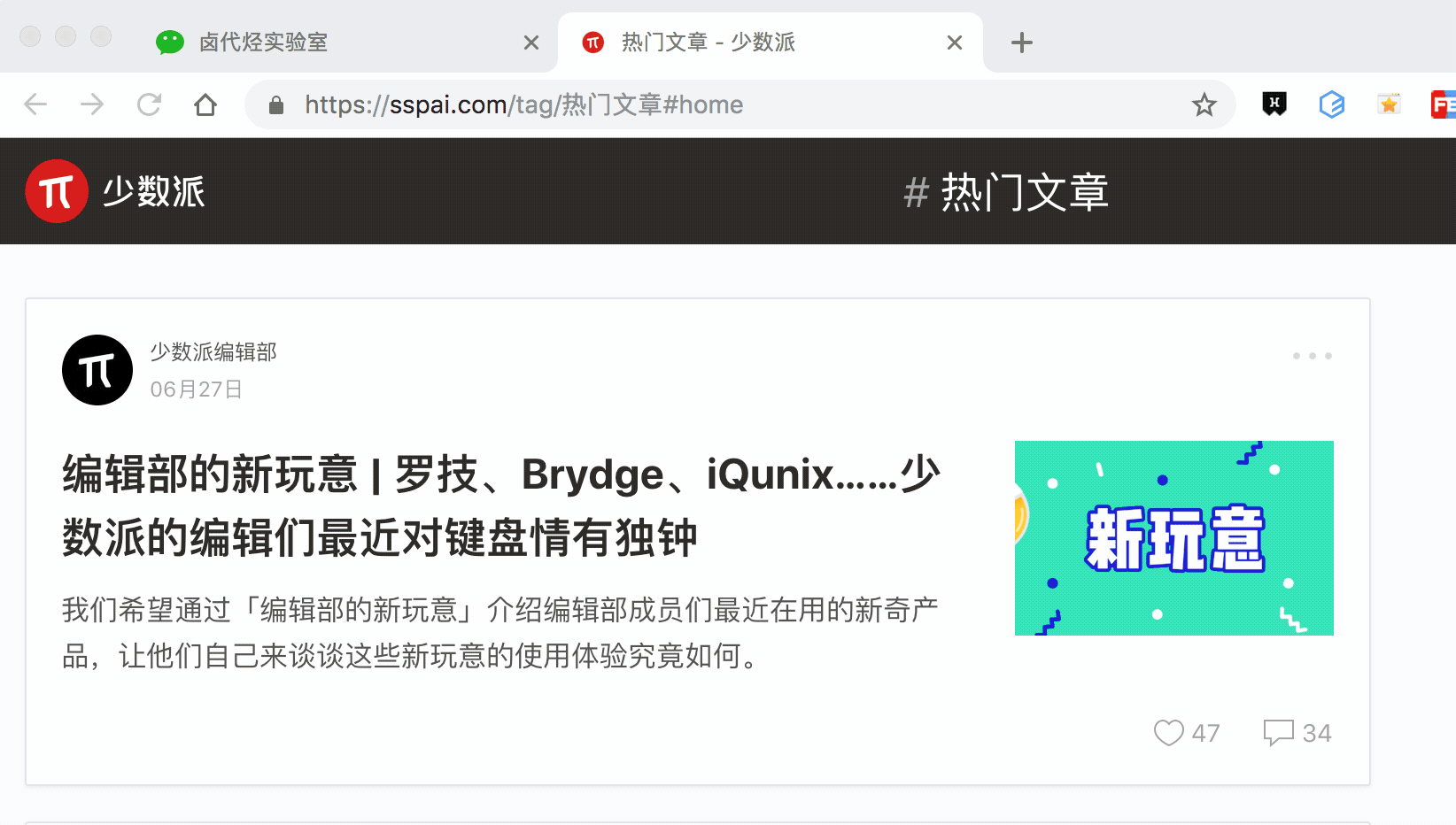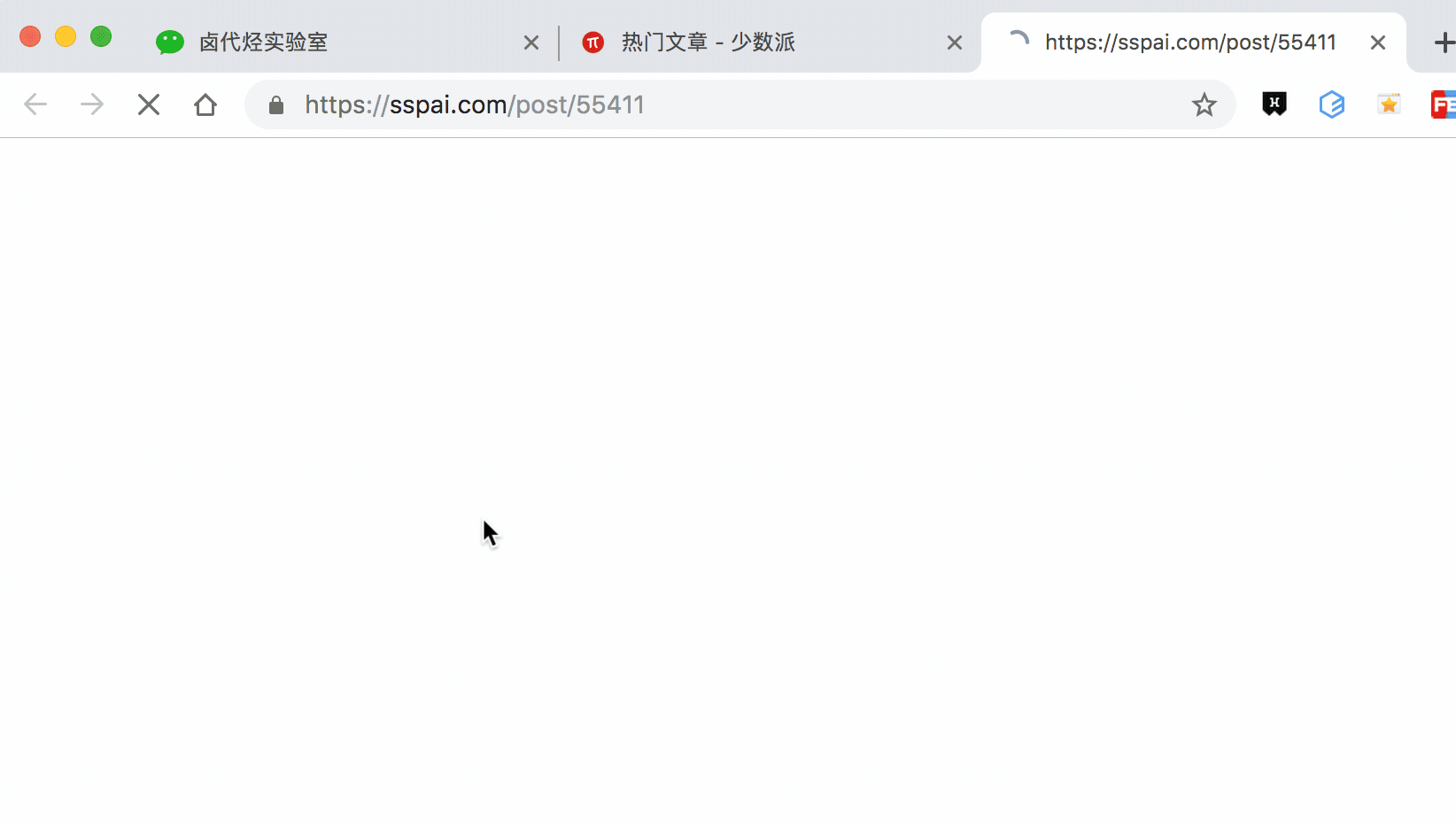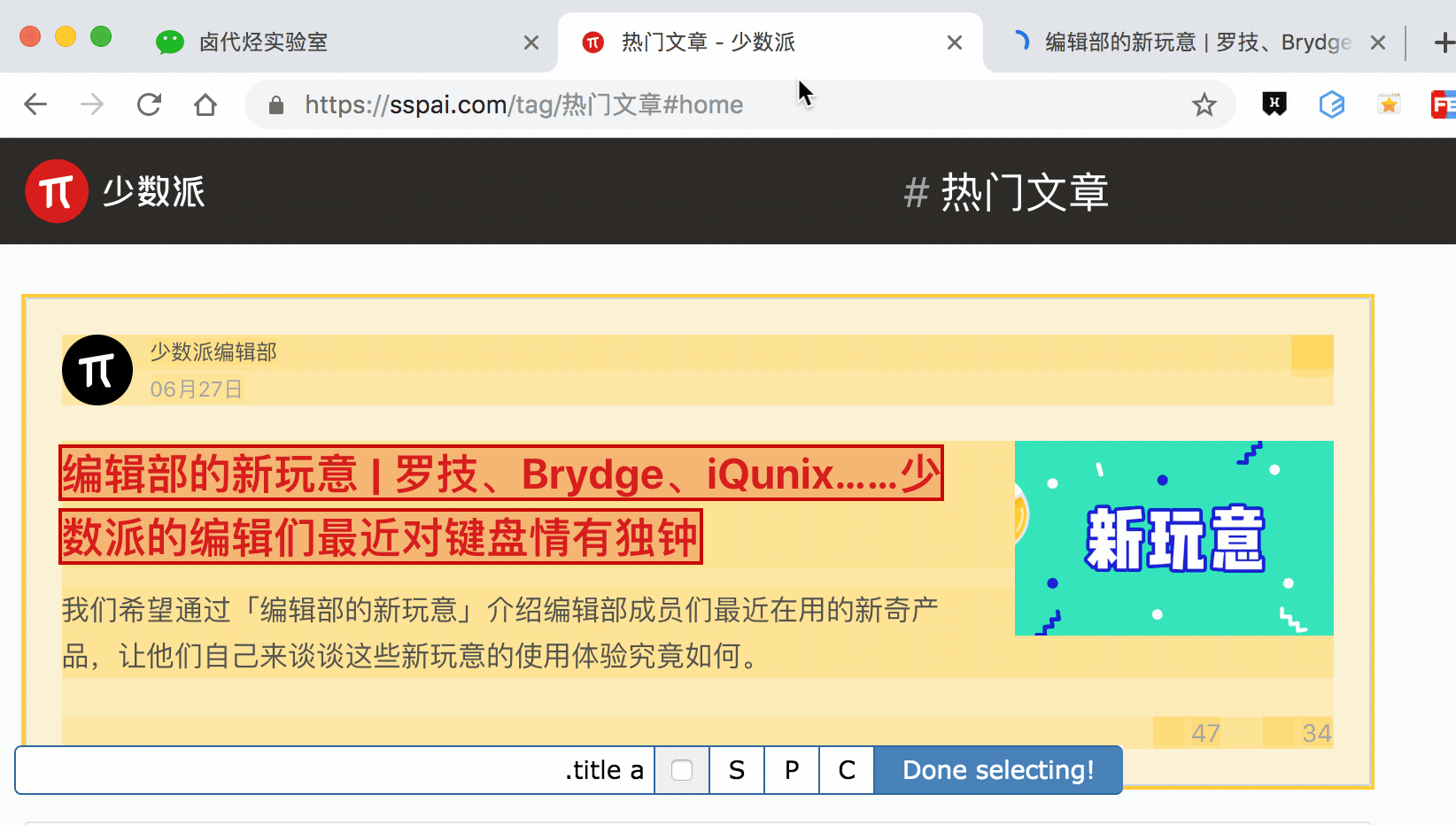