
資訊抽取——關係抽取(一)
目錄
- 簡介
- 關於關係抽取
- Pipline模型
- Model 1: Relation Classification via Convolutional Deep Neural Network
- Model 2: Relation Extraction: Perspective from Convolutional Neural Networks
- Model 3: Classifying Relations by Ranking with Convolutional Neural Networks
- Model 4: Bidirectional Long Short-Term Memory Networks for Relation Classification
- Model 5: Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
- Model 6: Relation Classification via Multi-Level Attention CNNs
- Model 7: Bidirectional Recurrent Convolutional Neural Network for Relation Classification
簡介
資訊抽取(information extraction),即從自然語言文字中,抽取出特定的事件或事實資訊,幫助我們將海量內容自動分類、提取和重構。這些資訊通常包括實體(entity)、關係(relation)、事件(event)。例如從新聞中抽取時間、地點、關鍵人物,或者從技術文件中抽取產品名稱、開發時間、效能指標等。
顯然,資訊抽取任務與命名實體識別任務類似,但相對來說更為複雜。有時,資訊抽取也被稱為事件抽取(event extraction)。
與自動摘要相比,資訊抽取更有目的性,並能將找到的資訊以一定的框架展示。自動摘要輸出的則是完整的自然語言句子,需要考慮語言的連貫和語法,甚至是邏輯。有時資訊抽取也被用來完成自動摘要。
由於能從自然語言中抽取出資訊框架和使用者感興趣的事實資訊,無論是在知識圖譜、資訊檢索、問答系統還是在情感分析、文字挖掘中,資訊抽取都有廣泛應用。
資訊抽取主要包括三個子任務:
- 實體抽取與鏈指:也就是命名實體識別
- 關係抽取:通常我們說的三元組(triple)抽取,主要用於抽取實體間的關係
- 事件抽取:相當於一種多元關係的抽取
由於工作上的原因,先對關係抽取進行總結,實體鏈指部分之後有時間再補上吧。
關於關係抽取
關係抽取通常再實體抽取與實體鏈指之後。在識別出句子中的關鍵實體後,還需要抽取兩個實體或多個實體之間的語義關係。語義關係通常用於連線兩個實體,並與實體一起表達文字的主要含義。常見的關係抽取結果可以用SPO結構的三元組來表示,即 (Subject, Predication, Object),如
中國的首都是北京 ==> (中國, 首都, 北京)
關係抽取的分類:
- 是否有確定的關係集合:
- 限定關係抽取:事先確定好所有需要抽取的關係集合,則可講關係抽取看作是一中關係判斷問題,或者說是分類問題
- 開放式關係抽取:需要抽取的關係集合是不確定的,另一方面抽取預料的所屬領域也可能是不確定的
- 關係抽取可以用有監督、半監督甚至是無監督的方法來做。
- 有監督學習:監督學習的關係集合通常是確定的,我們僅需要將其當作一個簡單的分類問題來處理即可。高質量監督資料下的監督學習模型的準確率會很高,但缺點就是需要大量的人力成本和時間成本來對文字資料進行標註,且其難以擴充套件新的關係類別,模型較為脆弱,泛化能力有限
- 半監督學習利用少量的標註資訊作為種子模版,從非結構化資料中抽取大量的新的例項來構成新的訓練資料。主要方法包括 Bootstraping 以及遠端監督學習的方法
- 無監督學習一般利用語料中存在的大量冗餘資訊做聚類,在聚類結果的基礎上給定關係,但由於聚類方法本身就存在難以描述關係和低頻例項召回率低的問題,因此無監督學習一般難以得很好的抽取效果。
- 對於有監督的關係抽取任務,通常也將其分為兩大類
- Pipline:將實體抽取與關係抽取分為兩個獨立的過程,關係抽取依賴實體抽取的結果,容易造成誤差累積
- Joint Model:實體抽取與關係抽取同時進行,通常用模型引數共享的方法來實現
