
反向傳播演算法詳解

作者:Great Learning Team
- 神經網路
- 什麼是反向傳播?
- 反向傳播是如何工作的?
- 損失函式
- 為什麼我們需要反向傳播?
- 前饋網路
- 反向傳播的型別
- 案例研究
在典型的程式設計中,我們輸入資料,執行處理邏輯並接收輸出。 如果輸出資料可以某種方式影響處理邏輯怎麼辦? 那就是反向傳播演算法。 它對以前的模組產生積極影響,以提高準確性和效率。
讓我們來深入研究一下。
神經網路(Neural network)
神經網路是連線單元的集合。每個連線都有一個與其相關聯的權重。該系統有助於建立基於海量資料集的預測模型。它像人類的神經系統一樣工作,有助於理解影象,像人類一樣學習,合成語音等等。
什麼是反向傳播(What is backpropagation?)
我們可以將反向傳播演算法定義為在已知分類的情況下,為給定的輸入模式訓練某些給定的前饋神經網路的演算法。當示例集的每一段都顯示給網路時,網路將檢視其對示例輸入模式的輸出反應。之後,測量輸出響應與期望輸出與誤差值的比較。之後,我們根據測量的誤差值調整連線權重。
在深入研究反向傳播之前,我們應該知道是誰引入了這個概念以及何時引入。它最早出現在20世紀60年代,30年後由大衛·魯梅爾哈特、傑弗裡·辛頓和羅納德·威廉姆斯在1986年的著名論文中推廣。在這篇論文中,他們談到了各種神經網路。今天,反向傳播做得很好。神經網路訓練是通過反向傳播實現的。通過這種方法,我們根據前一次執行獲得的錯誤率對神經網路的權值進行微調。正確地採用這種方法可以降低錯誤率,提高模型的可靠性。利用反向傳播訓練鏈式法則的神經網路。簡單地說,每次前饋通過網路後,該演算法根據權值和偏差進行後向傳遞,調整模型的引數。典型的監督學習演算法試圖找到一個將輸入資料對映到正確輸出的函式。反向傳播與多層神經網路一起工作,學習輸入到輸出對映的內部表示。
反向傳播是如何工作的?(How does backpropagation work?)
讓我們看看反向傳播是如何工作的。它有四層:輸入層、隱藏層、隱藏層II和最終輸出層。
所以,主要的三層是:
1.輸入層
2.隱藏層
3.輸出層
每一層都有自己的工作方式和響應的方式,這樣我們就可以獲得所需的結果並將這些情況與我們的狀況相關聯。 讓我們討論有助於總結此演算法所需的其他細節。
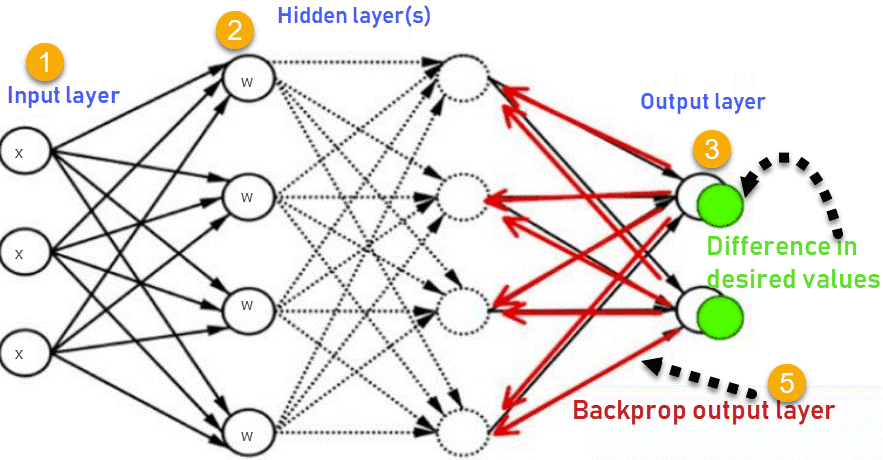
這張圖總結了反向傳播方法的機能。
1.輸入層接收x
2.使用權重w對輸入進行建模
3.每個隱藏層計算輸出,資料在輸出層準備就緒
4.實際輸出和期望輸出之間的差異稱為誤差
5.返回隱藏層並調整權重,以便在以後的執行中減少此錯誤
這個過程一直重複,直到我們得到所需的輸出。訓練階段在監督下完成。一旦模型穩定下來,就可以用於生產。
損失函式(Loss function)
一個或多個變數被對映到實數,這些實數表示與這些變數值相關的某個數值。為了進行反向傳播,損失函式計算網路輸出與其可能輸出之間的差值。
為什麼我們需要反向傳播?(Why do we need backpropagation?)
