
【小白學推薦1】 協同過濾 零基礎到入門
阿新 • • 發佈:2020-08-20
**文章轉自公眾號【機器學習煉丹術】,關注回覆“煉丹”即可獲得海量免費學習資料哦!**
****
最近找工作的時候發現,機器學習演算法工程師往往和**推薦演算法** 相關聯,之前對推薦演算法並不瞭解,所以現在我也是零基礎入門一下推薦演算法。這篇文章是我個人的學習筆記。
[TOC]
**協同過濾推薦演算法是誕生最早,最為基礎的推薦演算法。** 演算法通過對使用者歷史行為資料的挖掘發現使用者的偏好,基於不同的偏好對使用者進行群組劃分並推薦品味相似的商品。
協同過濾演算法分為兩類:
- 基於使用者的協同過濾演算法(user-based collaborative filtering)
- 基於物品的協同過濾演算法(item-based collaborative filtering)
其實我一開始對這個**協同過濾** 的概念不太瞭解,直到看了collaborative這個單詞的釋義,就是兩個物體同時出現的頻率。
## 1 基於使用者user-based
基於使用者的協同過濾演算法是通過**使用者的歷史行為資料** 發現使用者對商品或內容的喜歡,例如(商品的購買,收藏,內容評價或者分享內容等)。根據不同使用者對相同商品或者內容的態度和偏好程度計算使用者之間的關係。在有相同喜好的使用者之間進行商品推薦。
**換句話說** , 假如A和B使用者都購買了同樣的三本書,並且都給出了5星好評,那麼就認為A和B是同一類使用者。然後把A購買的另外一本書推薦給B。
### 1.1 尋找偏好相似的使用者
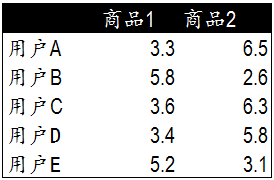
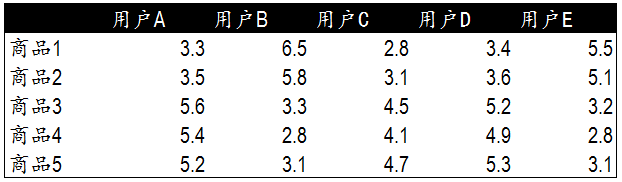
現在考慮一種最簡單的情況,5個使用者都購買了兩種商品,然後並對商品進行打分,如下圖:
最簡單的方法就是畫圖,加入用商品1的評分作為Y軸,商品2的評分作為X軸,那麼就可以得到下面的散點圖:
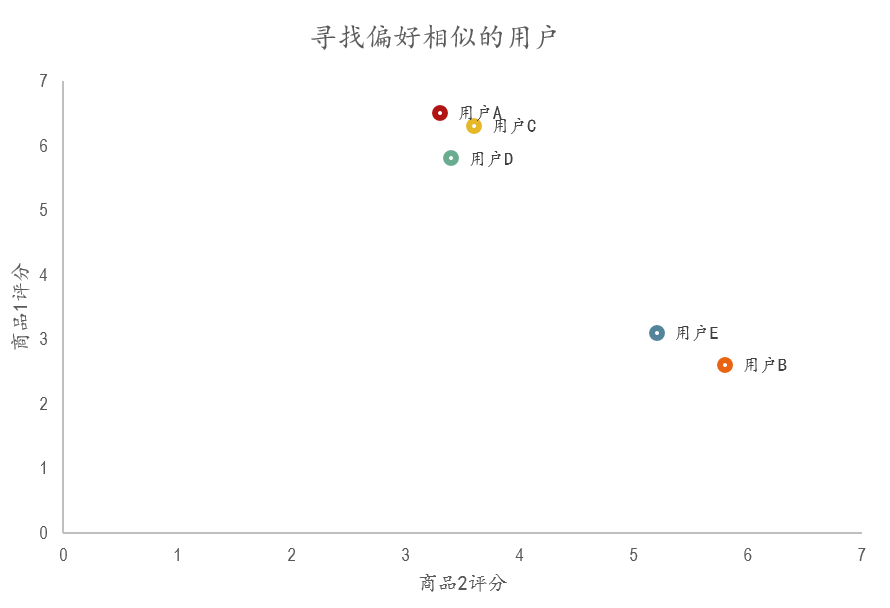
常見的想法可以用歐幾里得距離來衡量使用者之間的相似度。
### 1.2 皮爾遜相關度
- Pearson correlation coefficient
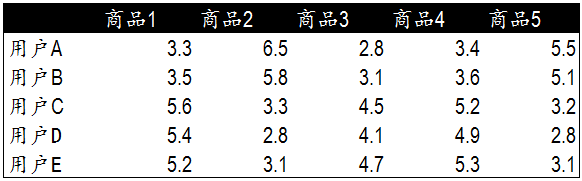
除了用歐氏距離來衡量,皮爾遜相關度是另一種計算使用者間關係的方法。現在考慮下面這一種更加複雜、也更加接近真實場景的資料:
其實呢?皮爾遜相關係數其實就是兩個變數之間的協方差和標準差的比值:
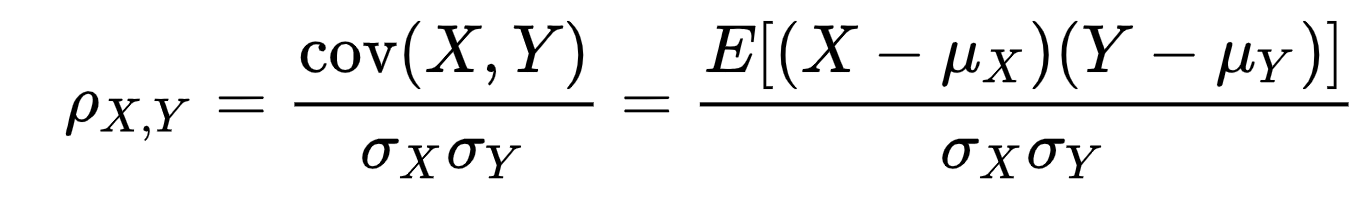
再換一個寫法,就是下面這個公式:
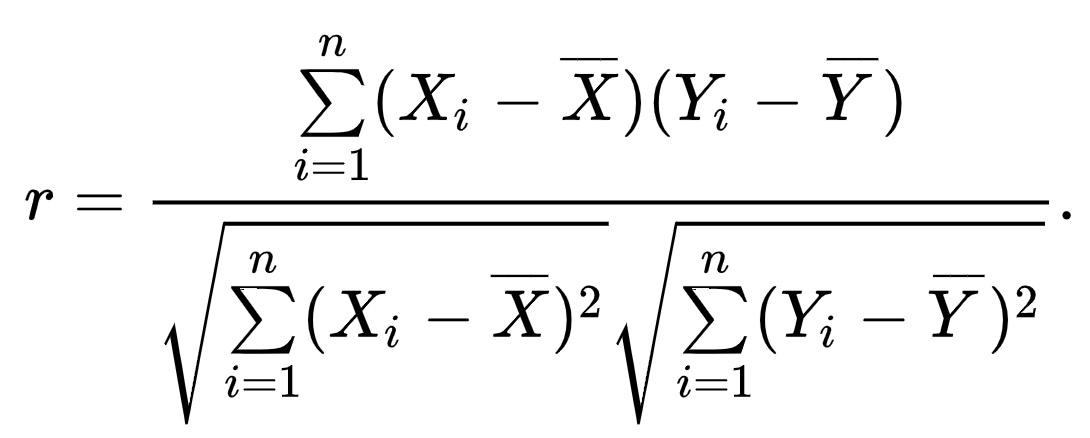
對於這個,並不陌生。皮爾遜相關係數在-1到1之間。0表示不相關,1表示極強正相關,-1表示極強負相關。
現在來簡單計算一下上面例子中,使用者A與使用者B之間的皮爾遜相關係數。
$\mu_A=(3.3+6.5+2.8+3.4+5.5)/5=4.3$
$\mu_B=(3.5+5.8+3.1+3.6+5.1)/5=4.22$
$\sum^n_{i=1}(X_i-\bar{X})(Y_i-\bar{Y})=7.49$
$\sum^n_{i=1}(X_i-\bar{X})^2=10.34$
$\sum^n_{i=1}(Y_i-\bar{Y})^2=5.428$
$r=\frac{7.49}{\sqrt{10.34}\sqrt{5.428}}=0.99978$
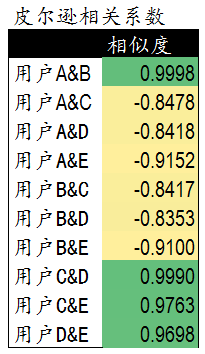
剩下的Pearson相關係數如下:
### 1.3 為相似的使用者提供商品
假設我們為使用者C推薦商品,**先檢查相似度列表**,發現使用者C和D、E的pearson係數較高。所以認為這三個使用者有相同的偏好,所以對C推薦D和E買過的商品。**但是不能推薦商品1~5,因為這些使用者C已經買過了。**
