
OpenCV計算機視覺學習(7)——影象金字塔(高斯金字塔,拉普拉斯金字塔)
如果需要處理的原圖及程式碼,請移步小編的GitHub地址
傳送門:請點選我
如果點選有誤:https://github.com/LeBron-Jian/ComputerVisionPractice
本節學習影象金字塔,影象金字塔包括高斯金字塔和拉普拉斯金字塔。它是影象中多尺度表達的一種,最主要用於影象的分割,是一種以多解析度來解釋影象的有效但概念簡單的結構。簡單來說,影象金字塔就是用來進行影象縮放的。
1,影象金字塔
影象金字塔是指一組影象且不同解析度的子圖集合,它是影象多尺度表達的一種,以多解析度來解釋影象的結構,主要用於影象的分割或壓縮。一幅影象的金字塔是一系列以金字塔性質排列的解析度逐步降低,且來源於同一張原始圖的影象集合,如下圖所示,它包括了五層影象,將這一層一層的影象比喻成金字塔。影象金字塔可以通過梯次向下取樣獲得,直到達到某個終止條件才停止取樣,在向下取樣中,層次越高,解析度越低。
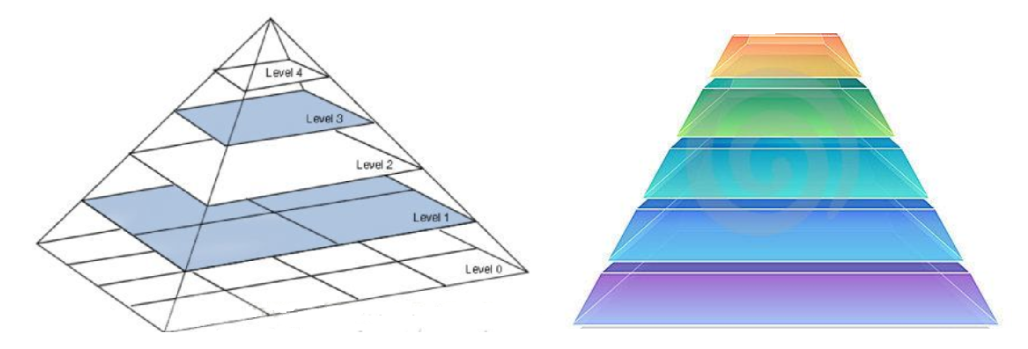
生成影象金字塔主要包括兩種方式——向下取樣,向上取樣,在上圖中,將level0級別的影象轉換為 level1,level2,level3,level4,影象解析度不斷降低的過程稱為向下取樣;將level4級別的影象轉換為 level3,level2,level1,leve0,影象解析度不斷增大的過程稱為向上取樣。
1.1 高斯金字塔
高斯金字塔用於下采樣。高斯金字塔是最基本的影象塔。原理:首先將原影象作為最底層影象 level0(高斯金字塔的第0層),利用高斯核(5*5)對其進行卷積,然後對卷積後的影象進行下采樣(去除偶數行和列)得到上一層影象G1,將此影象作為輸入,重複卷積和下采樣操作得到更上一層的影象,反覆迭代多次,形成一個金字塔形的影象資料結構,即高斯金字塔。
高斯金字塔是通過高斯平滑和亞取樣獲取一些列下采樣影象,也就是說第K層高斯金字塔通過平滑,亞取樣就可以獲得K+1 層高斯影象,高斯金字塔包含了一系列低通濾波器,其截止頻率從上一層到下一層是以因子 2 逐漸增加,所以高斯金字塔可以跨越很大的頻率範圍。
1.2 拉普拉斯金字塔
拉普拉斯金字塔用於重建圖形,也就是預測殘差,對影象進行最大程度的還原。比如一幅小影象重建為一幅大圖。原理:用高斯金字塔的每一層影象減去其上一層影象上取樣並高斯卷積之後的預測影象,得到一系列的差值影象,即為Laplacian分解影象。
拉普拉斯影象的形成過程大致為對原影象進行低通濾波和降取樣得到一個粗尺度的近似影象,即分解得到的低通近似影象,把這個近似影象經過插值,濾波,再計算它和原影象的插值,就得到分解的帶通分量。下一級分解是在得到的低通近似影象上進行,迭代完成多尺度分解。可以看出拉普拉斯金字塔的分解過程包括四個步驟:
- 1,低通濾波
- 2,降取樣(縮小尺寸)
- 3,內插(放大尺寸)
- 4,帶通濾波(影象相減)
拉普拉斯影象突出影象中的高頻分量,注意的是拉普拉斯的最後一層是低通濾波影象,不是帶通濾波影象。
我們對影象進行縮放可以用影象金字塔,也可以使用resize函式進行縮放,後者效果更好(我們後面補充resize影象縮放)。這裡只是對影象金字塔做一些簡單瞭解。
下面分別學習影象向下取樣和向上取樣(下采樣就是圖片縮小,上取樣就是圖片放大)。
2,影象向下取樣
2.1 高斯金字塔——向下取樣(縮小)
在影象向下取樣中,使用最多的是高斯金字塔。它將堆影象Gi進行高斯核卷積,並刪除原圖中所有的偶數行和列,最終縮小影象。其中,高斯核卷積運算就是對整幅影象進行加權平均的過程,每一個畫素點的值,都由其本身和鄰域內的其他畫素值(券種不同)經過加權平均後得到。常見的 3*3 和 5*5 高斯核如下:
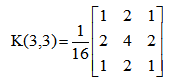