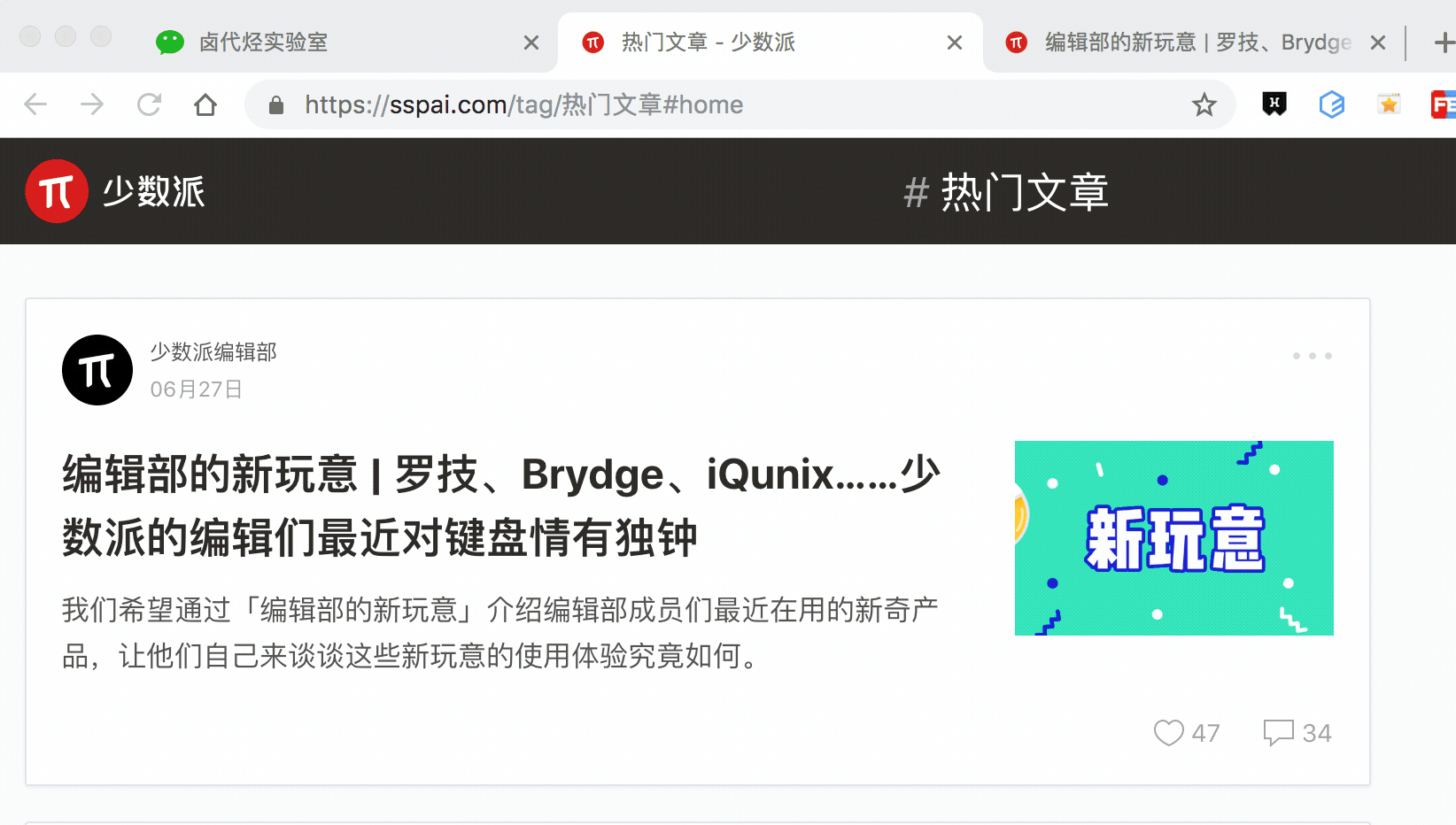
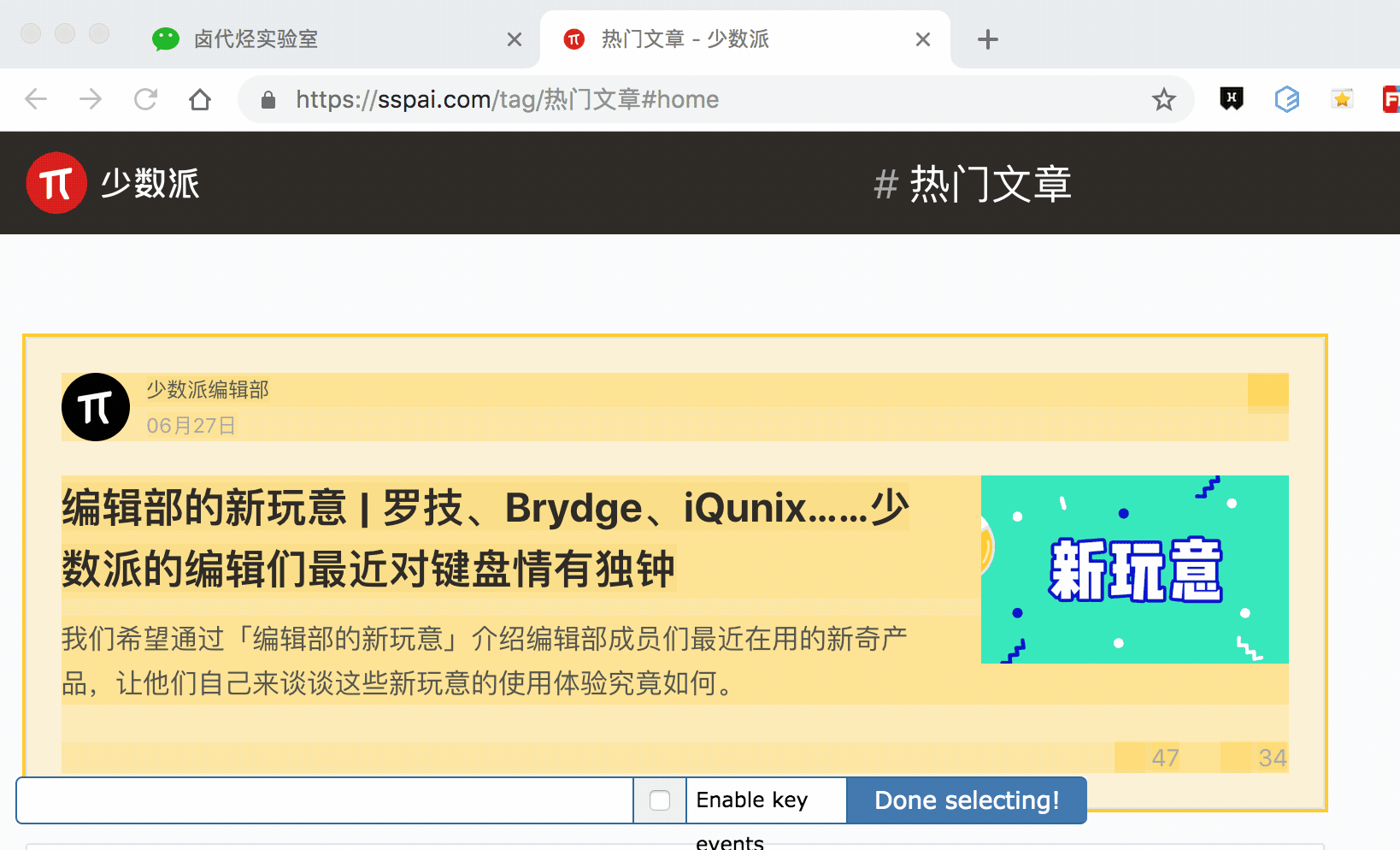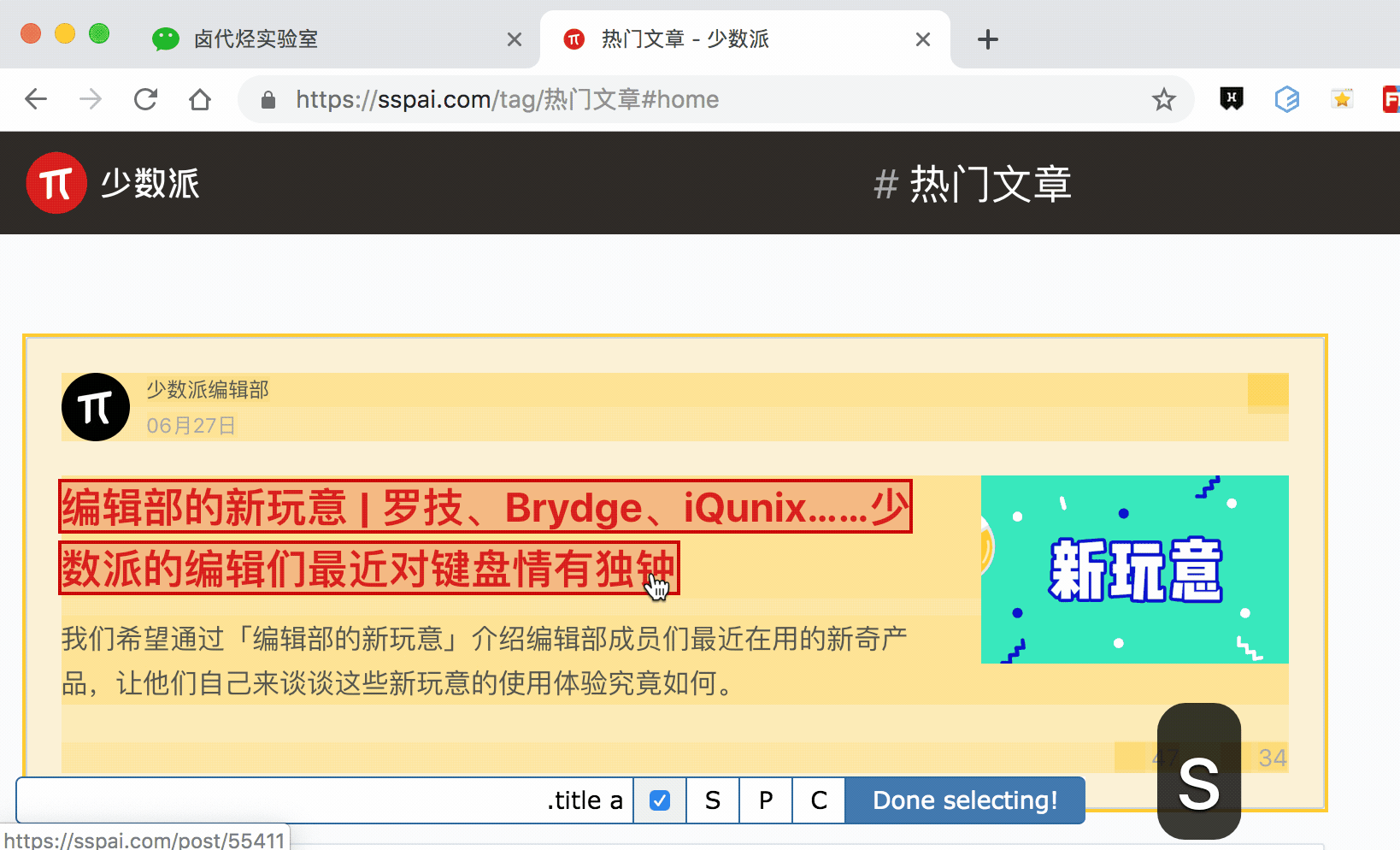