反向傳播有許多優點,下面列出一些重要的優點:
•反向傳播快速、簡單且易於實現
•沒有要調整的引數
•不需要網路的先驗知識,因此成為一種靈活的方法
•這種方法在大多數情況下都很有效
•模型不需要學習函式的特性
前饋網路(Feed forward network)
前饋網路也稱為MLN,即多層網路。 之所以稱為前饋,是因為資料僅在NN(神經網路)中通過輸入節點,隱藏層並最終到達輸出節點。 它是最簡單的人工神經網路。
反向傳播的型別(Types of backpropagation)
有兩種型別的反向傳播網路。
•靜態反向傳播(Static backpropagation)
•迴圈反向傳播(Recurrent backpropagation)
- 靜態反向傳播(Static backpropagation)
在這個網路中,靜態輸入的對映生成靜態輸出。像光學字元識別這樣的靜態分類問題將是一個適合於靜態反向傳播的領域。
- 迴圈反向傳播(Recurrent backpropagation)
反覆進行反向傳播,直到達到某個閾值為止。 在到達閾值之後,將計算誤差並向後傳播。
這兩種方法的區別在於,靜態反向傳播與靜態對映一樣快。
案例研究(Case Study)
讓我們使用反向傳播進行案例研究。 為此,我們將使用Iris資料(鳶尾花卉資料集),該資料包含諸如萼片和花瓣的長度和寬度之類的特徵。 在這些幫助下,我們需要確定植物的種類。
為此,我們將構建一個多層神經網路,並使用sigmoid函式,因為它是一個分類問題。
讓我們看一下所需的庫和資料。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split為了忽略警告,我們將匯入另一個名為warnings的庫。
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)接著讓我們讀取資料。
iris = pd.read_csv("iris.csv")
iris.head()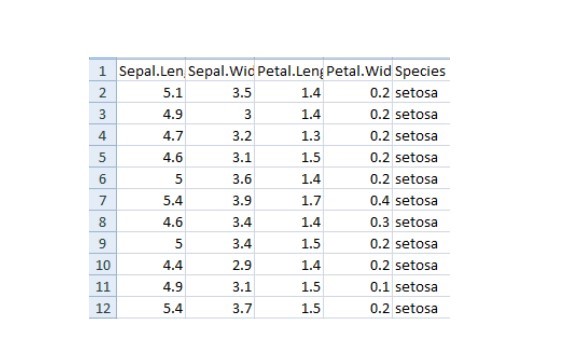
現在我們將把類標記為0、1和2。
iris. replace (, , inplace=True)我們現在將定義函式,它將執行以下操作。
1.對輸出執行獨熱編碼(one hot encoding)。
2.執行sigmoid函式
3.標準化特徵
對於獨熱編碼,我們定義以下函式。
def to_one_hot(Y):
n_col = np.amax(Y) + 1
binarized = np.zeros((len(Y), n_col))
for i in range(len(Y)):
binarized ] = 1.
