
Web Scraper 高階用法——抓取屬性資訊 | 簡易資料分析 16

這是簡易資料分析系列的第 16 篇文章。
這期課程我們講一個用的較少的 Web Scraper 功能——抓取屬性資訊。
網頁在展示資訊的時候,除了我們看到的內容,其實還有很多隱藏的資訊。我們拿豆瓣電影250舉個例子:
電影圖片正常顯示的時候是這個樣子:

如果網路異常,圖片載入失敗,就會顯示圖片的預設文案,這個文案其實就是這個圖片的屬性資訊:

我們檢視一下這個結構的 HTML(檢視方法可見 CSS 選擇器的使用的第一節內容),就會發現圖片的預設文案其實就是這個 <img/> 標籤的 alt 屬性:

我們可以看一下 HTML 文件裡對 alt 屬性的描述:
alt 屬性是一個必需的屬性,它規定在影象無法顯示時的替代文字
在 web scraper 裡,我們可以利用 Element attribute 屬性來抓取這種屬性資訊。
因為這次的內容比較簡單,新建 sitemap 這一步我就先省略了,我們直接上來使用 Element attribute 抓取資料。
我們把 Type 選為 Element attribute,然後用 Selector 選中圖片這個元素:
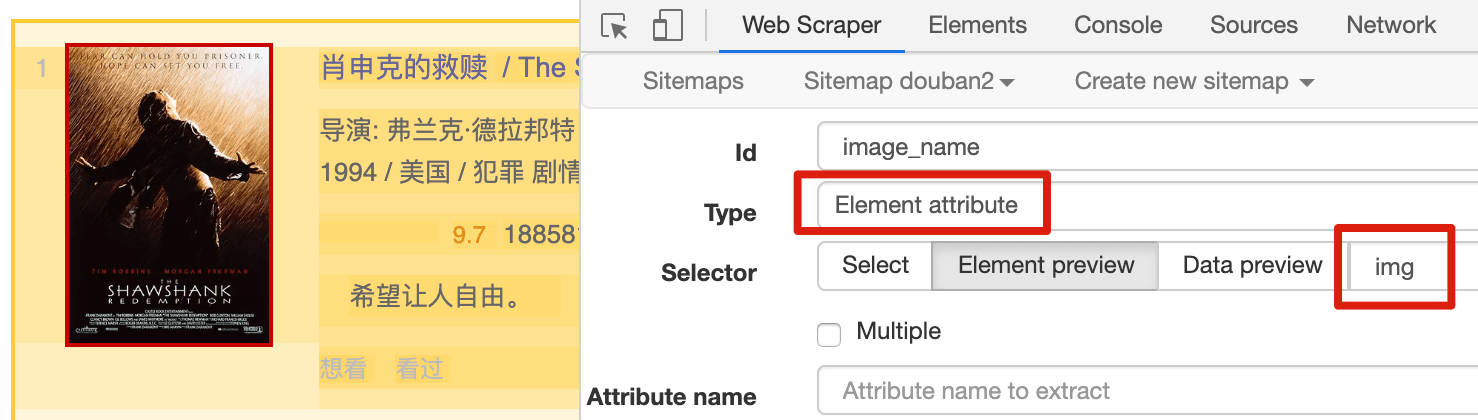
Element attribute 會多一個選項——Attribute name,我們在這個輸入框裡輸入我們要抓取的屬性名字。
觀察一下這個 img 標籤的屬性,有 alt(替換文字)、width(圖片寬度)和 src(圖片連結)3 種:

這裡我先輸入 alt

還可以輸入 src,表示抓取圖片的連結:

也可以輸入 width,抓取圖片寬度:

通過 Element attribute 這個選擇器,我們就可以抓取一些網頁沒有直接展示出來的資料資訊,非常的方便。
sitemap 分享
{"_id":"douban2","startUrl":["https://movie.douban.com/top250?start=0&filter="],"selectors":[{"id":"ele","type":"SelectorElement","parentSelectors":["_root"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"image_name","type":"SelectorElementAttribute","parentSelectors":["ele"],"selector":"img","multiple":false,"extractAttribute":"alt","delay":0}]}
推薦閱讀
Web Scraper 高階用法——CSS 選擇器的使用 | 簡易資料分析 15
HTML img 標籤的 alt 屬性
聯絡我
因為文章發在各大平臺上,賬號較多不能及時回覆評論和私信,有問題可關注公眾號 ——「鹵代烴實驗室」,(或 wx 搜尋 sky_chx)關注上車防失聯。

相關推薦
Web Scraper 高階用法——抓取屬性資訊 | 簡易資料分析 16
這是簡易資料分析系列的第 16 篇文章。 這期課程我們講一個用的較少的 Web Scraper 功能——抓取屬性資訊。 網頁在展示資訊的時候,除了我們看到的內容,其實還有很多隱藏的資訊。我們拿豆瓣電影250舉個例子: 電影圖片正常顯示的時候是這個樣子: 如果網路異常,圖片載入失敗,就會顯示圖片的預設文
簡易資料分析 13 | Web Scraper 高階用法——抓取二級頁面
這是簡易資料分析系列的第 13 篇文章。 不知不覺,web scraper 系列教程我已經寫了 10 篇了,這 10 篇內容,基本上覆蓋了 Web Scraper 大部分功能。今天的內容算這個系列的最後一篇文章了,下一章節我會開一個新坑,說說如何利用 Excel 對收集到的資料做一些格式化的處理和分析。
Web Scraper 高階用法——利用正則表示式篩選文字資訊 | 簡易資料分析 17
 這是簡易資料分析系列的**第 17 篇**文章。 學習了這麼多課,我想大家已經發現了,web scraper 主要是用來爬取**
簡易資料分析 04 | Web Scraper 初嘗--抓取豆瓣高分電影
這是簡易資料分析系列的第 4 篇文章。 今天我們開始資料抓取的第一課,完成我們的第一個爬蟲。因為是剛剛開始,操作我會講的非常詳細,可能會有些囉嗦,希望各位不要嫌棄啊:) 有人之前可能學過一些爬蟲知識,總覺得這是個複雜的東西,什麼 HTTP、HTML、IP 池,在這裡我們都不考慮這些東西。一是小的資料量根本
簡易資料分析 09 | Web Scraper 自動控制抓取數量 & Web Scraper 父子選擇器
這是簡易資料分析系列的第 9 篇文章。 今天我們說說 Web Scraper 的一些小功能:自動控制 Web Scraper 抓取數量和 Web Scraper 的父子選擇器。 如何只抓取前 100 條資料? 如果跟著上篇教程一步一步做下來,你會發現這個爬蟲會一直運作,根本停不下來。網頁有 1000 條資
簡易資料分析 10 | Web Scraper 翻頁——抓取「滾動載入」型別網頁
這是簡易資料分析系列的第 10 篇文章。 友情提示:這一篇文章的內容較多,資訊量比較大,希望大家學習的時候多看幾遍。 我們在刷朋友圈刷微博的時候,總會強調一個『刷』字,因為看動態的時候,當把內容拉到螢幕末尾的時候,APP 就會自動載入下一頁的資料,從體驗上來看,資料會源源不斷的加載出來,永遠沒有盡頭。
簡易資料分析 12 | Web Scraper 翻頁——抓取分頁器翻頁的網頁
這是簡易資料分析系列的第 12 篇文章。 前面幾篇文章我們介紹了 Web Scraper 應對各種翻頁的解決方法,比如說修改網頁連結載入資料、點選“更多按鈕“載入資料和下拉自動載入資料。今天我們說說一種更常見的翻頁型別——分頁器。 本來想解釋一下啥叫分頁器,翻了一堆定義覺得很繁瑣,大家也不是第一年上網了,
淘寶爬取商品資訊以及資料分析