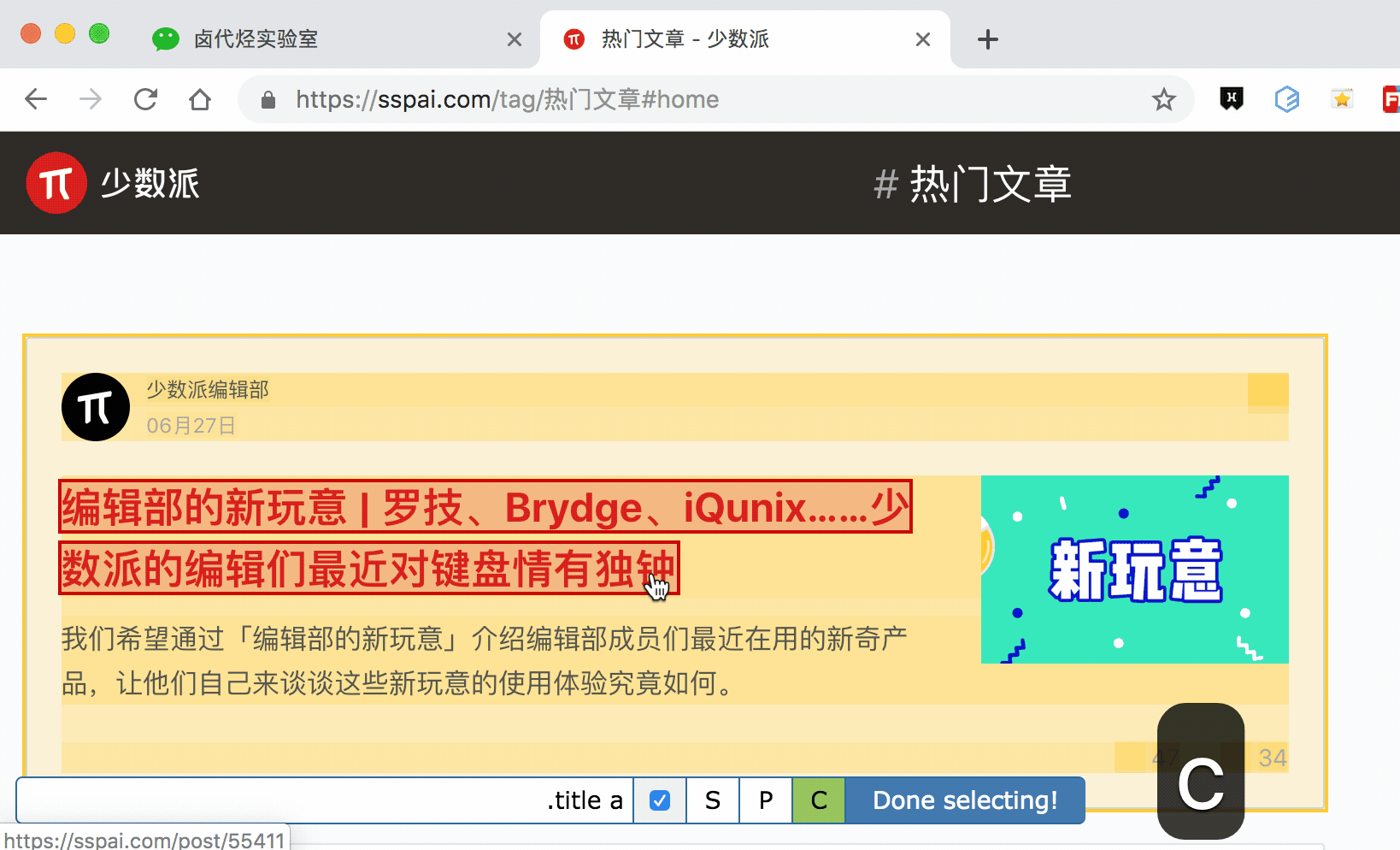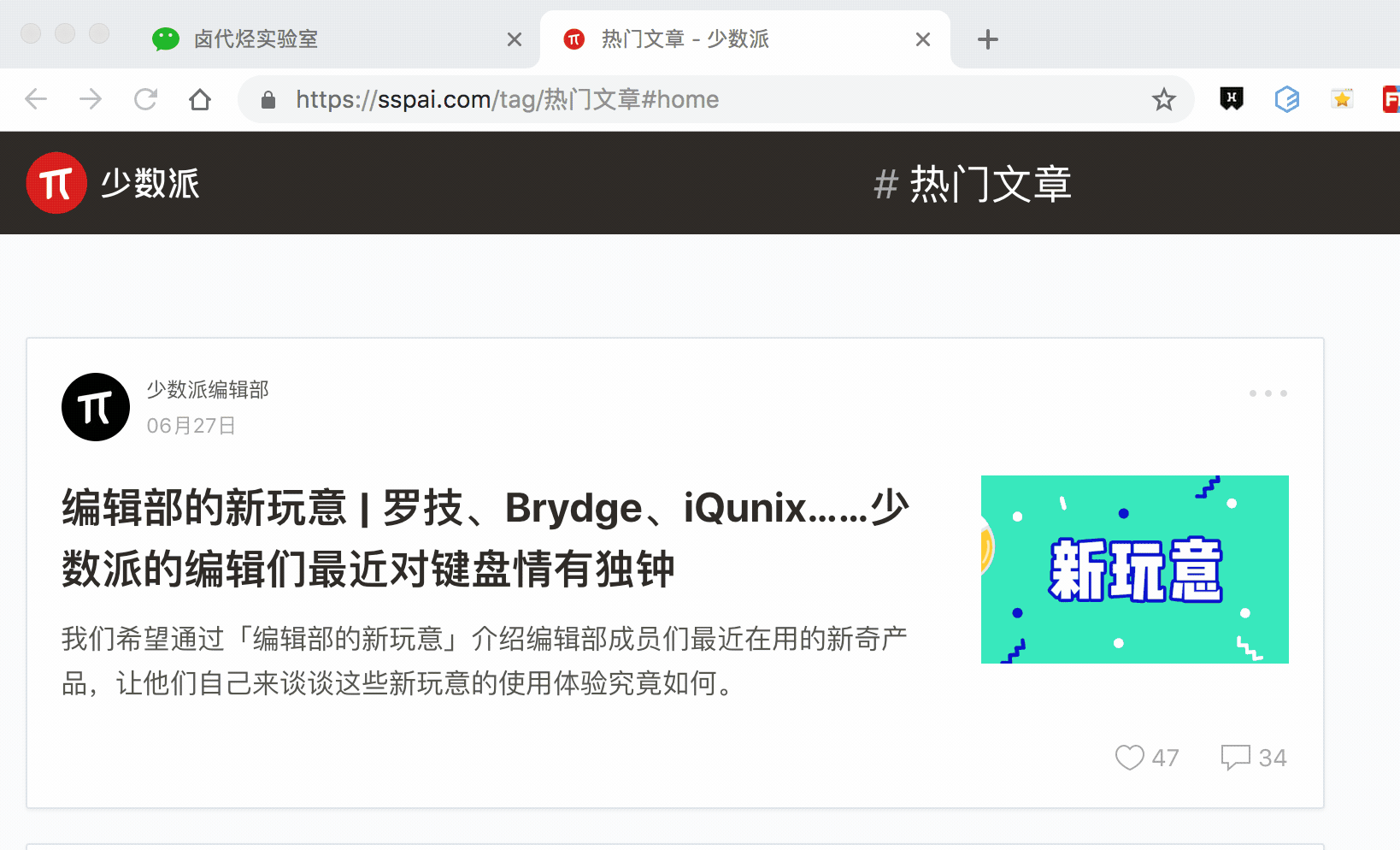
其實 Web scraper 提供了對應的解決方案,那就是通過鍵盤來選擇元素,這樣就不會觸發點選開啟新的網頁的問題了。