現在我們找到了使用者D和E買過的其他的商品A,B,C,D,E,F。**然後讓使用者D和E與使用者C的相似度作為權重** ,計算他們給這些商品打分的加權分數。然後給C按照加權分數從高到低進行推薦。

### 1.4 小結
已經講完了基於使用者的協同過濾演算法。這個演算法依靠使用者的歷史行為資料來計算相似度,所以是需要**一定的資料積累** ,這其中涉及到**冷啟動問題**。 對於新網站或者資料量較少的網站,一般會採用**基於物品的協同過濾方法**。
## 2 基於物品item-based
其實這個和基於使用者的方法很想,就是把商品和使用者互換。通過計算不同使用者對不同物品的評分獲得**物品間的關係**。然後根據物品間的關係對使用者進行相似物品的推薦。
所以這裡我們一開始的資料可以寫成這個樣子:
然後計算出物品之間的相關係數:
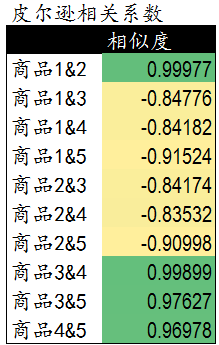
假設我們要給使用者C推薦商品。
在**基於使用者的演算法**中,我們的流程是:推薦給使用者C->尋找與使用者C相同愛好的使用者->尋找這些使用者購買的其他商品的加權打分。
現在**基於物品的演算法**中,我們的流程是。發現使用者C購買了商品4和5,找到同樣購買了4和5商品的其他使用者123.然後找到其他使用者123購買的新商品A、B、C
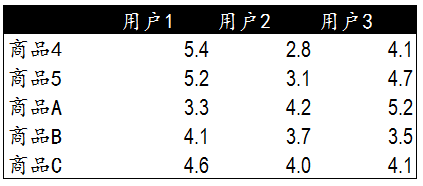
計算得到商品4和5與新商品ABC之間的相關度。
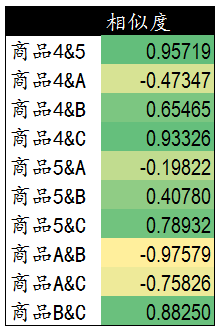
然後進行加權打分排序。
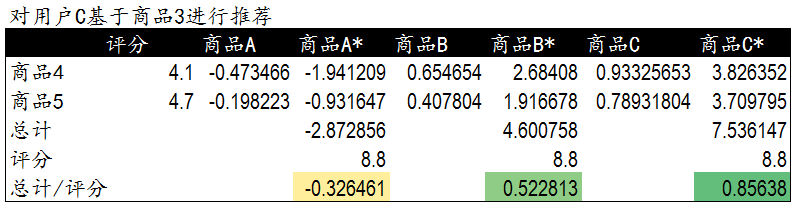
## 3 協同演算法的更多描述
- 協同演算法CF:Collaborative Filtering
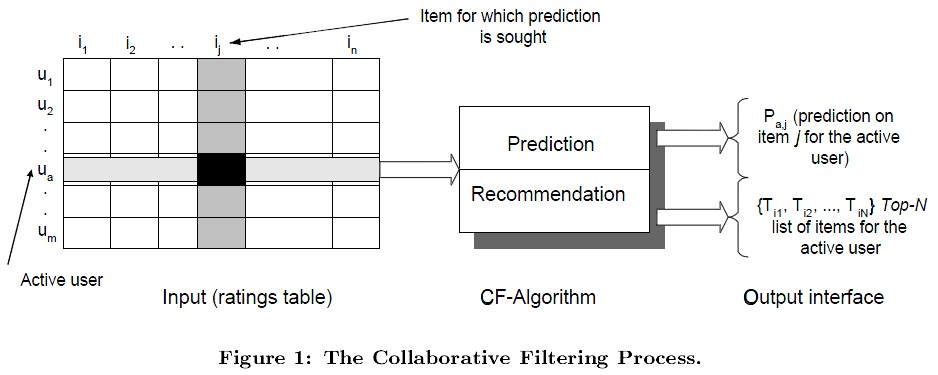