return binarized現在我們來定義一個sigmoid函式
def sigmoid_func(x):
return 1/(1+np.exp(-x))
def sigmoid_derivative(x):
return sigmoid_func(x)*(1 – sigmoid_func(x))現在我們將定義一個用於標準化的函式。
def normalize (X, axis=-1, order=2):
l2 = np. atleast_1d (np.linalg.norm(X, order, axis))
l2 = 1
return X / np.expand_dims(l2, axis)現在我們將對特徵進行規範化,並對輸出應用獨熱編碼。
x = pd.DataFrame(iris, columns=columns)
x = normalize(x.as_matrix())
y = pd.DataFrame(iris, columns=columns)
y = y.as_matrix()
y = y.flatten()
y = to_one_hot(y)現在是時候應用反向傳播了。為此,我們需要定義權重和學習率。讓我們這麼做吧。但在那之前,我們需要把資料分開進行訓練和測試。
#Split data to training and validation data(將資料拆分為訓練和驗證資料)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.33)
#Weights
w0 = 2*np.random.random((4, 5)) - 1 #for input - 4 inputs, 3 outputs
w1 = 2*np.random.random((5, 3)) - 1 #for layer 1 - 5 inputs, 3 outputs
#learning rate
n = 0.1我們將為錯誤設定一個列表,並通過視覺化檢視訓練中的更改如何減少錯誤。
errors = []讓我們執行前饋和反向傳播網路。對於反向傳播,我們將使用梯度下降演算法。
for i in range (100000):
#Feed forward network
layer0 = X_train
layer1 = sigmoid_func(np.dot(layer0, w0))
layer2 = sigmoid_func(np.dot(layer1, w1))
Back propagation using gradient descent
layer2_error = y_train - layer2
layer2_delta = layer2_error * sigmoid_derivative(layer2)
layer1_error = layer2_delta.dot (w1.T)
layer1_delta = layer1_error * sigmoid_derivative(layer1)
w1 += layer1.T.dot(layer2_delta) * n
w0 += layer0.T.dot(layer1_delta) * n
error = np.mean(np.abs(layer2_error))
errors.append(error)準確率將通過從訓練資料中減去誤差來收集和顯示
accuracy_training = (1 - error) * 100現在讓我們直觀地看一下如何通過減少誤差來提高準確度。(視覺化)
plt.plot(errors)
plt.xlabel('Training')
plt.ylabel('Error')
plt.show()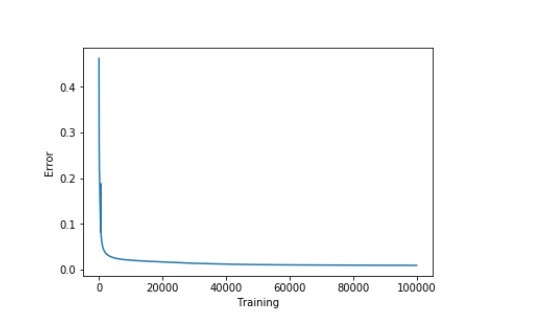
現在讓我們檢視一下準確率。
print ("Training Accuracy of the model " + str (round(accuracy_training,2)) + "%")Output: Training Accuracy of the model 99.04%
我們的訓練模型表現很好。現在讓我們看看驗證的準確性。
#Validate
layer0 = X_test
layer1 = sigmoid_func(np.dot(layer0, w0))