隨著深度學習以及詞向量的發展,近年來大多的關係抽取模型都採用詞向量作為關係抽取的主要特徵,且均取得了非常好的效果。限於篇幅,本文僅對有監督學習下的 Pipline 經典模型進行介紹
Pipline模型
Model 1: Relation Classification via Convolutional Deep Neural Network
原文連結:https://www.aclweb.org/anthology/C14-1220/
在深度學習興起之前,關係抽取的傳統方法依賴於特徵工程,而這些特徵通常由預先準備的NLP系統得到,這容易在構造特徵的過程中造成誤差累積,阻礙系統性能。
該論文屬於早期使用深度卷積網路模型解決關係抽取任務的經典論文。該論文將關係抽取問題定義為:給定一個句子 \(S\) 和名詞對 \(e_1\) 和 $e_2 $,判斷 \(e_1\) 和 \(e_2\) 在句子中的關係,即將關係抽取問題等效為一個關係分類問題。與傳統的方法相比,該模型只需要將整個輸入句子以及簡單的詞資訊作為輸入,而不需要認為構造特徵,就能得到非常好的效果。模型的主要架構如下所示:
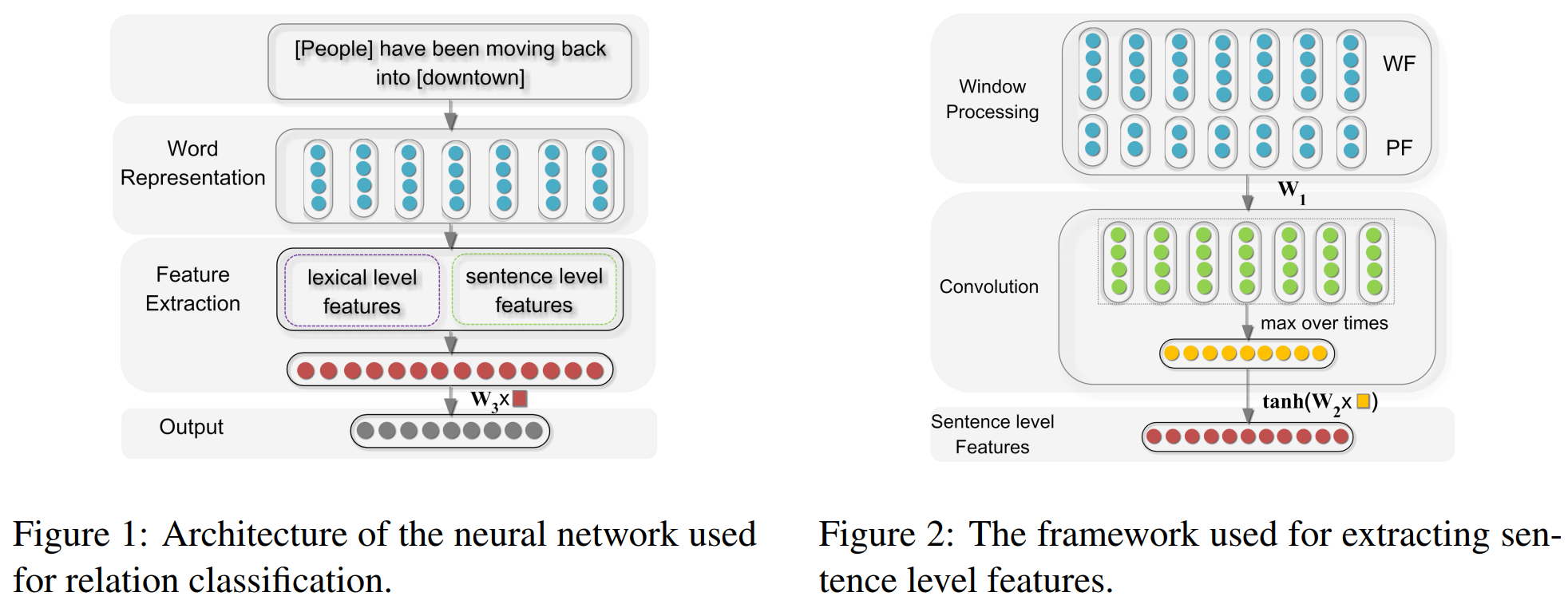
模型的輸入主要包括兩個部分,即詞彙級別特徵以及句子級別特徵:
lexical level features:詞彙級別特徵包括實體對\(e_1\) 和 \(e_2\) 的詞嵌入向量,\(e_1\) 和 \(e_2\) 的左右兩邊詞的詞嵌入向量,以及一個 WordNet 上位詞向量。WordNet 上位詞特徵指的是 \(e_1\) 和 \(e_2\) 同屬於哪一個上位名次,如“狗”和“貓”的上位詞可以是“動物”或者“寵物”,具體需要參考的 WordNet 詞典是怎樣構建的。直接將上述的5個向量直接拼接構成詞彙級別的特徵向量 \(l\)
- sentence level feature:句子級別特徵採用最大池化的卷積神經網路作為主要特徵抽取模型,輸入特徵包括詞向量資訊以及位置向量資訊。
- Word Features:為了能夠抽取到每個詞完整的上下文資訊,在句子首位額外添加了Padding字元,Word Embedding 層是預訓練得到的,並且參與後續的訓練任務
- Position Features:額外增加了時序特徵來彌補卷積網路對時序特徵抽取能力不足的缺陷。論文中的做法是為每個詞拼接兩個固定維度的位置向量,分別表示詞距離兩個關鍵實體的相對位置資訊。如“中國 的 首都 是 北京”,“的”與“中國”的距離大小為 1,與“北京”的距離大小為 -3,再將 1 和 -3 在 Position Embedding 層中查表得到,Position Embedding 層是隨機初始化的,並且參與到模型訓練當中
- 將上述的 Word Features 與 Position Features 拼接,輸入到卷積網路中,再用Max Pooling 層把每個卷積核的輸出進行池化操作。再將池化結果通過一個全連線層,啟用函式為 \(tanh\),將其看作一個更高層次的特徵對映,得到最終的句子級別的特徵向量 \(g\)
將詞彙級別特徵與句子級別特徵直接拼接,即\(f = [l, g]\),最終將其送入分類器進行分類。
該模型將關係抽取任務利用神經網路進行建模,利用無監督的詞向量以及位置向量作為模型的主要輸入特徵,一定程度上避免了傳統方法中的誤差累積。但仍然有 lexical level feature 這個人工構造的特徵,且 CNN 中的卷積核大小是固定的,抽取到的特徵十分單一
Model 2: Relation Extraction: Perspective from Convolutional Neural Networks
原文連結:https://www.aclweb.org/anthology/W15-1506/
該論文首先提出關係分類和關係抽取兩個主要任務:
- 關係分類:兩個實體之間存在多個關係型別,並且這多個可能關係中有一個 non-relation 類別,這多個類別的樣本數量基本是平衡的
- 關係抽取:關係抽取與關係分類的區別在於,關係抽取中的 non-relation 類別的樣本數目可能遠遠超過其他類別的樣本數目,這樣的任務更有挑戰性,但在實際中有更為廣泛的應用
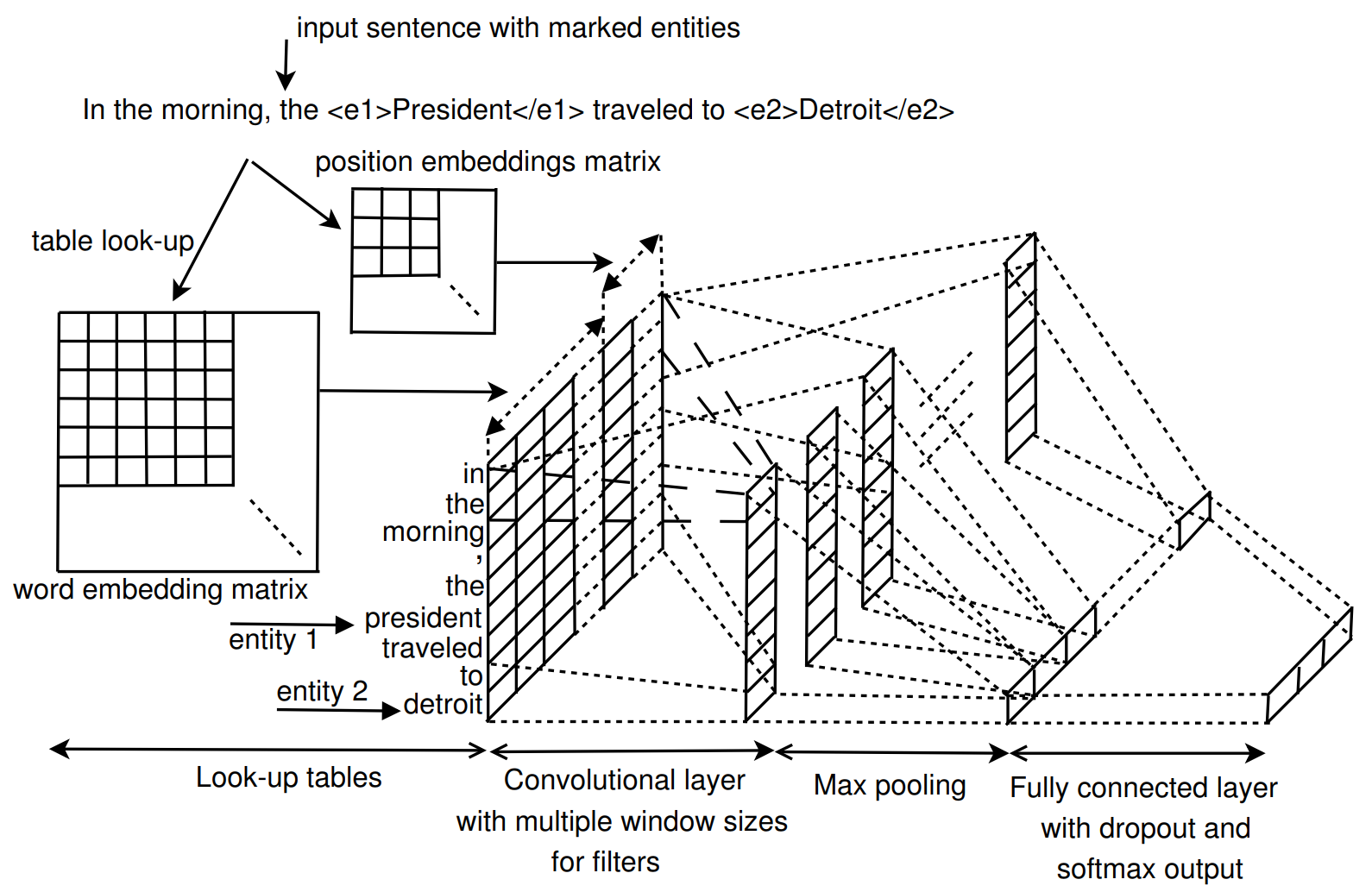