高斯核卷積讓臨近中心的畫素點具有更高的重要度,對周圍畫素計算加權平均值,如下圖所示,其中心位置權重最高為 0.4。

顯而易見,原始影象 Gi 具有 M*N 個畫素,進行向下取樣之後,所得到的影象 Gi+1 具有 M/2 * N/2 個畫素,只有原圖的四分之一。通過對輸入的原始影象不停迭代以上步驟就會得到整個金字塔。注意,由於每次向下取樣會刪除偶數行和列,所以它會不停地丟失影象的資訊。
在OpenCV中,向下取樣使用的函式為 pyrDown() ,其函式原型如下:
dst = pyrDown(src[, dst[, dstsize[, borderType]]])
cv2.pyrDown 使用Gaussian金字塔分解對輸入影象向下取樣。首先它對輸入影象用指定濾波器進行卷積,然後通過拒絕偶數的行和列來下采樣影象。
其引數意思如下:
- src表示輸入影象,
- dst表示輸出影象,和輸入影象具有一樣的尺寸和型別
- dstsize表示輸出影象的大小,預設值為Size(5*5)
- borderType表示畫素外推方法,詳見cv::bordertypes
實現程式碼如下:
# _*_coding:utf-8 _*_
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 讀取原始圖片
img = cv2.imread('kd2.jpg')
# 影象向下取樣
r = cv2.pyrDown(img)
# # 顯示圖形
# cv2.imshow('origin image', img)
# cv2.imshow('processing image', r)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# 為了方便將兩張圖對比,我們使用matplotlib
titles = ['origin', 'pyrDown']
images = [img, r]
for i in np.arange(2):
plt.subplot(1, 2, i+1), plt.imshow(images[i])
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
我們可以先看OpenCV畫的圖,然後看兩張圖放一樣大的效果圖。
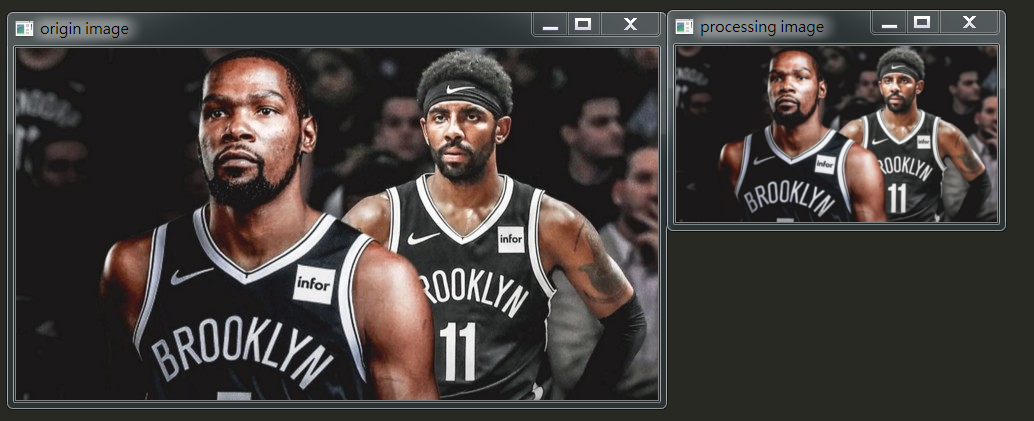
我們從上圖可以看出,向下取樣將原始影象壓縮成原圖的四分之一。
很明顯比起第一張圖,第二張圖有點模糊了。
多次向下取樣的程式碼:
# _*_coding:utf-8 _*_
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 讀取原始圖片
img = cv2.imread('kd2.jpg')
# 影象向下取樣
r1 = cv2.pyrDown(img)
r2 = cv2.pyrDown(r1)
r3 = cv2.pyrDown(r2)
# 為了方便將兩張圖對比,我們使用matplotlib
titles = ['origin', 'pyrDown1', 'pyrDown2', 'pyrDown3']
images = [img, r1, r2, r3]
for i in np.arange(4):
plt.subplot(2, 2, i+1), plt.imshow(images[i])
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
結果如圖所示:

雖然我將影象展示的一樣大小,但是我們可以很清楚的看到影象向下取樣越多,影象越模糊。
3,影象向上取樣
3.1 高斯金字塔——向上取樣(放大)
在影象向上取樣是由小影象不斷放影象的過程,它將影象在每個方向上擴大為原影象的2倍,新增的行和列均使用0來填充,並使用於“向下取樣”相同的卷積核乘以4,再與放大後的影象進行卷積運算,以獲得“新增畫素”的新值,如下所示,它在原始畫素45, 123, 89, 149之間各新增了一行和一列值為0的畫素。

在OpenCV中,向上取樣使用的函式為 pyrUp(),其原型如下所示:
dst = pyrUp(src[, dst[, dstsize[, borderType]]])
cv2.PyrUp() 是使用Gaussian金字塔分解對輸入影象向上取樣。首先通過在影象中插入 0 偶數行和偶數列,然後對得到的影象用指定的濾波器進行高斯卷積。其中濾波器乘以4做插值。所以輸出影象是輸入影象的2倍大小。
- src表示輸入影象,
- dst表示輸出影象,和輸入影象具有一樣的尺寸和型別
- dstsize表示輸出影象的大小,預設值為Size()
- borderType表示畫素外推方法,詳見cv::bordertypes
實現程式碼如下:
# _*_coding:utf-8 _*_
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 讀取原始圖片
img = cv2.imread('kd2.jpg')
# 影象向下取樣
r1 = cv2.pyrUp(img)
# 顯示圖形
cv2.imshow('origin image', img)
cv2.imshow('processing image1', r1)
cv2.waitKey(0)
cv2.destroyAllWindows()
由於放大了四倍,圖太大,我就這樣放了:
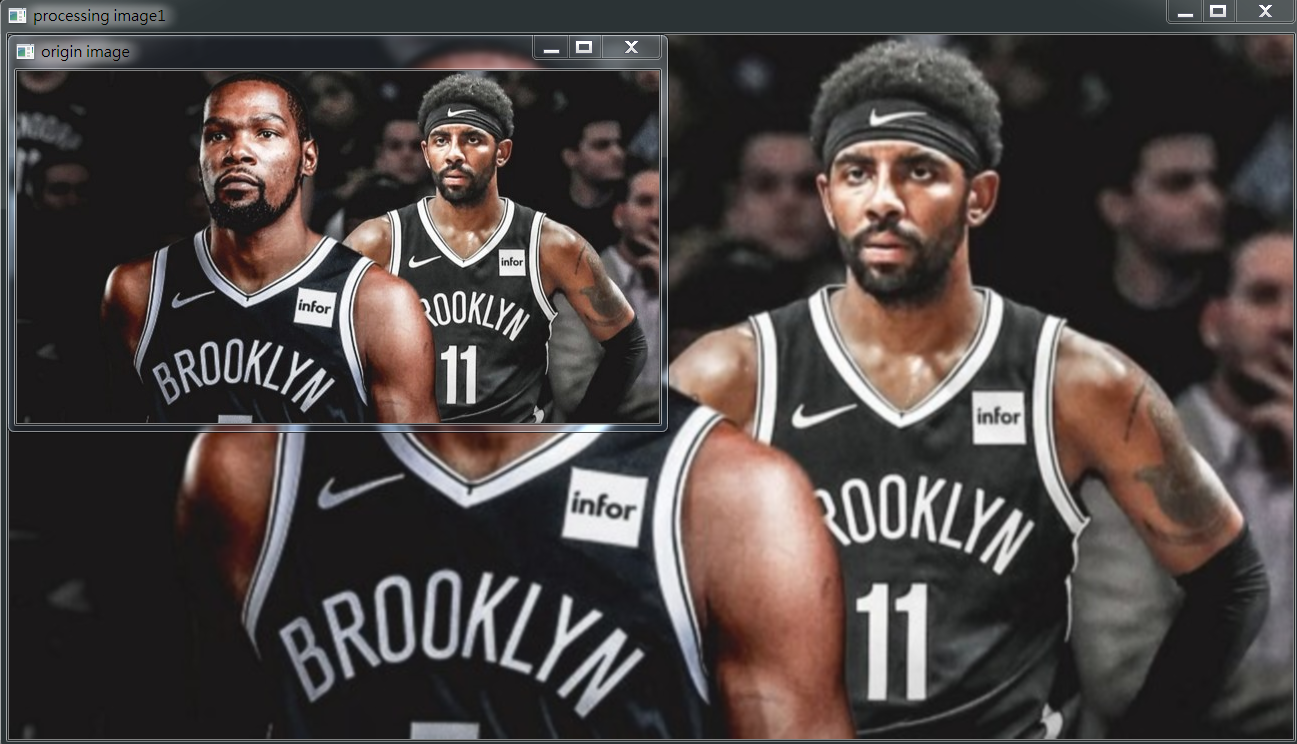
多次向上取樣的程式碼如下:
# _*_coding:utf-8 _*_
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 讀取原始圖片
img = cv2.imread('kd2.jpg')
# 影象向下取樣
r1 = cv2.pyrUp(img)
r2 = cv2.pyrUp(r1)
r3 = cv2.pyrUp(r2)
# 為了方便將兩張圖對比,我們使用matplotlib
titles = ['origin', 'pyrUp1', 'pyrUp2', 'pyrUp3']
images = [img, r1, r2, r3]
for i in np.arange(4):
plt.subplot(2, 2, i+1), plt.imshow(images[i])
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
結果如下:

每次向上取樣均為上次影象的四倍,但影象的清晰度會降低。
4,拉普拉斯金字塔
影象的拉普拉斯金字塔可以由影象的高斯金字塔得到,沒有單獨的函式。拉普拉斯金字塔影象是邊緣圖片,大部分元素是零,它被用在影象壓縮上,拉普拉斯金字塔的一級是由那一級的高斯金字塔和它的更高一級高斯金字塔的影象差別來生成的。
轉換的公式為:
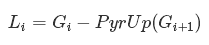

拉普拉斯金字塔的程式碼實現:
import cv2
import numpy as np
img = cv2.imread('kd2.jpg')
down = cv2.pyrDown(img)
down_up = cv2.pyrUp(down)
l_1 = img - down_up
cv2.imshow('laplacian', l_1)
cv2.waitKey(0)
cv2.destroyAllWindows()
效果圖如下:

拉普拉斯金字塔的影象看起來就像是邊界圖。經常被用在影象壓縮中。
5,總結上取樣和下采樣
上面對兩種取樣做了程式碼實現,下面再贅述一次。
上取樣:就是圖片放大,使用PryUp函式。上取樣的步驟:先將影象在每個方向放大為原來的兩倍,新增的行和列用0填充,再使用先前同樣的核心與放大後的影象卷積,獲得新增畫素的近似值。
下采樣:就是圖片縮小,使用PyrDown函式。下采樣步驟:先將圖片進行高斯核心卷積,再將所有偶數列去除。
注意:PryUP() 和 PyrDown() 不是互逆的,即上取樣和下采樣的不是互為逆操作。
總之,上,下采樣都存在一個嚴重的問題,那就是影象變模糊了,因為縮放的過程中發生了資訊丟失的問題。要解決這個問題,就得用拉普拉斯金字塔。
當然也可以直接使用 cv2裡面的resize()函式,resize()函式的效果更好,下面我們學習一下使用resize()函式進行影象縮放。
6, 影象縮放——resize()函式
cv2.resize()函式是opencv中專門來調整圖片的大小,改變圖片尺寸。
注意:CV2是BGR,而我們讀取的圖片是RGB,所以要注意一下,變換的時候注意對應。
其函式原型如下:
def resize(src, dsize, dst=None, fx=None, fy=None, interpolation=None)
對應的各個引數意思:
src:輸入,原影象,即待改變大小的影象;
dsize:輸出影象的大小。如果這個引數不為0,那麼就代表將原影象縮放到這個Size(width,height)指定的大小;如果這個引數為0,那麼原影象縮放之後的大小就要通過下面的公式來計算:
dsize = Size(round(fx*src.cols), round(fy*src.rows))
其中,fx和fy就是下面要說的兩個引數,是影象width方向和height方向的縮放比例。
fx:width方向的縮放比例,如果它是0,那麼它就會按照(double)dsize.width/src.cols來計算;
fy:height方向的縮放比例,如果它是0,那麼它就會按照(double)dsize.height/src.rows來計算;
interpolation:這個是指定插值的方式,影象縮放之後,肯定畫素要進行重新計算的,就靠這個引數來指定重新計算畫素的方式,有以下幾種:
- INTER_NEAREST - 最鄰近插值
- INTER_LINEAR - 雙線性插值,如果最後一個引數你不指定,預設使用這種方法
- INTER_AREA - 區域插值(使用畫素區域關係進行重取樣) resampling using pixel area relation. It may be a preferred method for image decimation, as it gives moire’-free results. But when the image is zoomed, it is similar to the INTER_NEAREST method.
- INTER_CUBIC - 三次樣條插值 (超過4x4畫素鄰域內的雙立方插值)