layer2 = sigmoid_func(np.dot(layer1, w1))
layer2_error = y_test - layer2
error = np.mean(np.abs(layer2_error))
accuracy_validation = (1 - error) * 100
print ("Validation Accuracy of the model "+ str(round(accuracy_validation,2)) + "%")Output: Validation Accuracy 92.86%
這個效能符合預期。
應遵循的最佳實踐準則(Best practices to follow)
下面討論一些獲得好模型的方法:
•如果約束非常少,則系統可能不起作用
•過度訓練,過多的約束會導致過程緩慢
•只關注少數方面會導致偏見
反向傳播的缺點(Disadvantages of backpropagation)
•輸入資料是整體效能的關鍵
•有噪聲的資料會導致不準確的結果
•基於矩陣的方法優於小批量方法(mini-batch)
綜上所述,神經網路是具有輸入和輸出機制的連線單元的集合,每個連線都有相關聯的權值。反向傳播是"誤差的反向傳播",對訓練神經網路很有用。它快速、易於實現且簡單。反向傳播對於處理語音或影象識別等易出錯專案的深度神經網路非常有益。

相關推薦
乾貨 | 深度學習之CNN反向傳播演算法詳解
微信公眾號 關鍵字全網搜尋最新排名 【機器學習演算法】:排名第一 【機器學習】:排名第一 【Python】:排名第三 【演算法】:排名第四 前言 在卷積神經網路(CNN)前向傳播演算法(乾貨 | 深度學習之卷積神經網路(CNN)的前向傳播演算法詳解)中對CNN的前向傳播演算法做了總結,基於CNN前向傳播演
反向傳播演算法詳解
作者:Great Learning Team 神經網路 什麼是反向傳播? 反向傳播是如何工作的? 損失函式 為什麼我們需要反向傳播? 前饋網路 反向傳播的型別 案例研究 在典型的程式設計中,我們輸入資料,執行處理邏輯並接收輸出。 如果輸出資料可以某種方式影響處理邏輯怎麼辦? 那就是反向傳播演算法。 它
乾貨 | 深度學習之卷積神經網路(CNN)的前向傳播演算法詳解
微信公眾號 關鍵字全網搜尋最新排名 【機器學習演算法】:排名第一 【機器學習】:排名第一 【Python】:排名第三 【演算法】:排名第四 前言 在(乾貨 | 深度學習之卷積神經網路(CNN)的模型結構)中,我們對CNN的模型結構做了總結,這裡我們就在CNN的模型基礎上,看看CNN的前向傳播演算法是什麼樣
深度學習 --- BP演算法詳解(誤差反向傳播演算法)
本節開始深度學習的第一個演算法BP演算法,本打算第一個演算法為單層感知器,但是感覺太簡單了,不懂得找本書看看就會了,這裡簡要的介紹一下單層感知器: 圖中可以看到,單層感知器很簡單,其實本質上他就是線性分類器,和機器學習中的多元線性迴歸的表示式差不多,因此它具有多元線性迴歸的優點和缺點。
反向傳播(Backpropagation)演算法詳解
反向傳播(back propagation)演算法詳解 反向傳播演算法是神經網路的基礎之一,該演算法主要用於根據損失函式來對網路引數進行優化,下面主要根據李巨集毅機器學習課程來整理反向傳播演算法,原版視訊在https://www.bilibili.com/video/av10590361/?p=
神經網路及反向傳播(bp)演算法詳解
神經元和感知器的本質一樣神經元和感知器本質上是一樣的,只不過感知器的時候,它的啟用函式是階躍函式;而當我們說神經元時,啟用函式往往選擇為sigmoid函式或tanh函式。如下圖所示: 輸入節點 每一個輸入節點對應一個權值,輸入節點可以是任意數。
詳解反向傳播演算法(上)
目錄: 1 用計算圖來解釋幾種求導方法: 1.1 計算圖 1.2 兩種求導模式:前向模式求導( forward-mode differentiation) 反向模式求導(reverse-mode differentiation) 1.3 反向求導模式(反向傳播演算法)的重要性 反向傳播演算法(Backp
nginx反向代理配置詳解