論文主要關注的是關係抽取任務。與 Model 1 類似,同樣是利用卷積神經網路作為主要的特徵抽取模型,模型細節如下所示:
- Look-up tables:包括 word embedding 層和 position embedding 層兩個部分。word embedding 為預訓練得到,而 position embedding 則隨機初始化,兩者均參與訓練。對於輸入句子長度,將其限定在兩個實體可能的最大長度的範圍內,假設句子長度為 \(n\),用 \(i-i_1\) 和 \(i-i_2\) 表示地i個詞距離第一個實體和第二個實體的距離,則 position embedding 層的維度為\((2n-1) \times m_d\),其中\(m_d\) 為位置向量的維度。假設句子中第 \(i\) 個詞的詞向量為 \(e_i\) ,位置向量為 \(d_{i1}\) 和 \(d_{i2}\),則該詞的詞表徵為 \(x_i = [e_i, d_{i1}, d_{i2}]\)
- Convolutional layer:該模型的卷積層借鑑了 TextCNN 的模型結構,通過設計多個不同寬度的卷積核來抽取不同粒度大小的特徵來提升模型效能。
- Pooling layer:最大池化操作,用於抽取最重要的特徵
- Classifier:全連線層,啟用函式為softmax,還使用了 dropout 和 l2 正則化策略
該論文的模型輸入完全沒有人工特徵,且使用多寬度大小的卷積核進行特徵抽取,相對於 Zeng 的效果來說僅提升了 \(0.1\%\),個人認為提升的主要關鍵點在於多粒度大小的卷積核上,而 lexical feature 在這種簡單的深度學習模型上還是能夠起到一定的效果的,這在之後的工作中也得到了證實
Model 3: Classifying Relations by Ranking with Convolutional Neural Networks
原文連結:https://www.aclweb.org/anthology/P15-1061/
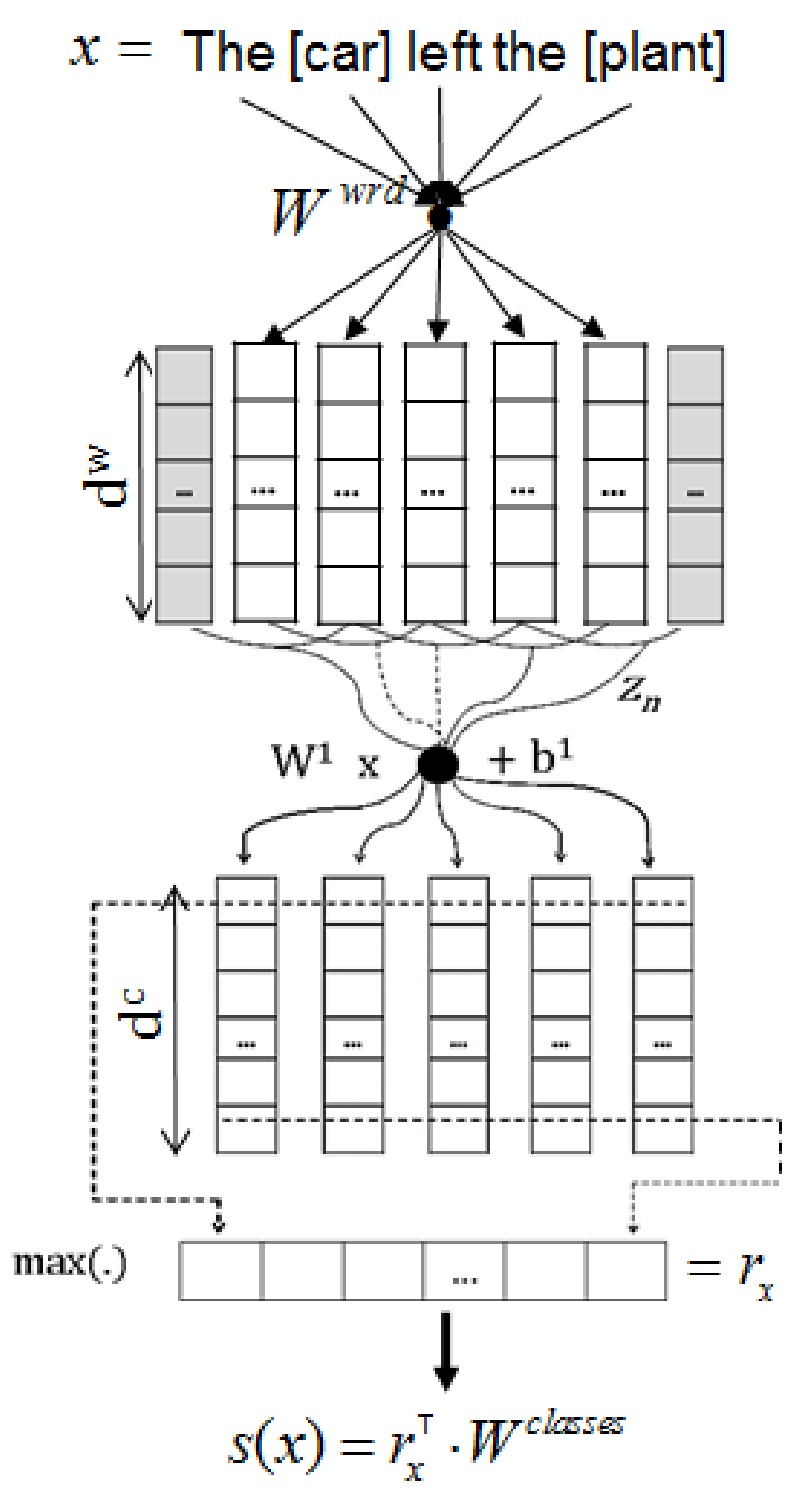
這篇論文同樣是在 Model 1 基礎上的改進,模型的基本架構與之前基本一致,最大的改變損失函式。模型結構如上圖所示,主要有以下幾個部分:
- 模型僅將整個句子作為輸入,不考慮 lexical level feature。輸入詞表徵包括 Word Embedding 和 Position Embedding 兩個部分,獲取方式與之前一樣
- 卷積層為視窗為 3 的固定大小的卷積核,且也對輸出進行了最大池化操作
對於得到的編碼表徵,輸入一個全連線層,得到每個類別的非歸一化分數,但不再對輸出做 softmax 操作,而是直接對正類別和負類別進行取樣,從而計算損失函式,損失函式(pairwise ranking loss function)如下所示:
這個損失函式主要有以下幾個特點:
\[L = log(1 + exp(\gamma(m^+-s_{\theta}(x)_{y^+}))) + log(1 + exp(\gamma(m^-+s_{\theta}(x)_{c^-})))\]- \(m^+\) 和 \(m^-\) 為 margin 引數,\(\gamma\) 為縮放因子
- \(s_{\theta}(x)\) 為模型輸出的非歸一化分數,\(y^+\) 為正確標籤,\(c^-\) 為錯誤標籤中分數大於 \(m^-\) 的那些標籤,作者認為這些標籤具有更大的資訊量。
- 顯然,損失函式 L 將隨著 \(s_{\theta}(x)_{y^+}\) 的增大而減小,隨著 \(s_{\theta}(x)_{c^-}\) 的減小而減小
- 此外,模型還考慮了兩個實體不屬於任何類別,將其看作類別 "Other",在訓練的過程中,不考慮這個類別的分類,或者說在全連線層為該類別分配了一個不可訓練的零初始化的神經元,對於該類別為正確標籤的訓練樣本,損失函式的第一項為0,只保留第二項。在預測的時候,只當某個樣本所有類別分數為負數時,才將其分類為 "Other"
模型在訓練過程中還額外添加了 L2 正則化項
該模型的主要創新點在於其 Ranking loss 上,相比於 Softmax 函式,其能夠使得模型不僅僅考慮到正類別分數要儘量高,還要關注易分類錯誤的類別分數儘量低。其缺點仍然是模型結構上的缺陷。