如上圖,協同演算法中,左邊的$m\times n$的矩陣中,m表示樣本的數量,n表示商品的數量。矩陣的數值表示使用者對某一個商品的喜好程度,分數越高表示越喜歡這個物品。0表示沒有買過該商品。
****
**【整個協同過濾包括兩個過程】**
- **預測過程** :預測使用者對沒有購買過的商品的可能打分值;
- **推薦過程** :根據預測階段的姐u共推薦使用者最可能喜歡的TopN個商品。
****
**【User-based & Item-based】**
User-based的基本思想就是使用者A喜歡物品a,使用者B喜歡物品abc,使用者C喜歡物品ac,那麼使用以相關係數為衡量的最近鄰演算法,可以把使用者C當成使用者A的最近的鄰居,而從推薦給A商品c。
Item-based的基本思想是現根據歷史資料計算物品之間的相似性,然後把使用者喜歡的相類似的物品推薦給使用者。因為我們知道喜歡a的使用者也喜歡c,所以推斷出物品a和c非常相似,這樣可以給購買過商品a的使用者推薦商品c。
****
**【User-based缺陷】**
1. 資料稀疏性。一個商場中一般有非常多的物品,而一個使用者可能只夠買過其中的1個商品,這樣的話不同使用者之間的物品重疊性非常低,從而導致無法找到一個使用者的鄰居(因為這個使用者與其他所有使用者的距離都相等,想象一下one-hot編碼)。
2. 演算法擴充套件性。最近鄰演算法的計算量會隨著使用者和物品數量的增加而增加,大資料的話浪費算力。
3. 冷啟動。一開始沒有歷史資料的話,無法使用這種方法進行推薦。
而Item-based的話,可以預先線上下先計算衝不同商品之間的相似度,然後把結果存在表中,推薦的時候直接查表。
## 4 不同相似度計算的方法
### 4.1 歐幾里得距離
這個就是差值平方的和的開方。
### 4.2 Pearson-r係數
這個就是之前詳細講解的相關係數。
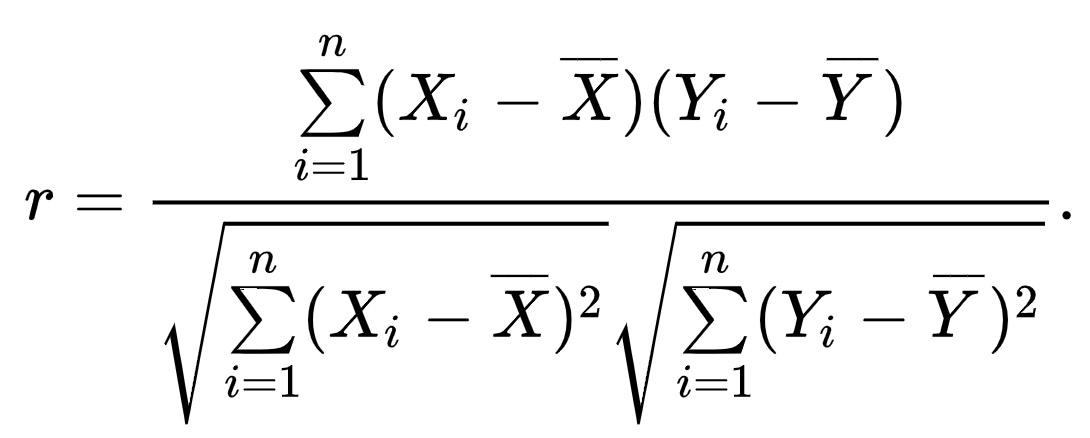