爬取淘寶商品 專案內容 案例選擇>>商品類目:沙發 數量:共100頁 4400商品 篩選條件:天貓、銷量從高到低、價格500元以上 專案目的 對商品標題進行文字分析,詞雲視覺化 不同關鍵詞word對應的sales的統計分析
簡易資料分析 07 | Web Scraper 抓取多條內容
這是簡易資料分析系列的第 7 篇文章。 在第 4 篇文章裡,我講解了如何抓取單個網頁裡的單類資訊; 在第 5 篇文章裡,我講解了如何抓取多個網頁裡的單類資訊; 今天我們要講的是,如何抓取多個網頁裡的多類資訊。 這次的抓取是在簡易資料分析 05的基礎上進行的,所以我們一開始就解決了抓取多個網頁的問題,下面全
簡易資料分析 11 | Web Scraper 抓取表格資料
這是簡易資料分析系列的第 11 篇文章。 今天我們講講如何抓取網頁表格裡的資料。首先我們分析一下,網頁裡的經典表格是怎麼構成的。 First Name 所在的行比較特殊,是一個表格的表頭,表示資訊分類 2-5 行是表格的主體,展示分類內容 經典表格就這些知識點,沒了。下面我們寫個簡單的表格 Web
Python網路爬蟲之抓取訂餐資訊
本文以大眾點評網為例,獲取頁面的餐館資訊,以達到練習使用python的目的。 1.抓取大眾點評網中關村附近的餐館有哪些 import urllib.request import re def fetchFood(url):
用python 通過12306api抓取列車資訊
PS:本文為學習參考例項。程式碼與上述大體相同。 首先了解這些查詢介面是怎麼來的 chrome是個好東西,特別是它的控制檯能看到很多細節。 12306網站通過chrome可以看到查詢票的api 其中有log? 和 queryA?兩種開頭的介面
python網路爬蟲--抓取股票資訊到Mysql
1.建表mysql -u root -p 123456create database test default character set utf8;create table stocks --a股( code varchar(10) comment '程式碼', nam
爬蟲框架Scrapy實戰之批量抓取招聘資訊--附原始碼
瞭解更多Python爬蟲內容請微信公眾號關注:Python技術博文 所謂網路爬蟲,就是一個在網上到處或定向抓取資料的程式,當然,這種說法不夠專業,更專業的描述就是,抓取特定網站網頁的HTML資料。不過由於一個網站的網頁很多,而我們又不可能事先知道所有網頁的URL地址
爬蟲requests庫簡單抓取頁面資訊功能實現(Python)
import requests import re, json,time,random from requests import RequestException UserAgentList = [ "Mozilla/5.0 (Windows NT 6.1; WO
(PHP)用cURL抓取網頁資訊並替換部分內容
<?php /** * 用cURL抓取網頁資訊並替換部分內容 * User: Ollydebug * Date: 2015/11/11 * Time: 19:13 */ $curlo
Python3抓取頁面資訊,網路程式設計,簡單傳送QQ郵件
資料收集,資料整理,資料描述,資料分析 # coding=utf-8 import sys import urllib.request req = urllib.request.Request(
Scrapy 框架簡介 抓取一點資訊
什麼是scrapy ? 1 Scrapy是用純Python實現一個為了爬取網站資料、提取結構性資料而編寫的應用框架,用途非常廣泛 2 Scrapy 使用了 Twisted['twɪstɪd](其主要對手是Tornado)非同步網路框架來處理網路通訊3 Scrapy非常的靈
一個簡單的Jsoup抓取頁面資訊的例子
簡介: jsoup 是一款Java 的HTML解析器,可直接解析某個URL地址、HTML文字內容。它提供了一套非常省力的API,可通過DOM,CSS以及類似於jQuery的操作方法來取出和操作資料。在本文,本人將教大家如何使用jsoup抓取一些簡單的頁面資訊準備:
Perl抓取網頁資訊
demo: #!/usr/bin/perl -w # Perl pragma to restrict unsafe constructs use strict; # use LWP::UserAgent model use LWP::UserAgent; # main