Model 4: Bidirectional Long Short-Term Memory Networks for Relation Classification
原文連結:https://www.aclweb.org/anthology/Y15-1009/
在這篇論文之前有過利用簡單的 RNN 和 BiRNN 作為模型編碼模組的處理關係抽取任務的,但是效果較 CNN 來說差的就不是一點兩點了,這裡就不提了。該論文用經典的 BiLSTM 作為模型主要模組,此外,重新考慮了 lexical feature,實驗證明 lexical feature 對模型效能確實有十分明顯的提升效果。
模型的主要架構是 BiLSTM,這個結構大家再熟悉不過了,論文也沒有貼模型整體圖,這裡我也偷下懶...接下來分段闡述一下模型的主要工作。
- 特徵初始化:模型使用到的特徵除了詞和位置特徵以外,還利用NLP工具獲得了詞性(POS)、實體(NER)、依存句法(dependency parse)以及上位(hypernyms)特徵
- 詞、詞性(POS)、實體(NER)以及上位(hypernyms)特徵均為 lexical feature
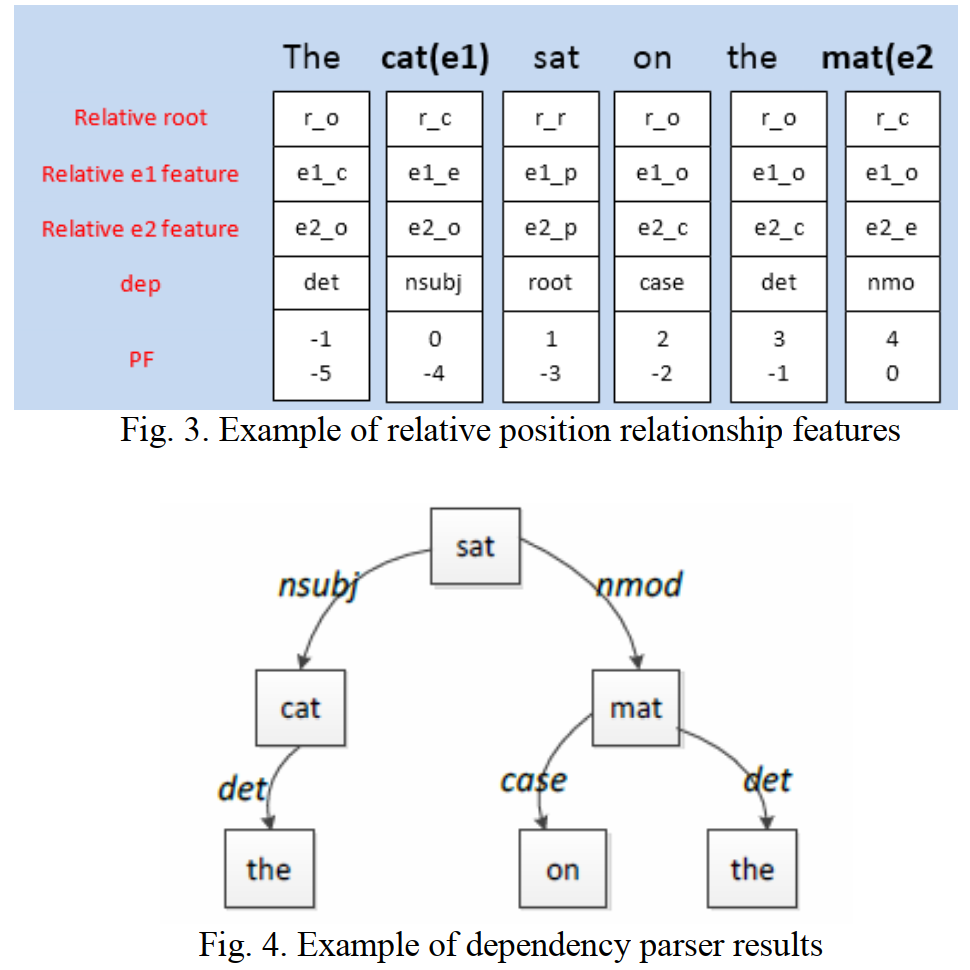
- 位置向量和依存句法特徵的構造方式如下所示
- 位置向量:位置向量(圖中為PF)的構造方法與 Zeng CNN 中一致
- 相對依存特徵(Relative dependency features)依賴 Stanford dependency parser 依存句法樹生成,做如下定義
- Relative root feature:根節點定義為 \(r_r\),根節點的子節點定義為 \(r_c\),其他節點定義為 \(r_o\)
- Relative \(e_1\) feature:實體 \(e_1\) 定義為 \(e_{1e}\),實體 \(e_1\) 的父節點定義為 \(e_{1p}\),實體 \(e_1\) 的子節點定義為 \(e_{1c}\),其他節點定義為 \(e_{1o}\)
- Relative \(e_2\) feature:相對實體 \(e_2\) 做如 \(e_1\) 類似的定義
- Dep feature:為每個詞與其父節點的依存關係
特徵嵌入:第個詞的詞向量 \(r_i^w\) 利用預訓練的詞向量查表得到,第j個特徵向量 \(r_i^{kj}\) 直接隨機初始化得到,最終的詞表徵為詞向量與特徵向量拼接而成:
\[x_i = [r_i^w, r_i^{k1}, ..., r_i^{km}]\]句子級別表徵:直接將詞表徵輸入 BiLSTM 進行編碼,用 \(F\) 和 \(B\) 表示兩個方向,\(h_i\)和\(c_i\)表示隱藏資訊與全域性資訊,則第 \(i\) 時刻的輸出為:
\[F_i = [F_{h_i}, F_{c_i}, B_{h_i}, B_{c_i}]\]- 特徵向量整合:作者受到 Zeng CNN 的啟發,也構造了 lexical level feature 和 sentence level feature
- lexical level feature:該特徵只關注實體的特徵,即只將兩個實體的詞表徵和 BiLSTM 編碼表徵進行拼接 \([x_{e1}, F_{e1}, x_{e2}, F_{e2}]\)
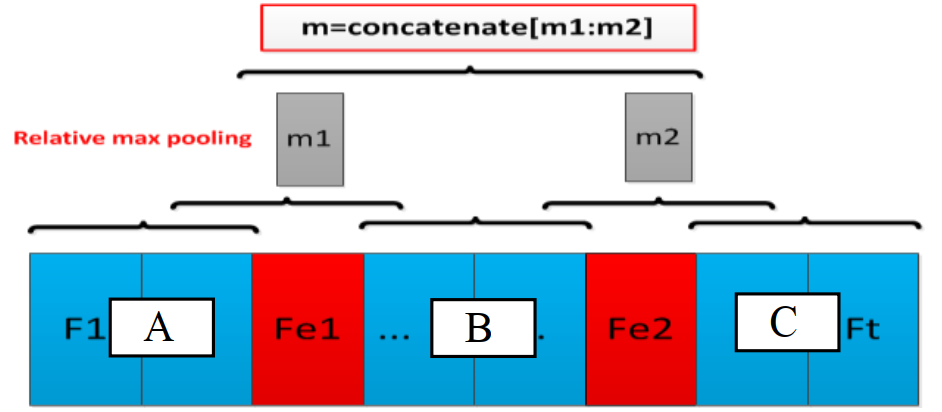
- sentence level feature:句子級別的表徵需要關注整個句子的資訊,如下圖所示,兩個實體將整個句子分為三個部分,\(m1\) 和 \(m2\) 分別為 \([A, B]\) 和 \([B, C]\) Max Pooling 操作的結果,最後的句子級別特徵為 \([m1, m2]\)
- 將兩個向量拼接,然後通過多層的全連線網路將其進行整合
最後利用前連線層 + softmax 進行分類
論文最後測試了不加人工特徵,只用 word embedding,結果下降了\(1.5\)個點,說明人工特徵還是有一定效果的。此外,論文還測試了移除某個特徵對模型的影響,發現位置特徵和 NER 特徵的移除對模型的影響非常小,這也是十分好理解的,這裡就不多說了。