### 4.3 向量餘弦
通過計算兩個向量之間的夾角來計算物品的相似度。因為不同的使用者可能有不同的性格,可能有一個人給什麼東西打分都很高,另外一個人給什麼東西打分都低,這樣的話使用Pearson係數會判定這兩個人**偏好不同**,而向量餘弦會更加關注使用者給不同商品打分的相對情況。
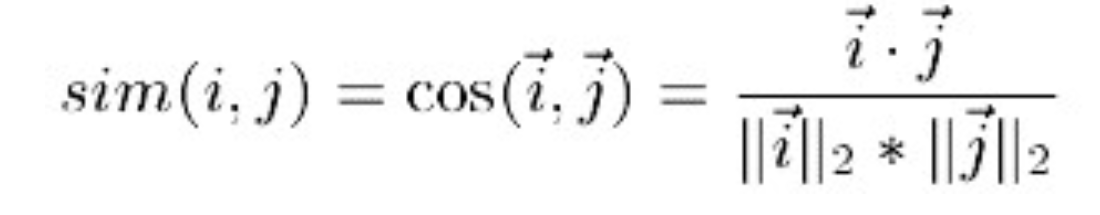
(PS:其中分子為兩個向量的內積,即兩個向量相同位置的數字相乘。)
### 4.4 調整餘弦
餘弦的優勢在於關注相對打分,但是這也是他的缺點。女生相對於籃球,更喜歡足球一些。男生也是如此。難道我們能說男生女生的喜好一致嗎?我們是不能推薦運動用品給這樣的女生的。然而餘弦相似度看不到這些,因為它只關注相對打分。
假設女生給籃球足球打分(1,2),男生打分(8,9)
【cosine】
$\frac{1*8+2*9}{\sqrt{5}\sqrt{64+81}} \approx 0.9656$
而Adjective Cosine是讓數值減去物品打分的均值,讓低於平均水平的打分變成負數。這下子向量的方向一下有一個巨大的改變。籃球的均分4.5,足球的均分5.5
【Adjecitve Cosine】
$\frac{(1-4.5)*(8-5.5)+(2-4.5)*(9-5.5)}{\sqrt{(1-4.5)^2+(2-4.5)^2}\sqrt{(8-5.5)^2+(9-5.5)^2}} \approx -0.945$
一下子就把差距體現出來了。
### 4.5 總結與個人感悟
可以看的出來,餘弦相似度存在一定的問題,所以**建議使用調整餘弦相似度與Pearson**。
【Adjective Cosine VS Pearson】
- Adjective Cosine中均值是所有使用者對同一商品打分的均值;
- Pearson中的均值是同一使用者對所有商品打分的均值。
## 5 預測使用者打分
之前提到了預測過程(預測使用者給為打分的商品的打分情況。)
### 5.1 加權求和平均
對使用者已經打分的物品的分數進行加權求和,而權值自然是**各個物品與預測物品之間的相似度**,然後再除以總權重值得和