具體的操作面板如下所示,就是我們點選 Done Selecting 的那個控制條。

我們把單選按鈕選擇後,會出現 S ,P, C 三個字元,意思分別如下:

S:Select,按下鍵盤的 S 鍵,選擇選中的元素
P:Parent,按下鍵盤的 P 鍵,選擇選中元素的父節點
C:Child,按下鍵盤的 C 鍵,選擇選中元素的子節點
我們分別演示一下,首先是通過 S 鍵選擇標題節點:
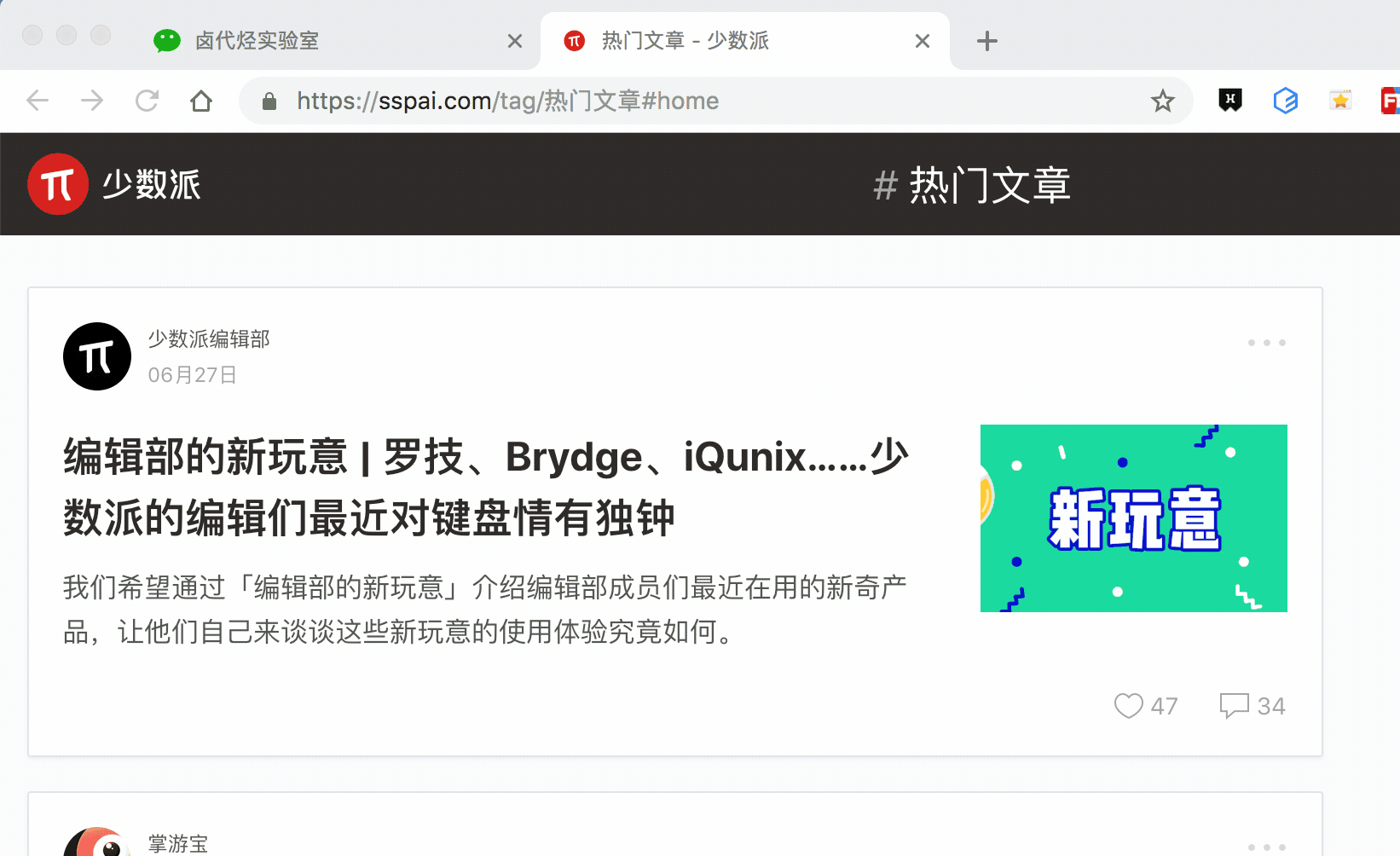