Model 5: Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
原文連結:
該模型利用了典型的注意力機制對 BiLSTM 的輸出進行了注意力加權求和,在僅利用了詞向量的情況下效果接近加入人工特徵的模型,可見注意力機制的作用也是十分強大的。
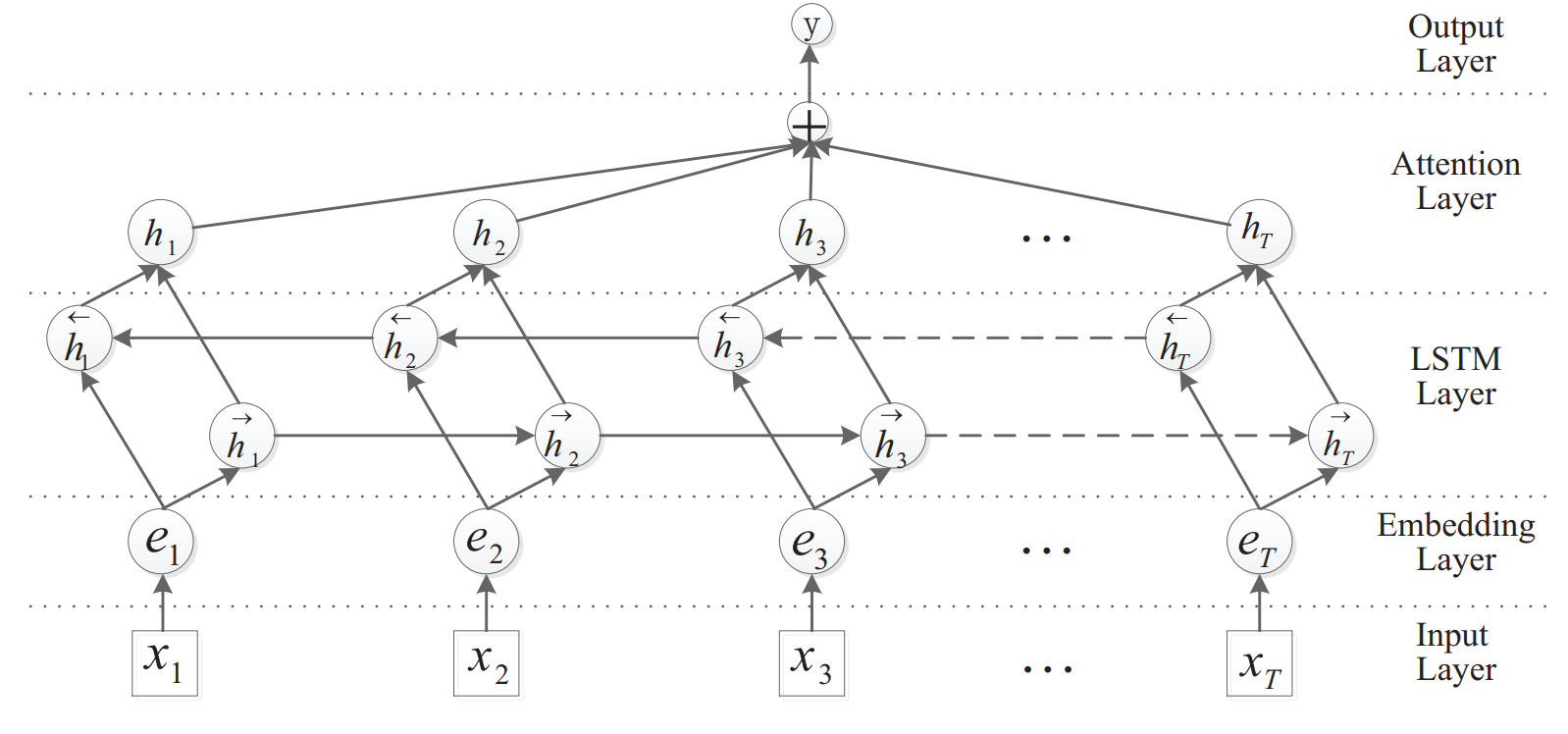
模型的主要架構如上圖所示。其實模型的主要架構還是比較常規的,下面簡單介紹一下:
- Input Layer: 即輸入的句子,每個詞用 one-hot 向量表示
- Embedding Layer: 預訓練的詞向量層,為 one-hot 向量提供查詢詞表
- LSTM Layer: 利用 BiLSTM 對輸入句子進行編碼,得到每個時刻的輸出,即對應每個詞的編碼結果
- Attention Layer: 典型的 Soft-Attention 層。直接隨機初始化一個引數向量作為 Query,用於與句子的編碼結果進行一維匹配計算注意力分數,再對句子的各個詞的編碼結果進行加權求和,具體表達式如下所示:
\[M = tanh(H) \\ \alpha =softmax(w^TM) \\ r = H\alpha^T\]
其中,\(H\) 為 BiLSTM 的所有時刻的輸出,\(w\) 為隨機初始化的引數向量,同時也參與到模型訓練,\(\alpha\) 為注意力分數的計算結果,\(r\) 為對 \(H\) 注意力分數加權的結果,最後還對注意力加權結果通過一個 \(tanh\) 啟用函式,即 \(h^* = tanh(r)\) 得到注意力層的輸出 - Output Layer: 即一層全連線層分類器,損失函式為交叉熵,同時加入了 L2 正則化項
從論文的結果來看,不進行特徵工程,僅僅將整個句子作為模型輸入,並加入注意力機制,模型效果得到了非常大的提高,一方面說明必要的特徵工程還是有效的,另一方面表明注意力機制也起到了十分明顯的作用
Model 6: Relation Classification via Multi-Level Attention CNNs
原文連結:https://www.aclweb.org/anthology/P16-1123/
這篇文章公佈其在 SemEval-2010 Task 8 上的分數達到了 88.0,但是沒有開源,且復現結果也不太好,這個模型的效果存在爭議,或許是論文中個別細節描述有誤,但是其思路還是非常不錯的,先給概括一下整個論文的工作:
- 模型主要依賴一種多層注意力機制
- 第一層的注意力機制在輸入層,用於計算所有詞對目標實體的注意力大小
- 第二層的注意力機制在CNN的輸出部分,用於計算對於目標關係的注意力大小
- 提出了一種新的損失函式,證明其效果要優於傳統的損失函式
- 其優秀的模型表現依賴於非常豐富的先驗知識
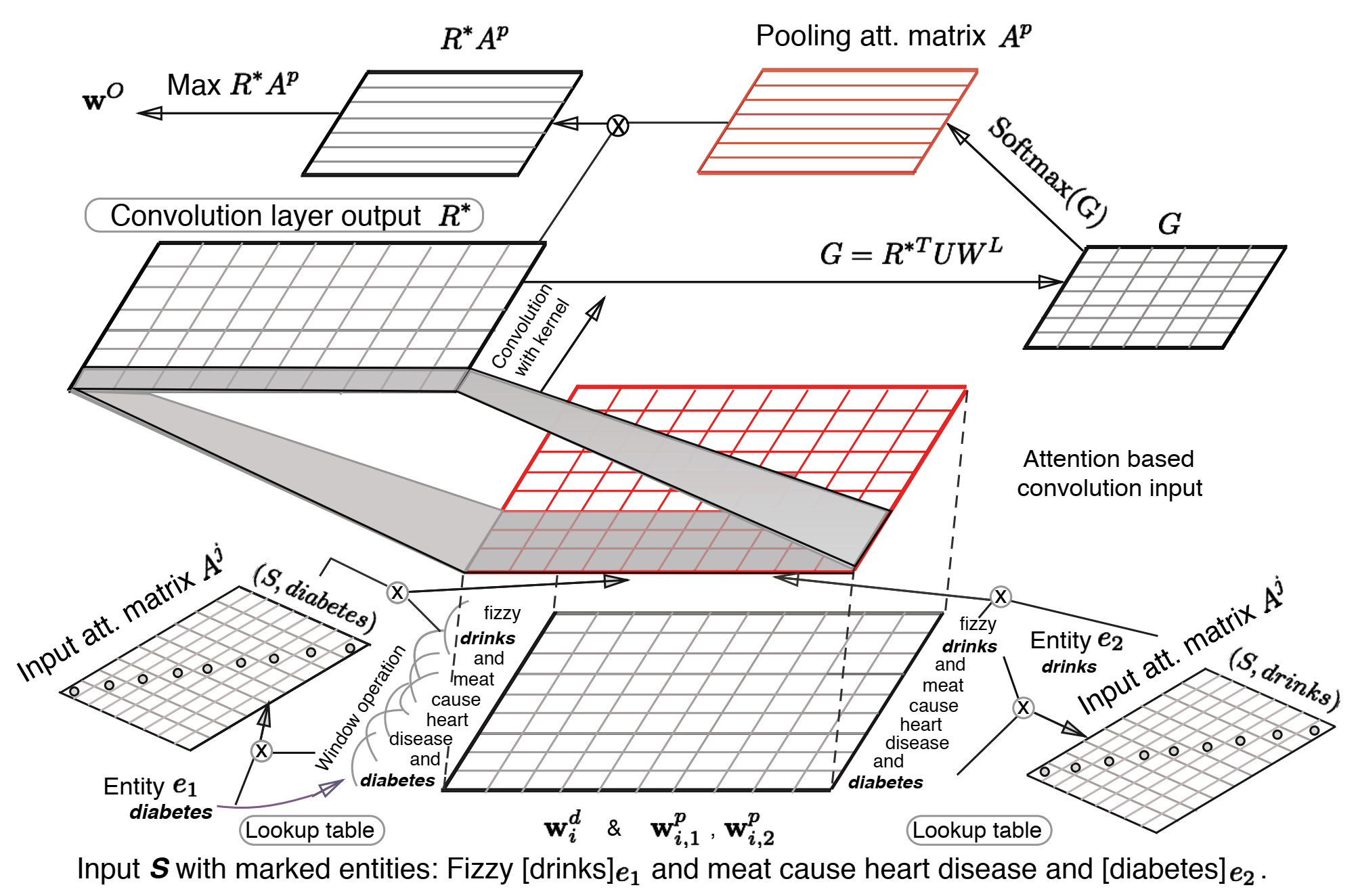
模型的主要結構如上圖所示,下面分別闡述下模型的各個模組:
- Input Representation: 輸入表徵與 Zeng CNN 一致,為 Word Embedding 和 Position Embeddding 的拼接,即 \(w^M_i = [w^d_i, w^p_{i,1}, w^p_{i,2}]\),由於 CNN 的 n-gram 特性,同樣需要對句子的首尾進行 padding 操作。為了與之後的注意力機制進行匹配,通過將以中心詞為中心的 \(k\) 個詞的詞向量進行拼接,得到 n-gram 表徵,即 \(z_i = [w^M_{i-(k-1)/2}, ..., w^M_{i+(k-1)/2}]\),之後的卷積核視窗設定為 1,即可實現與傳統的卷積視窗為 k 相類似的效果
Input Attention Mechanism: 直接使用向量內積的方式來計算實體與其他詞之間的相關性,並且將其構造成一個對角陣(其實可以直接用向量來表示的),再將其進行softmax歸一化得到注意力分數:
在求得每個詞針對兩個實體的注意力分數之後,對之前的詞表徵進行處理,文中給出的處理方法有三種:
\[A^j_{i, i} = e_i \cdot w_i \\ \alpha^j_i = \frac{exp(A^j_{i, i})}{\sum_{i'=1}^nexp(A^j_{i', i'})} \]- sum: \(r_i = z_i \frac{\alpha_1 + \alpha_2}{2}\)