nginx反向代理配置詳解反向代理配置修改部署目錄下conf子目錄的nginx.conf文件(如/opt/nginx/conf/nginx.conf)內容,可調整相關配置。將默認配置裏面帶#號註釋內容去掉grep -v "#" /opt/nginx/conf/nginx.conf > /opt/ngin
php openssl_sign() 語法+RSA公私鑰加密解密,非對稱加密演算法詳解
其實有時候覺得寫部落格好煩,就個函式就開篇部落格。很小的意見事情而已,知道的人看來多取一舉,或者說沒什麼必要,浪費時間,不知道的人就會很鬱悶。技術就是這樣的,懂的人覺得真的很簡單啊,不知道的人真的好難。。。 一般在跟第三方介面對接資料的時候,為了保證很多都使用的RSA簽名,沒性趣瞭解的同學只需要
Show, attend and tell演算法詳解及原始碼
mark一下,感謝作者分享! https://blog.csdn.net/shenxiaolu1984/article/details/51493673 原論文:https://arxiv.org/pdf/1502.03044v2.pdf 原始碼:https://github.c
資料分析學習之不得不知的八大演算法詳解
學習資料分析的朋友們都知道,演算法是不可或缺的,或者說演算法在一定程度上可以更好的量化的一個人的學習能力和水平,本文感謝科多大資料的馮老師,由他整理了經典的八大演算法,相關的資料希望能幫助大家瞭解。 演算法一:快速排序法 快速排序是由東尼 · 霍爾所發展的一種排序演算法。在平均狀況下,排序
吳恩達機器學習(第十章)---神經網路的反向傳播演算法
一、簡介 我們在執行梯度下降的時候,需要求得J(θ)的導數,反向傳播演算法就是求該導數的方法。正向傳播,是從輸入層從左向右傳播至輸出層;反向傳播就是從輸出層,算出誤差從右向左逐層計算誤差,注意:第一層不計算,因為第一層是輸入層,沒有誤差。 二、如何計算 設為第l層,第j個的誤差。
程式設計思想 - 五大常用演算法詳解
https://www.cnblogs.com/brucemengbm/p/6875340.html https://blog.csdn.net/changyuanchn/article/details/51476281 https://www.cnblogs.com/chuninggao/p/
吳恩達機器學習 - 神經網路的反向傳播演算法 吳恩達機器學習 - 神經網路的反向傳播演算法
原 吳恩達機器學習 - 神經網路的反向傳播演算法 2018年06月21日 20:59:35 離殤灬孤狼 閱讀數:373
BP反向傳播演算法
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script> #該程式碼加入MathJax引擎,用以顯
Kadane演算法詳解及求解最大子數列和問題
最大子數列和問題 給出一個數列,現在求其中一個子數列,要求是所有子數列的和的最大值。另外還有其他問法,例如給出一個數組,要求求出連續的元素和的最大值。可以一個例子來解釋: 假設有數列:[-1,2,3,-5,6,-2,4],那麼總共有
K-NN近鄰演算法詳解
K-近鄰演算法屬於一種監督學習分類演算法,該方法的思路是:如果一個樣本在特徵空間中的k個最相似(即特徵空間中最鄰近)的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別。 (1) 需要進行分類,分類的依據是什麼呢,每個物體都有它的特徵點,這個就是分類的依據,特徵點可
字典序演算法詳解
一、字典序 字典序,就是按照字典中出現的先後順序進行排序。 1、單個字元 在計算機中,25個字母以及數字字元,字典排序如下: '0' < '1' < '2' < ... < '9' < 'a' < 'b' < ... &l
【演算法 詳解】 二維動態規劃
馬攔過河卒 原題傳送門 這一到題目也是比較基礎的動態規劃,也可以理解為是遞推,主要是運用加法原理,思維難度不大。我們要求從 (0,0) ( 0
圖的最小生成樹prim演算法詳解
prim演算法是求圖的最小生成樹的一種演算法,它是根據圖中的節點來進行求解,具體思想大概如下: 首先,將圖的所有節點(我們假定總共有n個節點)分成兩個集合,V和U。其中,集合V儲存的是我們已經訪問過的節點,集合U儲存的是我們未曾訪問的節點。prim演算法第一步就是選定第一個節點放入集合