- INTER_LANCZOS4 - Lanczos插值(超過8x8畫素鄰域內的Lanczos插值)
對於插值方法,正常情況下使用預設的雙線性插值法就夠了。不過這裡還是有建議的:若要縮小影象,一般情形下最好用 CV_INTER_AREA 來插值,而若要放大影象,一般情況下最好用 CV_INTER_CUBIC (效率不高,慢,不推薦使用)或 CV_INTER_LINEAR (效率較高,速度較快,推薦使用)
幾種常用方法的效率為:
最鄰近插值>雙線性插值>雙立方插值>Lanczos插值
但是效率和效果是反比的,所以根據自己的情況酌情使用。
注意:輸出的尺寸格式為(寬,高)
示例:
# _*_coding:utf-8_*_
import cv2
import numpy as np
image = cv2.imread('cat.jpg')
# 對圖片進行灰度化,注意這裡變換!!
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
crop_img = cv2.resize(gray, (224, 224), interpolation=cv2.INTER_LANCZOS4)
print(image.shape, gray.shape, crop_img.shape)
# (414, 500, 3) (414, 500) (224, 224)
cv2.imshow('result', crop_img)
cv2.waitKey()
cv2.detrosyAllWindows()
效果如下:

對影象縮放,做一個完整的示例:
import cv2
import os
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread("cat.jpg")
# resize的插值方法:正常情況下使用預設的雙線性插值法
res_img = cv2.resize(img, (200, 100))
res_fx = cv2.resize(img, (0, 0), fx=0.5, fy=1)
res_fy = cv2.resize(img, (0, 0), fx=1, fy=0.5)
print('origin image shape is ',img.shape)
print('resize 200*100 image shape is ',res_img.shape)
print('resize 0.5:1 shape is ',res_fx.shape)
print('resize 1:0.5 image shape is ',res_fy.shape)
'''
origin image shape is (414, 500, 3)
resize 200*100 image shape is (100, 200, 3)
resize 0.5:1 shape is (414, 250, 3)
resize 1:0.5 image shape is (207, 500, 3)
'''
# 標題
title = ['Origin Image', 'resize200*100', 'resize_fx/2', 'resize_fy/2']
# 對應的影象
image = [img, res_img, res_fx, res_fy]
for i in range(len(image)):
plt.subplot(2, 2, i+1), plt.imshow(image[i])
plt.title(title[i])
plt.xticks([]), plt.yticks([])
plt.show()
效果圖如下:

參考文獻:https://blog.csdn.net/Eastmount/article/details/89341077
https://www.cnblogs.com/FHC1994/p/9128005.html
https://www.cnblogs.com/zsb517/archive/2012/06/10/2543739.