- concat: \(r_i = [\alpha_1z_i, \alpha_2z_i]\)
- substract: \(r_i = z_i \frac{\alpha_1 - \alpha_2}{2}\)
最後得到 \(r_i\) 為詞的注意力加權表徵
Convolution Layer: 由於事先在資料上做了 n-gram 操作,所以卷積核視窗設定為 1,其餘的常規的卷積層沒有區別,啟用函式為 tanh,即
\[R^* = tanh(W_fR + B_f)\]- Attention-Based Pooling: 將常規的 Max Pooling 直接用 Attention 操作替代,具體操作如下:
- 隨機初始化一個 relation embedding 矩陣 W_L,在訓練過程中更新,再額外初始化一個注意力權重矩陣,計算一個二維匹配模型:
\[G = R^*UW_L\] - 對行進行歸一化,即得到每個詞表徵對每個 relation label 的注意力大小,或說是相關性分數:
\[A_{i, j}^P = \frac{exp(G_{i, j})}{\sum_{i'=1}^nexp(G_{i',j})}\] - 對詞表徵進行注意力加權,得到注意力加權的 relation label 表徵,再對這個結果進行 Max Pooling:
\[w^O = max_j(R^*A^P)\]
最後的 \(w^O\) 即為整個模型的輸出向量
- 隨機初始化一個 relation embedding 矩陣 W_L,在訓練過程中更新,再額外初始化一個注意力權重矩陣,計算一個二維匹配模型:
- margin-based pairwise loss function: 作者定義了新的損失函式代替之前的分類器 + softmax + 交叉熵的做法
假設我們得到的 \(w^O\) 為我們得到的實體間的 inferred relation embedding,此外,我們還在 Attention-Based Pooling 中訓練了 relation embedding,則計算兩個向量間的距離:
\[\delta_{\theta}(S, y) = ||\frac{w^O}{|w^O|} - W_y^L||\]我們希望 inferred relation embedding 與 正確標籤的 embedding 距離儘量小,且與其他樣本的 embedding 距離儘量大,作者借鑑了 pairwise ranking loss function (見 Model 3) 中的做法,損失函式函式定義如下:
\[L = [\delta_{\theta}(S, y) + (1-\delta_{\theta}(S, \hat{y}^-))] + \beta||\theta||^2\]其中,\(\hat{y}^-\) 為所有標籤中與 \(w^O\) 距離最大的負標籤(個人在這裡存在疑惑,認為這個應該是與 \(w^O\)距離最小的負標籤才更為合適,因為我們期望將最易分錯的類別與 \(w^O\) 應該儘量遠)
可以看到這篇論文的兩次 Attention 以及 損失函式的設計都是十分巧妙的,且論文中提到效果非常好,許多技巧還是可以借鑑的。
Model 7: Bidirectional Recurrent Convolutional Neural Network for Relation Classification
原文連結:https://www.aclweb.org/anthology/P16-1072/
論文的主要思想是對兩個實體間的詞法句法的最短依賴路徑 SDP (shortest dependency path)進行建模,這也是常見的一種關係抽取任務的建模方法,並與之前的建模方式存在一些區別,下面相對詳細地闡述一下。
由於受到卷積神經網路和迴圈神經網路特性的限制,之前的工作將句法依賴關係看作是詞或者某些句法特徵,如詞性標籤 (POS)。該論文的第一個貢獻就是提出了一種 RCNN 的網路結構:
- 利用兩通道的 LSTM 對 SDP 進行全域性資訊編碼
- 利用 CNN 捕獲每個依賴關係連線的兩個單詞的區域性特徵
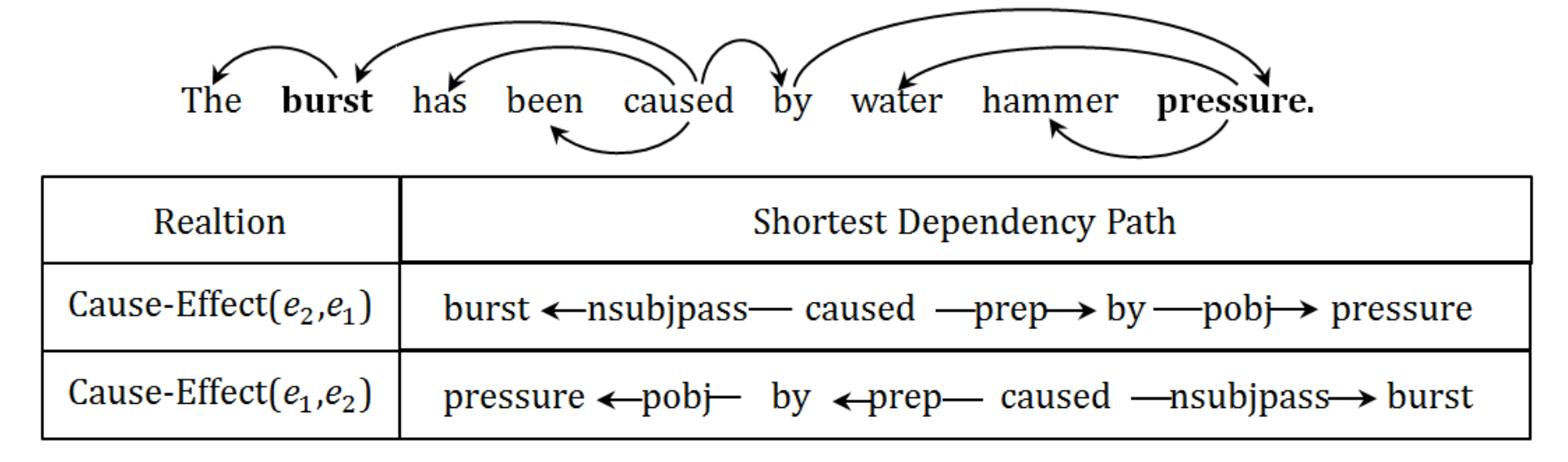