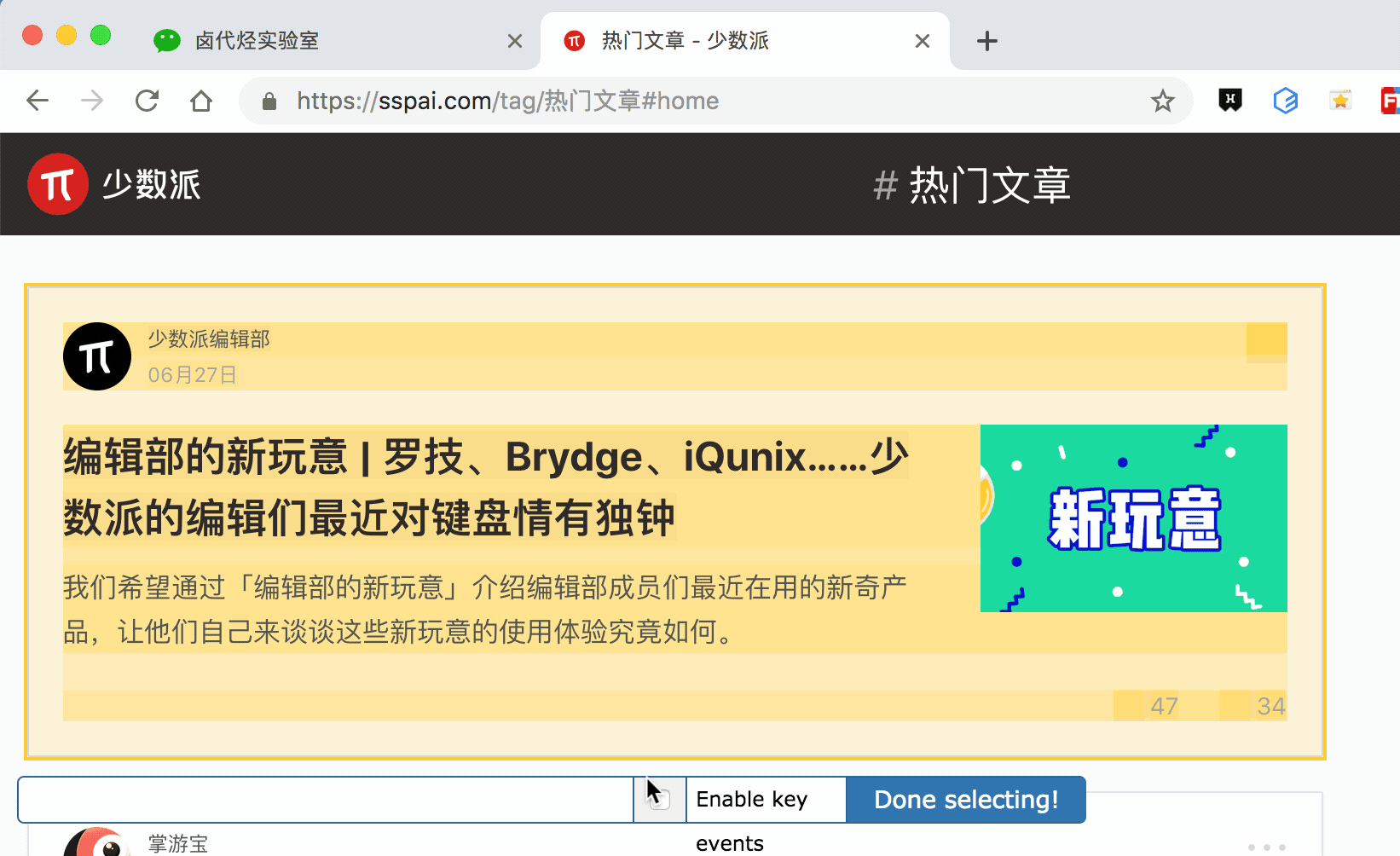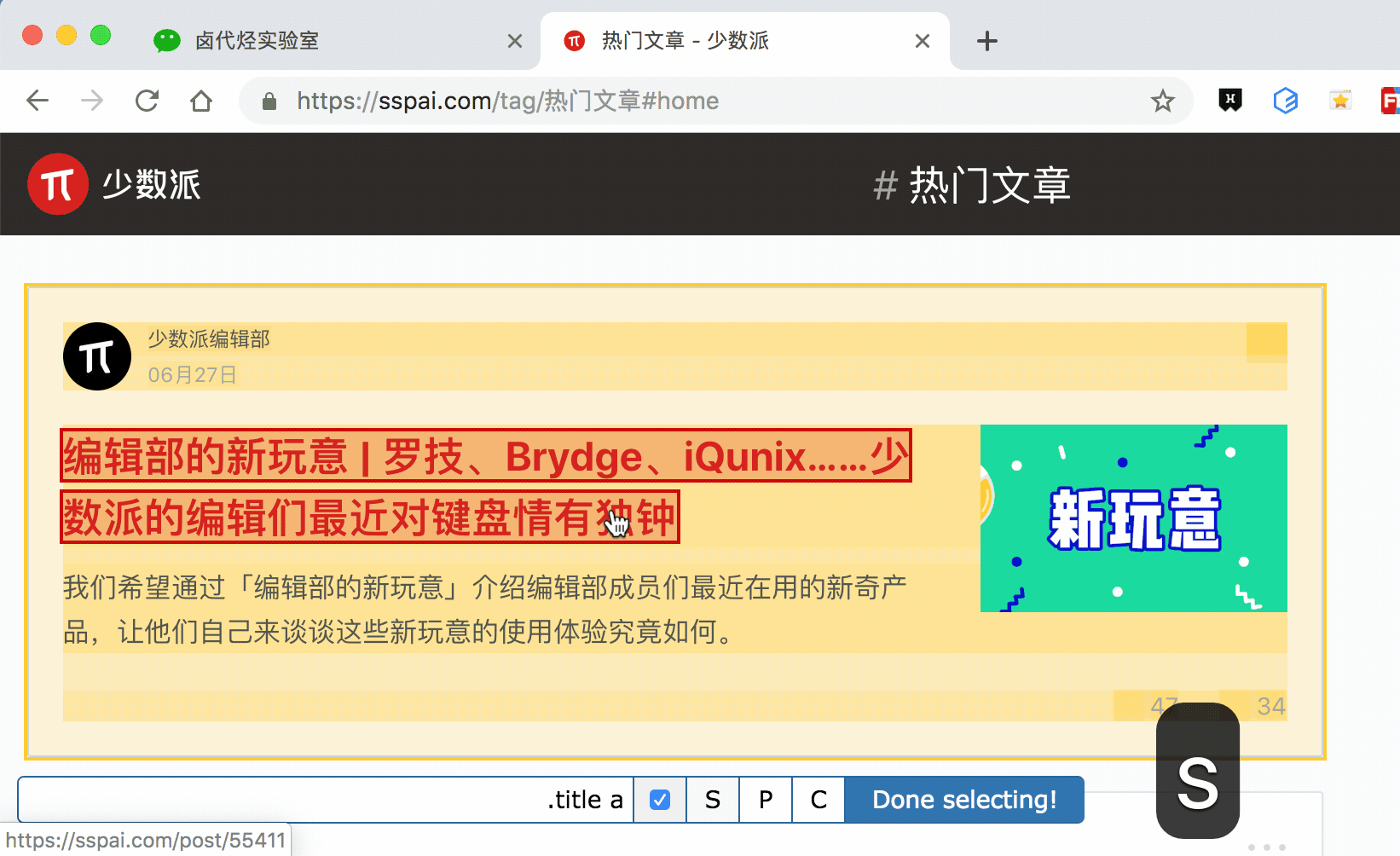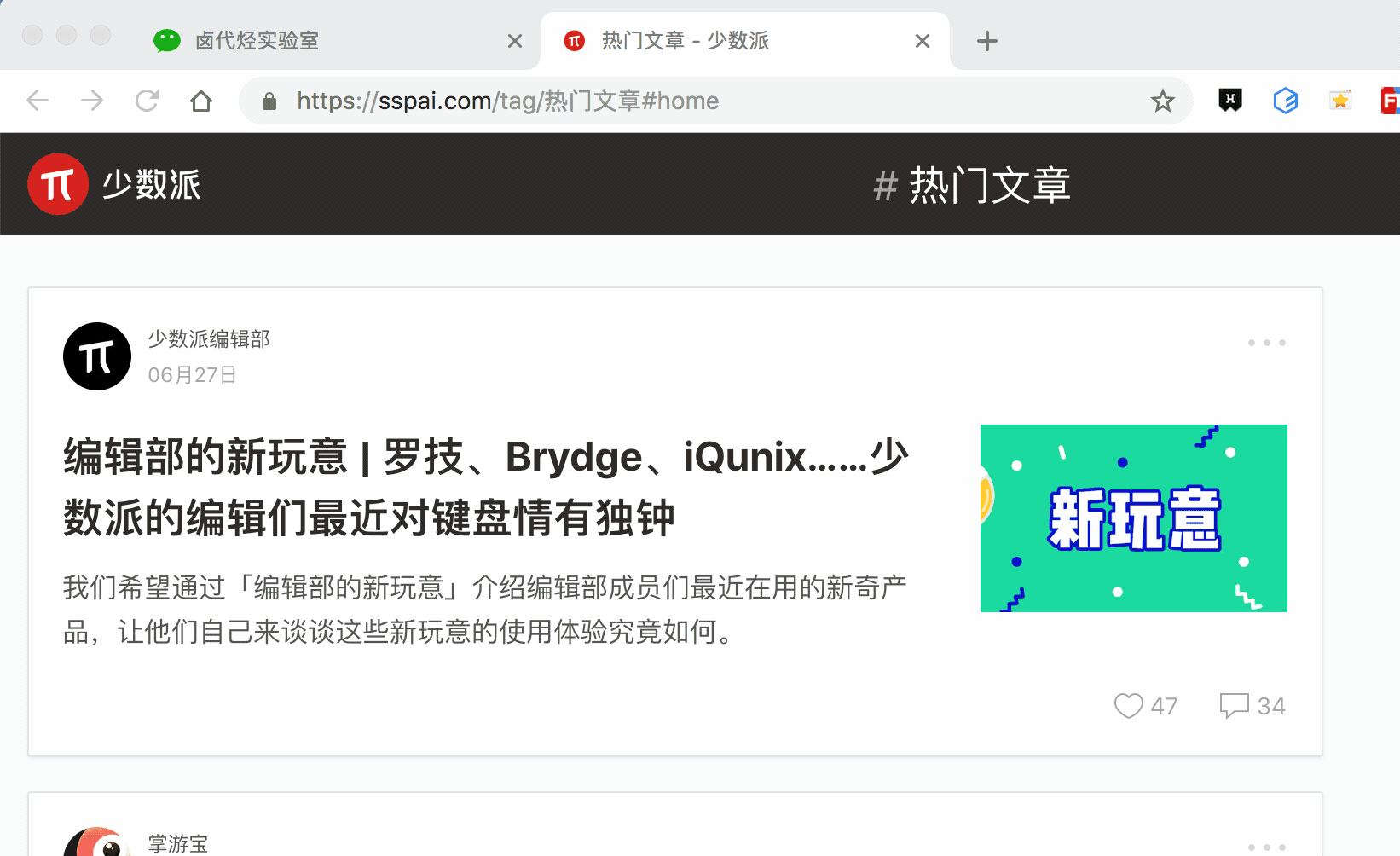
我們對比上個動圖,會發現節點選中變紅的同時,並沒有開啟新的網頁。
如何抓取選中元素的父節點 or 子節點?
通過 P 鍵和 C 鍵選擇父節點和子節點:
按壓 P 鍵後,我們可以明顯看到我們選擇的區域大了一圈,再按 C 鍵後,選擇區域又小了一圈,這個就是父子選擇器的功能。
這期介紹了 Web Scraper 的兩個使用小技巧,下期我們說說 Web Scraper 如何抓取無限滾動的網頁。
推薦閱讀:
簡易資料分析 08 | Web Scraper 翻頁——點選「更多按鈕」翻