此外,作者還指出,兩個實體之間的依賴關係是有向的,如上圖展示的因果關係示例圖,若存在 \(K\) 個關係,則需要將其看作 \((2K + 1)\) 種分類問題,其中 \(1\) 為 \(Other\) 類。因此,作者提出其第二個貢獻就在於使用雙向的迴圈卷積神經網路 (BRCNN) 來同時學習雙向的表徵,可以將雙向依賴問題建模為對稱的依賴問題,從而將其簡化為 \((K + 1)\) 的分類問題
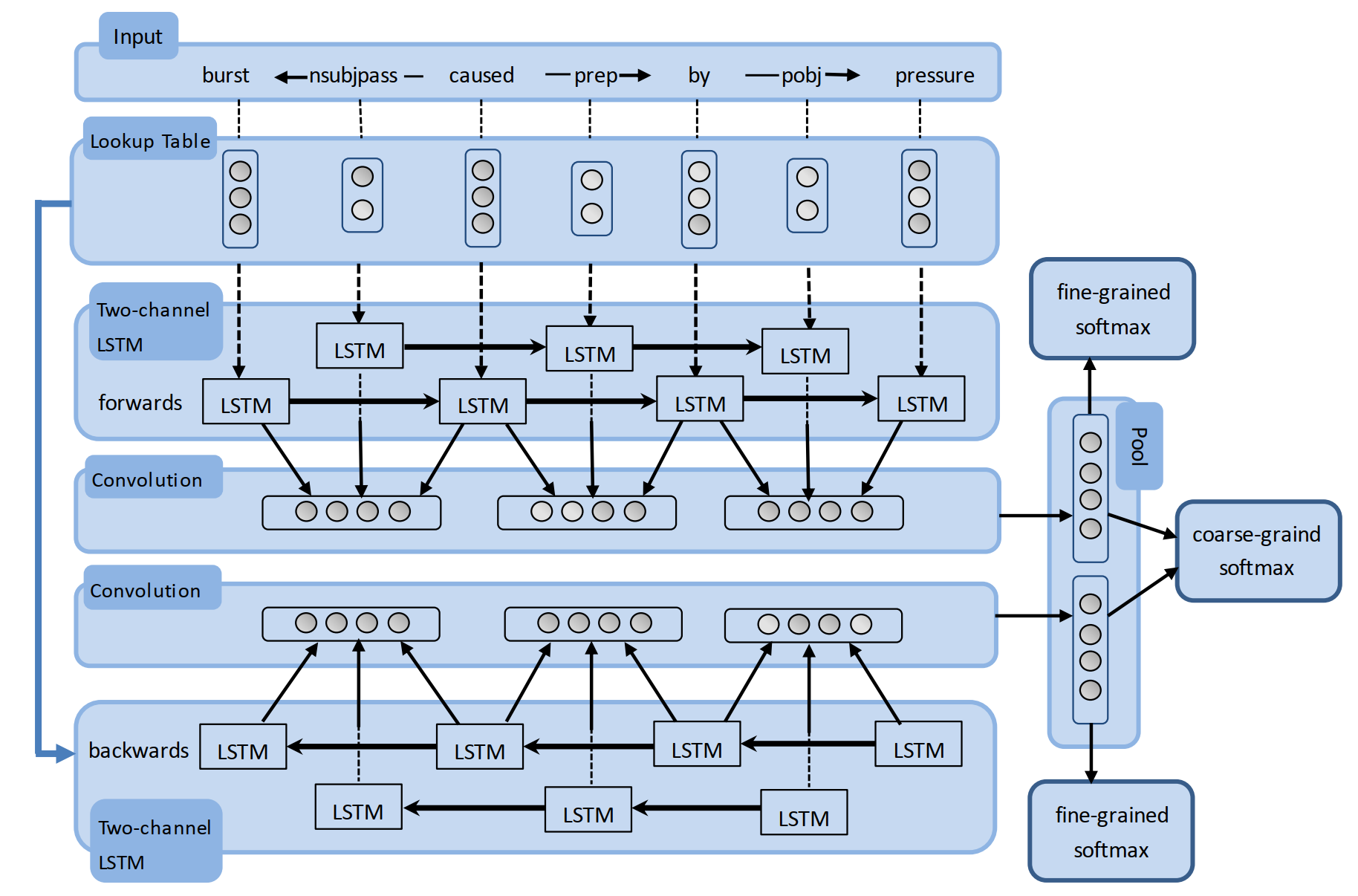
模型細節如上圖所示,下面簡單講解一下整個模型結構:
- Input:模型的輸入為兩個實體間的 SDP。論文中提到,對於句子中的兩個實體,存在某種關係R,則其詞法句法的最短依賴路徑 SDP 將闡明這個關係 R 的大多數資訊,其主要有如下兩個原因:
- 如果實體 \(e_1\) 和 \(e_2\) 是同一謂詞的論元(與謂詞搭配的名詞),則它們之間的最短路徑將通過該謂詞;
- 如果實體 \(e_1\) 和 \(e_2\) 屬於不同的謂詞-論元結構,但共享了同一個論元,則最短路徑通過這個共享論元
- Lookup Table:包括詞向量和依存關係向量,詞向量是預先訓練得到的,依存關係向量直接隨機初始化即可,此外,還可以在詞向量中加入 NER、POS 以及 WordNet 等特徵
- BRCNN:BRCNN 為模型的主要架構,包括三個部分 Two-channel BiLSTM、CNN、Classifier
- Two-channel BiLSTM:所謂的兩通道指的是對 詞 和 依存關係 分別用兩個 BiLSTM 結構進行建模。使用 BiLSTM 有兩個好處,一方面避免了 LSTM 在時序建模上的偏向性問題(後期的輸入比早期的輸入更為重要),另一方面也可以將有向的依賴關係建模為一個對稱關係,這樣就不需要額外考慮依賴關係的雙向性問題。與我們常見的 BiLSTM 不同的是,兩個方向的編碼結果在後面需要分別處理,而不是像我們之前的那樣,直接拼接再做之後的處理。
對於存在關係的詞與依賴關係 \(w_a -r_{ab}-> w_b\),分別用 \(h_a, h_{ab}', h_b\) 來表示 LSTM 的對應隱藏表徵,則可以利用 CNN 將詞及依賴關係的區域性特徵 \(L_{ab}\) 進行抽取,即
其中, \(W_{con}\) 和 b_{con}) 為卷積神經網路引數。在這之後,使用一個 Max Pooling 層區域性特徵進行池化操作。由於模型是雙向分別處理的,兩個方向的模型分別得到一個池化結果 \(\overrightarrow{G}\) 和 \(\overleftarrow{G}\)。
\[L_{ab} = tanh(W_{con} \cdot [h_a , h_{ab}', h_b] + b_{con})\]- Classifier:輸出層由 3 個分類器組成
- coarse-grained softmax classifier:將雙向的池化資訊拼接作為分類器輸入,為一個 \((K + 1)\) 類的分類器,即
\[y = softmax(W_c[\overrightarrow{G}, \overleftarrow{G}] + b_c)\] - fine-grained softmax classifiers:兩個分類器共享引數,分別對兩個方向的池化資訊單獨進行分類,為一個 \((2K+1)\) 類的分類器,作者認為同時對兩個方向的資訊進行分類有助於加強模型判斷關係方向性的能力
\[\overrightarrow{y} = softmax(W_f\cdot \overrightarrow{G} + b_f)\\ \overleftarrow{y} = softmax(W_f\cdot \overleftarrow{G} + b_f)\]
- coarse-grained softmax classifier:將雙向的池化資訊拼接作為分類器輸入,為一個 \((K + 1)\) 類的分類器,即
目標函式:由於存在三個分類器,損失函式為三個分類器的交叉熵的累加和,同時加上了 l2 正則化
\[J = \sum_{i=1}^{2K+1}\overrightarrow{t}_ilog\ \overrightarrow{y}_i + \sum_{i=1}^{2K+1}\overleftarrow{t}_ilog\ \overleftarrow{y}_i + \sum_{i=1}^{K+1}{t}_ilog\ {y}_i + \lambda||\theta||^2\]而對於解碼過程,兩個實體之間只存在一個單向的關係,因此僅需要兩個 fine-grained softmax classifiers 的輸出結果即可
\[y_{test} = \alpha\cdot \overrightarrow{y} + (1-\alpha)\cdot z(\overleftarrow{y})\]其中,\(\alpha\) 為一個超引數,論文中將其設定為 0.65。另外由於兩個預測結果的方向是相反的,因此需要用一個函式 \(z(·)\) 來將 \(\overleftarrow{y}\) 轉化為與 \(\overrightarrow{y}\) 對應的格式
將詞法句法的 SDP 作為輸入特徵來實現關係抽取也是常見的一種建模方法,且效果也非常不錯。這篇論文通過對文字以及依賴關係分別建模,利用 LSTM 和 CNN 進行不同層次的特徵編碼,並分兩個方向進行資訊融合,確實是一大亮點。如果詞向量只用 Word Embeddings,分數可以達到 85.4,如果加上 NER、POS 以及 WordNet 等特徵可以達到 86.3。
將關係抽取看作單獨任務的模型總結就做到這裡了,或許之後看見更優秀的論文還會進行一些更新,這裡將每個模型在 SemEval-2010 Task-8 上的分數都記載一下:
|模型| 論文名稱 | 輸入特徵 |F1|
| :----- | :----- | :----- | :----- |
| Model 1 | Relation Classification via Convolutional Deep Neural Network | Word Embeddings, Position Embeddings, WordNet | 82.7 |
| Model 2 | Relation Extraction: Perspective from Convolutional Neural Networks | Word Embeddings, Position Embeddings | 82.8 |
| Model 3 | Classifying Relations by Ranking with Convolutional Neural Networks | Word Embeddings, Position Embeddings | 84.1 |
| Model 4 | Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification | Word Embeddings, Position Embeddings, POS, NER, WordNet, Dependency Feature | 84.3 |
| Model 5 | Bidirectional Long Short-Term Memory Networks for Relation Classification | Word Embeddings, Position Embeddings | 84.0 |
| Model 6 | Relation Classification via Multi-Level Attention CNNs | Word Embeddings, Position Embeddings | 88.0 |
| Model 7 | Bidirectional Recurrent Convolutional Neural Network for Relation Classification |Word Embeddings, WordNet, NER, WordNet | 86.3 |
總的來說,人工特徵、句法特徵、注意力機制、特殊的損失函式都是關係抽取模型效能提升的關鍵點,其餘的就需要在模型架構上進行合理的設計了,下一篇準備介紹實體與關係聯合抽取模型,爭取早點寫出來...
https://zhuanlan.zhihu.com/p/45422620
http://www.shuang0420.com/2018/09/15/知識抽取-實體及關係抽取/
https://zhuanlan.zhihu.com/p/91762831
http://shomy.top/2018/02/28/relation-extract