
OpenCV計算機視覺學習(11)——影象空間幾何變換(影象縮放,影象旋轉,影象翻轉,影象平移,仿射變換,映象變換)
如果需要處理的原圖及程式碼,請移步小編的GitHub地址
傳送門:請點選我
如果點選有誤:https://github.com/LeBron-Jian/ComputerVisionPractice
影象的幾何變換是在不改變影象內容的前提下對影象畫素進行空間幾何變換,主要包括了影象的平移變換,縮放,旋轉,翻轉,映象變換等。
1,幾何變換的基本概念
1.1 座標對映關係
影象的幾何變換改變了畫素的空間位置,建立一種原影象畫素與變換後圖像畫素之間的對映關係,通過這種對映關係能夠實現下面兩種計算:
- 1,原影象任意畫素計算該畫素在變換後圖像的座標位置
- 2,變換後圖像的任意畫素在原影象的座標位置
對於第一種計算,只要給出原影象上的任意畫素座標,都能通過對應的對映關係獲得到該畫素在變換後圖像的座標位置。將這種輸入影象座標對映到輸出的過程稱為“向前對映”。反過來,知道任意變換後圖像上的畫素座標,計算其在原影象的畫素座標,將輸出影象對映到輸入的過程稱為“向後對映”。但是,在使用向前對映處理幾何變換時卻有一些不足,通常會產生兩個問題:對映不完全,對映重疊。
1,對映不完全
輸入影象的畫素總數小於輸出影象,這樣輸出影象中的一些畫素找不到在原影象中的對映。
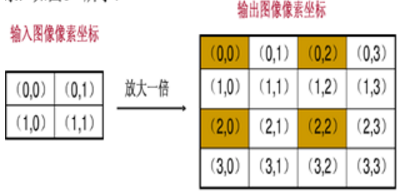
上圖中只有四個座標點根據對映關係在原影象找到了相對應的畫素,其餘12個座標沒有有效值。
2,對映重疊
根據對映關係,輸入影象的多個畫素對映到輸出影象的同一個畫素上。
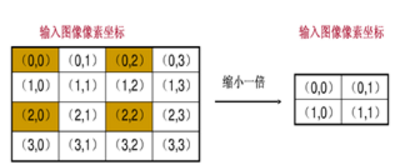
上面左上角的四個畫素都會對映到輸出影象的(0, 0)那麼我們輸出的(0,0)應該取那個畫素值呢?
要解決上述兩個問題可以使用“向後對映”,使用輸出影象的座標反過來推算改座標對應於原影象中的座標位置。這樣,輸出影象的每個畫素都可以通過對映關係在原影象中找到唯一對應的畫素,而不會出現對映不完全和對映重疊。所以,一般使用向後對映來處理影象的幾何變換。從上面也可以看出,向前對映之所以會出現問題,主要是由於影象畫素的總數發生了變換,也就是影象的大小改變了。在一些影象大小不會發生變化的變換中,向前對映還是很有效的。
1.2 插值演算法
對於數字影象而言,畫素的座標是離散型非負整數,但是在進行變換的過程中有可能產生浮點座標值。例如,原影象座標(9, 9)在縮小一倍時會變成(4.5, 4.5),這顯然是一個無效的座標。插值演算法就是用來處理這些浮點座標的。常見的插值演算法有最鄰近插值法,雙線性插值法,二次立方插值法,三次立方插值法等。這裡主要學習最鄰近插值和雙線性插值。
最鄰近插值
最鄰近插值法,也成為零階插值法,最簡單插值演算法,當然效果也是最差的。它的思想相當簡單,就是四捨五入,浮點座標的畫素值等於距離該點最近的輸入影象的畫素值。
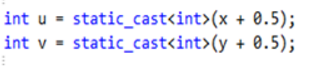
上面的C程式碼可以求得(x, y)的最鄰近插值座標(u, v)。
最鄰近插值幾乎沒有多餘的運算,速度相當快,但是這種鄰近取值的方法是很粗糙的,會造成影象的馬賽克,鋸齒等現象。
雙線性插值法
雙線性插值法,又稱為雙線性內插。在數學上,雙線性插值是有兩個變數的插值函式的線性插值擴充套件,其核心思想是在兩個方向分別進行一次線性插值。
雙線性插值法作為數值分析的一種插值演算法,廣泛應用在訊號處理,數字影象和視訊處理等方面。
下面舉個簡單的例子,假設要求座標為(2.4, 3)的畫素值P,該點在(2, 3)和(3, 3)之間,如下圖:

u 和 v 分別是距離浮點座標最近兩個整數座標畫素在浮點座標畫素所佔的比例。
P(2.4, 3) = u * P(2, 3) + v * P(3, 3),混合的比例是以距離為依據的,那麼u = 0.4, v = 0.6。上面是隻在一條直線的插值,稱為線性插值。雙線性插值就是分別在x軸和Y軸上做線性插值運算。
已知的紅色資料點與待插值得到的綠色點。
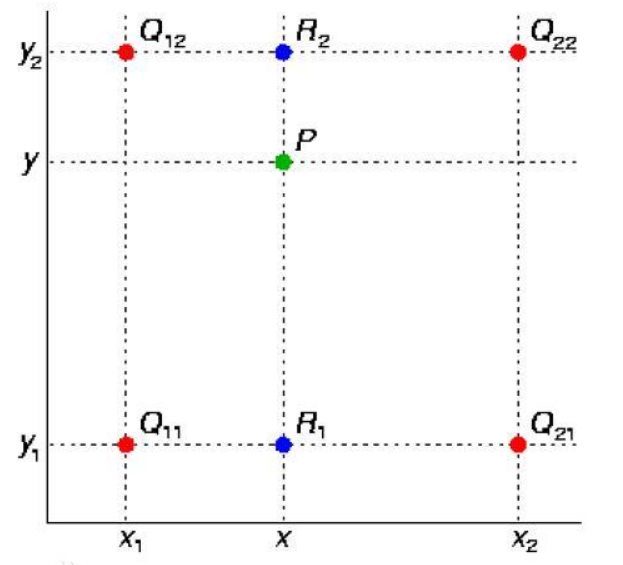
假如我們想得到未知函式 f 在點 P=(x, y) 的值,假設我們已知函式f 在Q11 = (x1, y1),Q12 = (x1,y2),Q21 = (x2,y1) 以及Q22 = (x2,y2) 四個點的值。
首先在x方向進行線性插值,得到R1, R2,然後在y方向進行線性插值,得到P。這樣就得到所要的結果 f(x, y)
其中紅色點Q11, Q12, Q21, Q22為已知的4個畫素點。
第一步:X方向的線性插值,在Q12, Q22中插入藍色點R2, Q11, Q21 中插入藍色點R1
第二步:Y方向的線性插值,通過第一步計算出的R1與R2在y方向上的插值計算出P點。
線性插值的結果與插值的順序無關,首先進行y方向的插值,然後進行X方向的插值,所得到的結果是一樣的,雙線性插值的結果與先進行哪個方向的插值無關。
在X方向上:
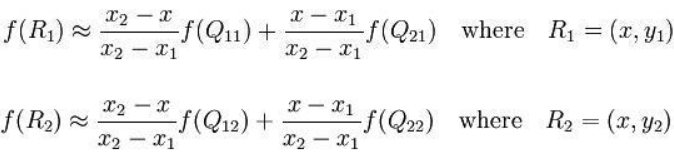
在y方向上:
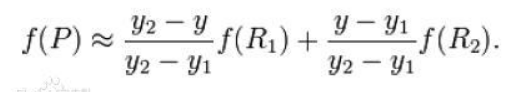
如果選擇一個座標系統使得四個已知的點座標分別為(0, 0)(0, 1) (1, 0) (1, 1),那麼插值公式就可以簡化為:
f(x,y)=f(0,0)(1-x)(1-y)+f(1,0)x(1-y)+f(0,1)(1-x)y+f(1,1)xy
在x與y方向上,z值成單調性特性的應用中,此種方法可以做外插運算,即可以求解Q1~Q4所構成的正方形以外的點的值。
2,影象縮放
影象縮放主要用於改變影象的大小,縮放後圖像的寬度和高度會發生變換。水平縮放係數,控制影象寬度的縮放,其值為1,則影象的寬度不變;垂直縮放係數控制影象高度的縮放,其值為1,則影象高度不變。如果水平縮放和垂直縮放係數不相等,那麼縮放後圖像的寬度和高度的比例會發生變換,會使影象變形。要保持影象寬度和高度的比例不發生變換,就需要水平縮放係數和垂直縮放係數相等。
2.1 影象縮放原理
設水平縮放係數為Sx,垂直縮放係數為Sy,(x0, y0)為縮放前座標,(x, y)為縮放後坐標,其縮放的座標對映關係為:
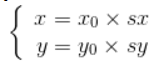
矩陣表示的形式為:
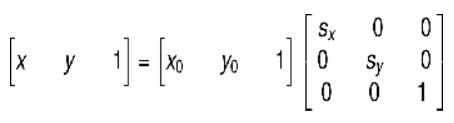
這是前向對映,在縮放的過程改變了影象的大小,使用前向對映會出現對映重疊和對映不完全的問題,所以這裡更關係的是向後對映,也就是輸出影象通過向後對映關係找到其在原影象中對應的畫素。
向後對映關係:
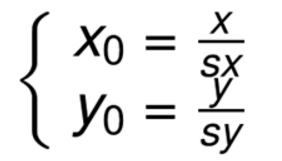
2.2 基於OpenCV的縮放實現
在影象縮放時,首先要計算縮放後圖像的大小,設 newWidth,newHeight為縮放後的影象的寬和高,width,height為原影象的寬度和高度,那麼有:

然後遍歷縮放後的影象,根據向後對映關係計算出縮放的畫素在原影象中畫素的位置,如果得到的浮點座標,就需要使用插值演算法取得近似的畫素值。
影象縮放主要呼叫 resize() 函式實現,具體如下:
def resize(src, dsize, dst=None, fx=None, fy=None, interpolation=None)
其中對應的各個引數意思:
src:輸入,原影象,即待改變大小的影象;
dsize:輸出影象的大小。如果這個引數不為0,那麼就代表將原影象縮放到這個Size(width,height)指定的大小;如果這個引數為0,那麼原影象縮放之後的大小就要通過下面的公式來計算:
dsize = Size(round(fx*src.cols), round(fy*src.rows))
其中,fx和fy就是下面要說的兩個引數,是影象width方向和height方向的縮放比例。
fx:width方向的縮放比例,如果它是0,那麼它就會按照(double)dsize.width/src.cols來計算;
fy:height方向的縮放比例,如果它是0,那麼它就會按照(double)dsize.height/src.rows來計算;
interpolation:這個是指定插值的方式,影象縮放之後,肯定畫素要進行重新計算的,就靠這個引數來指定重新計算畫素的方式,有以下幾種:
- INTER_NEAREST - 最鄰近插值
- INTER_LINEAR - 雙線性插值,如果最後一個引數你不指定,預設使用這種方法
- INTER_AREA - 使用畫素區域關係進行重取樣 resampling using pixel area relation. It may be a preferred method for image decimation, as it gives moire’-free results. But when the image is zoomed, it is similar to the INTER_NEAREST method.
- INTER_CUBIC - 4x4畫素鄰域內的雙立方插值
- INTER_LANCZOS4 - 8x8畫素鄰域內的Lanczos插值
對於插值方法,正常情況下使用預設的雙線性插值法就夠了。幾種常用方法的效率為:
最鄰近插值>雙線性插值>雙立方插值>Lanczos插值
但是效率和效果是反比的,所以根據自己的情況酌情使用。
注意:輸出的尺寸格式為(寬,高)
dsize與 fx和fy 兩個設定一個即可實現影象縮放,例如:
- result = cv2.resize(src, (160,160))
- result = cv2.resize(src, None, fx=0.5, fy=0.5)
影象縮放:設(x0, y0)是縮放後的座標,(x, y)是縮放前的座標,sx, sy為縮放因子,則公式如下:
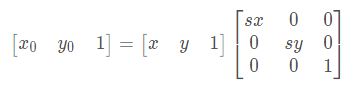
程式碼1如下(dsize中第一個是列數 第二個是函式):
# encoding:utf-8
import cv2
import numpy as np
# 讀取圖片
src = cv2.imread('test.jpg')
# 影象縮放
result = cv2.resize(src, (200, 100))
print(result.shape)
# 顯示影象
cv2.imshow("src", src)
cv2.imshow("result", result)
# 等待顯示
cv2.waitKey(0)
cv2.destroyAllWindows()
程式碼2如下:(獲取原始影象畫素再乘以縮放係數進行影象變換)
#encoding:utf-8
import cv2
import numpy as np
#讀取圖片
src = cv2.imread('test.jpg')
rows, cols = src.shape[:2]
print rows, cols
#影象縮放 dsize(列,行)
result = cv2.resize(src, (int(cols*0.6), int(rows*1.2)))
#顯示影象
cv2.imshow("src", src)
cv2.imshow("result", result)
#等待顯示
cv2.waitKey(0)
cv2.destroyAllWindows()
程式碼3如下:((fx , fy)縮放倍數的方法對影象進行放大或縮小)
#encoding:utf-8
import cv2
import numpy as np
#讀取圖片
src = cv2.imread('test.jpg')
rows, cols = src.shape[:2]
print rows, cols
#影象縮放
result = cv2.resize(src, None, fx=0.3, fy=0.3)
#顯示影象
cv2.imshow("src", src)
cv2.imshow("result", result)
#等待顯示
cv2.waitKey(0)
cv2.destroyAllWindows()
3,影象旋轉
3.1 影象旋轉的原理
影象的旋轉就是讓影象按照某一點旋轉指定的角度。影象旋轉後不會變形,但是其垂直對稱軸和水平對稱軸都會發生改變,旋轉後的影象的座標和原影象座標之間的關係已不能通過簡單的加減乘法得到,而需要通過一系列的複雜運算。而且影象在旋轉後其寬度和高度都會發生變換,其座標原點會發生變換。
影象所用的座標系不是常用的笛卡爾,其左上角是其座標原點,X軸沿著水平方向向右,Y軸沿著豎直方向向下。而在旋轉的過程一般使用旋轉中心未座標原點的笛卡爾座標系,所以影象旋轉的第一步就是座標系的變換。設旋轉中心未(x0, y0),(x', y')是旋轉後的座標,(x, y)是旋轉後的座標,則座標變換如下:
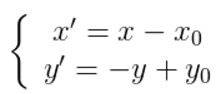
矩陣表示為:
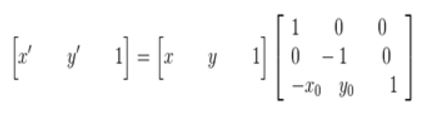
在最終的實現中,常用到的是有縮放後的影象通過對映關係找到其座標在原影象中的相應位置,這就需要上述對映的逆變換:
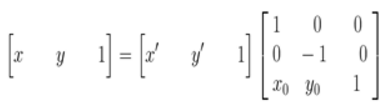
座標系變換到以旋轉中心為原點後,接下來就要對影象的座標進行變換。
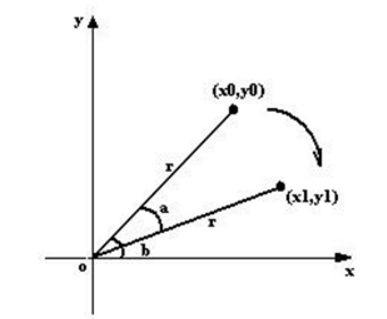
上圖所示,將座標(x0, y0)順時針方向旋轉 a,得到(x1, y1)。旋轉前有:

旋轉a後有:
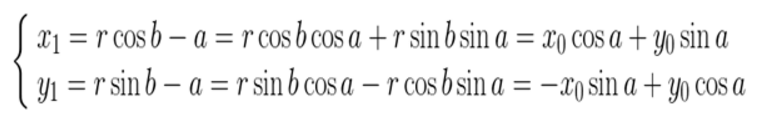
矩陣的表示形式:
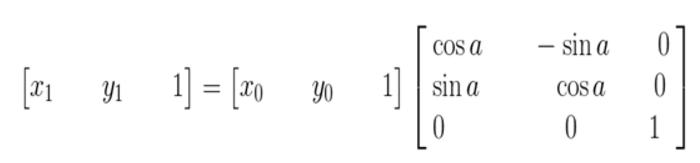 其逆變換:
其逆變換:
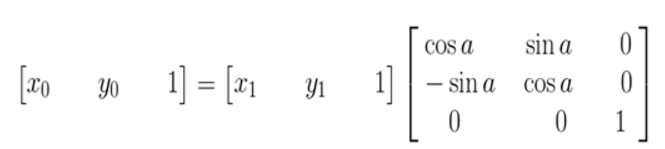
由於在旋轉的時候是以旋轉中心未座標原點的,旋轉結束後還需要將座標原點移到影象左上角,也就是還要進行一次變換。這裡需要注意的是,旋轉中心的座標(x0, y0)是在以原影象的左上角為座標原點的座標系中得到,而在旋轉後由於影象的寬和高發生了變換,也就導致了旋轉後圖像的座標原點和旋轉前的發生了變換。

上面兩圖可以清晰的看到,旋轉前後影象的左上角,也就是座標原點發生了變換。
在求影象旋轉後左上角的座標前,先來看看旋轉後圖像的寬和高。從上圖可以看出,旋轉後圖像的寬和高與原影象的四個角旋轉後的位置有關。
設top為旋轉後最高點的縱座標,down為旋轉後最低點的縱座標,left為旋轉後最左邊點的橫座標,right為旋轉後最右邊點的橫座標。
旋轉後的寬和高為 newWidth,newHeight,則可以得到下面的關係:

也就很容易的得出旋轉後圖像左上角座標(left,top)(以旋轉中心為原點的座標系),故在旋轉完成後要將座標系轉換為以影象的左上角為座標原點,可由下面變換關係得到:
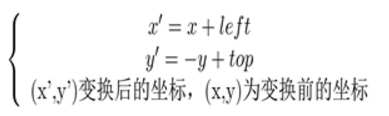
矩陣表示:

其逆變換:
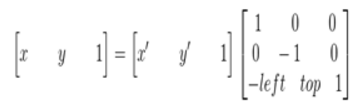 綜合以上,也就是說原影象的畫素座標要經過三次的座標變換:
綜合以上,也就是說原影象的畫素座標要經過三次的座標變換:
- 1,將座標原點由影象的左上角變換到旋轉中心
- 2,以旋轉中心為原點,影象旋轉角度a
- 3,旋轉結束後,將座標原點變換到旋轉後圖像的左上角
可以得到下面的旋轉公式:(x', y')旋轉後的座標,(x, y)原座標,(x0, y0)旋轉中心,a旋轉的角度(順時針)
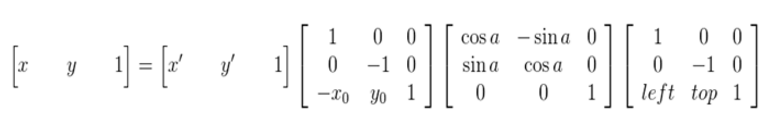
這種由輸入影象通過對映得到輸出影象的座標,是向前對映。常用的向後對映是其逆運算
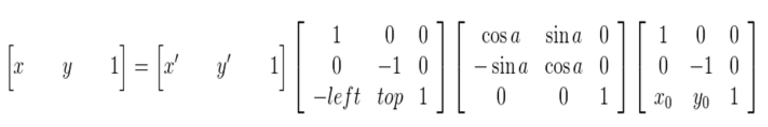
3.2 基於OpenCV實現影象旋轉
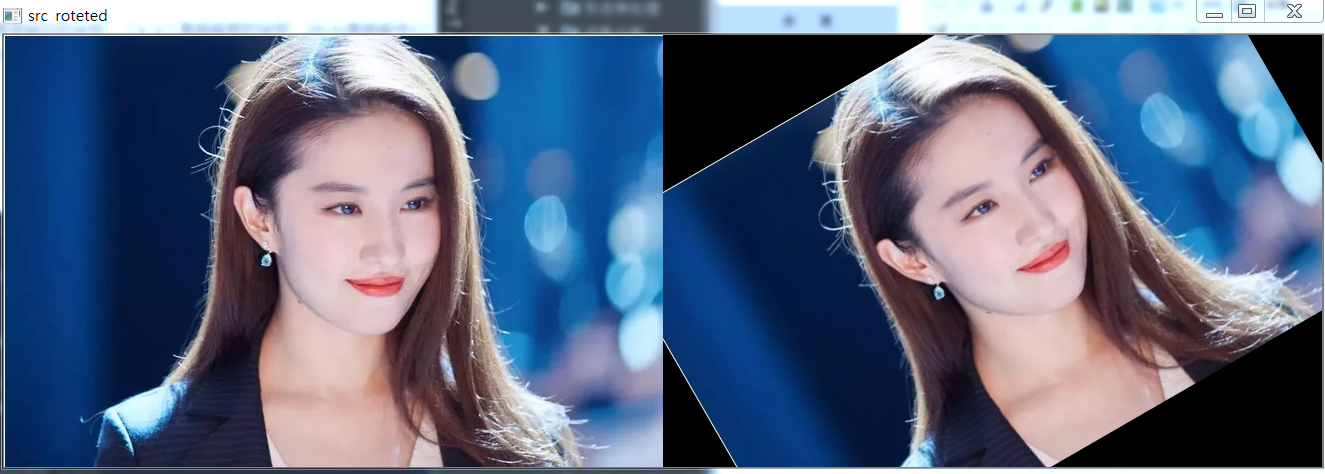
影象旋轉主要呼叫 getRotationMatrix2D() 函式和 wrapAffine() 函式實現,繞影象的中心旋轉,具體如下:
M = cv2.getRotationMatrix2D((cols/2, rows/2), 30, 1) 引數分別為:旋轉中心、旋轉度數、scale rotated = cv2.warpAffine(src, M, (cols, rows)) 引數分別為:原始影象、旋轉引數、原始影象寬高
影象旋轉:設(x0, y0)是旋轉後的座標,(x, y)是旋轉前的座標,(m ,n)是旋轉中心,a是旋轉的角度,(left, top)是旋轉後圖像的左上角座標,則公式如下:
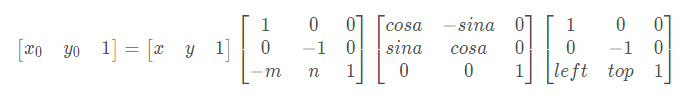
程式碼如下:
# encoding:utf-8
import cv2
import numpy as np
# 讀取圖片
src = cv2.imread('test.jpg')
# 原圖的高、寬 以及通道數
rows, cols, channel = src.shape
# 繞影象的中心旋轉
# 引數:旋轉中心 旋轉度數 scale
M = cv2.getRotationMatrix2D((cols / 2, rows / 2), 30, 1)
# 引數:原始影象 旋轉引數 元素影象寬高
rotated = cv2.warpAffine(src, M, (cols, rows))
res = np.column_stack((src, rotated))
# 顯示影象
cv2.imshow("src roteted", res)
# cv2.imshow("src", src)
# cv2.imshow("rotated", rotated)
# 等待顯示
cv2.waitKey(0)
cv2.destroyAllWindows()
效果如下:
如果設定 -90度,則核心程式碼如下:
M = cv2.getRotationMatrix2D((cols/2, rows/2), -90, 1) rotated = cv2.warpAffine(src, M, (cols, rows))
4,影象翻轉
影象翻轉在OpenCV中呼叫函式 flip() 實現,原型如下:
dst = cv2.flip(src, flipCode)
其中 src表示原始影象,flipCode表示翻轉方向(如果flipCode為0,則以X軸為對稱軸翻轉,如果flipCode>0,則以Y軸為對稱軸翻轉,如果flipCode<0,則在X軸,Y軸方向同時翻轉)
程式碼如下:
#encoding:utf-8
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取圖片
img = cv2.imread('test.jpg')
src = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
#影象翻轉
#0以X軸為對稱軸翻轉 >0以Y軸為對稱軸翻轉 <0X軸Y軸翻轉
img1 = cv2.flip(src, 0)
img2 = cv2.flip(src, 1)
img3 = cv2.flip(src, -1)
#顯示圖形
titles = ['Source', 'Image1', 'Image2', 'Image3']
images = [src, img1, img2, img3]
for i in range(4):
plt.subplot(2,2,i+1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
效果如下:

5,影象平移
影象的平移變換就是將影象所有的畫素座標分別加上指定的水平偏移量和垂直偏移量。
5.1 平移變換原理
設 dx 為水平偏移量,dy為垂直偏移量,(x0, y0)為原影象座標,(x, y)為變換後圖像座標,則平移變換的座標對映為:

這是前向對映,即將原影象的座標對映到變換後的影象上。其逆變換為:
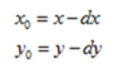
這是向後對映,即將變換後的影象座標對映到原影象上。
在影象的幾何變換中,一般使用向後對映。
5.2 基於OpenCV實現
影象平移:設(x0,y0)是平移後的座標,(x, y)是平移前的座標,dx,dy 為偏移量,則公式如下:
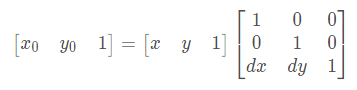
影象平移首先定義平移矩陣M,再呼叫 warpAffine() 函式實現平移,核心函式如下:
M = np.float32([[1, 0, x], [0, 1, y]]) shifted = cv2.warpAffine(image, M, (image.shape[1], image.shape[0]))
完整程式碼如下:
# encoding:utf-8
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 讀取圖片
img = cv2.imread('test.jpg')
image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 影象平移 下、上、右、左平移
M = np.float32([[1, 0, 0], [0, 1, 100]])
img1 = cv2.warpAffine(image, M, (image.shape[1], image.shape[0]))
M = np.float32([[1, 0, 0], [0, 1, -100]])
img2 = cv2.warpAffine(image, M, (image.shape[1], image.shape[0]))
M = np.float32([[1, 0, 100], [0, 1, 0]])
img3 = cv2.warpAffine(image, M, (image.shape[1], image.shape[0]))
M = np.float32([[1, 0, -100], [0, 1, 0]])
img4 = cv2.warpAffine(image, M, (image.shape[1], image.shape[0]))
# 顯示圖形
titles = ['Image1', 'Image2', 'Image3', 'Image4']
images = [img1, img2, img3, img4]
for i in range(4):
plt.subplot(2, 2, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
效果如下:

6,影象仿射變換
影象仿射變換又稱為影象仿射對映,是指在幾何中,一個向量空間進行一次線性變換並接上一個平移,變換為另一個向量空間。通常影象的旋轉加上拉伸就是影象的仿射變換,仿射變換需要一個 M 矩陣實現,但是由於仿射變換比較複雜,很難找到這個 M 矩陣。
OpenCV提供了根據變換前後三個點的對應關係來自動求解 M 的函式——cv2.getAffineTransform( pos1, pos2),其中 pos1和 pos2 表示變換前後的對應位置關係,輸出的結果為仿射矩陣M,接著使用函式 cv2.warpAffine() 實現影象仿射變換,下圖是仿射變換的前後效果圖。
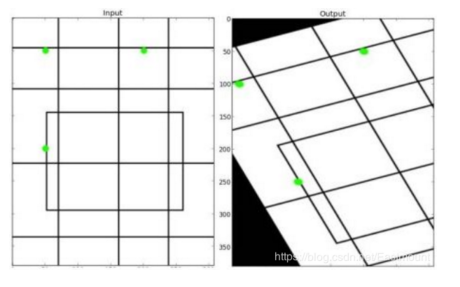
影象仿射變換的函式原型如下:
M = cv2.getAffineTransform(pos1,pos2)
引數含義:
- pos1表示變換前的位置
- pos2表示變換後的位置
cv2.warpAffine(src, M, (cols, rows))
引數含義:
- src表示原始影象
- M表示仿射變換矩陣
- (rows,cols)表示變換後的影象大小,rows表示行數,cols表示列數
實現的程式碼如下:
# _*_ coding:utf-8_*_
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 讀取圖片
img = cv2.imread('liu.jpg')
# 獲取圖片大小
rows, cols = img.shape[:2]
# 設定影象仿射變換矩陣
pos1 = np.float32([[50, 50], [200, 50], [50, 200]])
pos2 = np.float32([[10, 100], [200, 50], [100, 250]])
M = cv2.getAffineTransform(pos1, pos2)
# 影象仿射變換
result = cv2.warpAffine(img, M, (cols, rows))
# 顯示影象
cv2.imshow('origin', img)
cv2.imshow('result', result)
# 等待顯示
cv2.waitKey(0)
cv2.destroyAllWindows()
結果如下:
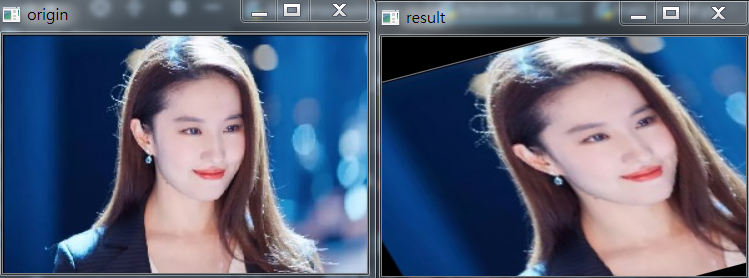
仿射變換允許影象傾斜並且可以在任意兩個方向上發生伸縮,程式碼如下:
def random_warp(img, row, col):
height, width, channels = img.shape
random_margin = 100
x1 = random.randint(-random_margin, random_margin)
y1 = random.randint(-random_margin, random_margin)
x2 = random.randint(width - random_margin - 1, width - 1)
y2 = random.randint(-random_margin, random_margin)
x3 = random.randint(width - random_margin - 1, width - 1)
y3 = random.randint(height - random_margin - 1, height - 1)
x4 = random.randint(-random_margin, random_margin)
y4 = random.randint(height - random_margin - 1, height - 1)
dx1 = random.randint(-random_margin, random_margin)
dy1 = random.randint(-random_margin, random_margin)
dx2 = random.randint(width - random_margin - 1, width - 1)
dy2 = random.randint(-random_margin, random_margin)
dx3 = random.randint(width - random_margin - 1, width - 1)
dy3 = random.randint(height - random_margin - 1, height - 1)
dx4 = random.randint(-random_margin, random_margin)
dy4 = random.randint(height - random_margin - 1, height - 1)
pts1 = np.float32([[x1, y1], [x2, y2], [x3, y3], [x4, y4]])
pts2 = np.float32([[dx1, dy1], [dx2, dy2], [dx3, dy3], [dx4, dy4]])
M_warp = cv2.getPerspectiveTransform(pts1, pts2)
img_warp = cv2.warpPerspective(img, M_warp, (width, height))
return img_warp
img_warp = random_warp(img, img.shape[0], img.shape[1])
cv2.imshow('img_warp', img_warp)
key = cv2.waitKey(0)
if key == 27:
cv2.destroyAllWindows()
7,影象的映象變換
影象的映象變換分為兩種:水平映象和垂直映象。水平映象以影象垂直中線為軸,將影象的畫素進行對換,也就是將影象的左半部和右半部對調。垂直映象則是以影象的水平中線為軸,將影象的上半部分和下半部分對調,效果如下:

7.1 映象變換原理
設影象的寬度為 width,長度為 height。(x, y)為變換後的座標,(x0, y0)為原影象的座標。
1,水平映象變換的向前對映為:

向後對映,即水平映象變換向前變換的逆變換,為:

2,垂直映象變換的前向對映為:
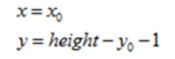
向後對映,即垂直映象變換的前向變換的逆變換,為:

8,影象透視變換
影象透視變換(Perspective Transformation)的本質是將影象投影到一個新的視平面,同理OpenCV通過函式 cv2.getPerspectiveTransform(pos1, pos2)構造矩陣M,其中pos1和pos2分別表示變換前後的四個點對應的位置。得到M後在通過函式 cv2.warpPerspective(src, M, (cols, rows)) 進行透視變換。
影象透視變換的函式原型如下:
M = cv2.getPerspectiveTransform(pos1, pos2)
引數意義:
- pos1表示透視變換前的4個點對應位置
- pos2表示透視變換後的4個點對應位置
cv2.warpPerspective(src,M,(cols,rows))
引數意義:
- src表示原始影象
- M表示透視變換矩陣
- (rows,cols)表示變換後的影象大小,rows表示行數,cols表示列數
程式碼如下:
# _*_ coding:utf-8_*_
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 讀取圖片
img = cv2.imread('liu.jpg')
# 獲取圖片大小
rows, cols = img.shape[:2]
# 設定影象透視變換矩陣
pos1 = np.float32([[114, 82], [287, 156], [8, 322], [216, 333]])
pos2 = np.float32([[0, 0], [188, 0], [0, 262], [188, 262]])
M = cv2.getPerspectiveTransform(pos1, pos2)
# 影象透視變換
result = cv2.warpPerspective(img, M, (cols, rows))
# 顯示影象
cv2.imshow('origin', img)
cv2.imshow('result', result)
# 等待顯示
cv2.waitKey(0)
cv2.destroyAllWindows()
結果如下:

8.1 將旋轉的圖片還原
這裡不理解的可以學習一下我下面這篇部落格:
深入學習OpenCV文件掃描OCR識別及答題卡識別判卷(文件掃描,影象矯正,透視變換,OCR識別)
這裡畫一個簡易圖,簡單來看如下:
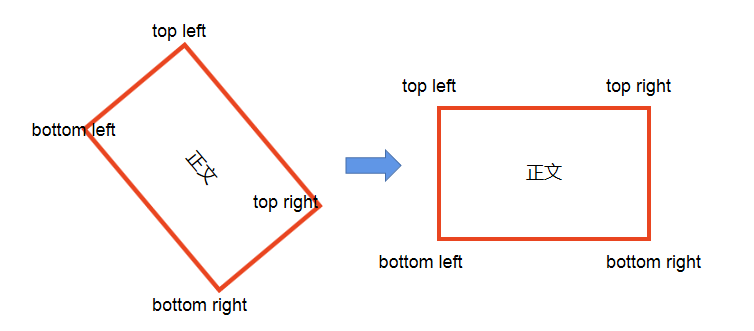
當找到需要旋轉的四個座標點之後,如上圖所示,分別為左上,右上,右下,左下四個點。找到這四個點之後,我們對其進行旋轉還原。部分程式碼如下:
注意:這裡我畫的是矩形,但是實際上可能會出現不規則四邊形。
def order_points(pts):
# 一共四個座標點
rect = np.zeros((4, 2), dtype='float32')
# 按順序找到對應的座標0123 分別是左上,右上,右下,左下
# 計算左上,由下
# numpy.argmax(array, axis) 用於返回一個numpy陣列中最大值的索引值
s = pts.sum(axis=1)
print(s)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 計算右上和左
# np.diff() 沿著指定軸計算第N維的離散差值 後者-前者
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
# 透視變換
def four_point_transform(image, pts):
# 獲取輸入座標點
print('origin:',pts)
rect = order_points(pts)
print('finally:',rect)
(tl, tr, br, bl) = rect
# 計算輸入的w和h的值
widthA = np.sqrt(((br[0] - bl[0])**2) + ((br[1] - bl[1])**2))
widthB = np.sqrt(((tr[0] - tl[0])**2) + ((tr[1] - tl[1])**2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0])**2) + ((tr[1] - br[1])**2))
heightB = np.sqrt(((tl[0] - bl[0])**2) + ((tl[1] - bl[1])**2))
maxHeight = max(int(heightA), int(heightB))
# 變化後對應座標位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]],
dtype='float32')
# 計算變換矩陣
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回變換後的結果
return warped
8.1 基於影象透視變換的影象矯正
也可以直接參考我下面部落格進行實戰:
深入學習OpenCV文件掃描OCR識別及答題卡識別判卷(文件掃描,影象矯正,透視變換,OCR識別)
此例子參考:https://blog.csdn.net/t6_17/article/details/78729097
實現內容:影象矯正,下圖是一張影象中有A4紙,通過影象處理的方法將其矯正。
輸入影象:

處理程式碼:
# _*_ coding:utf-8_*_
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 讀取圖片
img = cv2.imread('paper.jpg')
# 獲取影象大小
rows, cols = img.shape[:2]
# 將原影象高斯模糊
img = cv2.GaussianBlur(img, (3, 3), 0)
# 然後進行灰度化處理
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 邊緣檢測(檢測出影象的邊緣資訊)
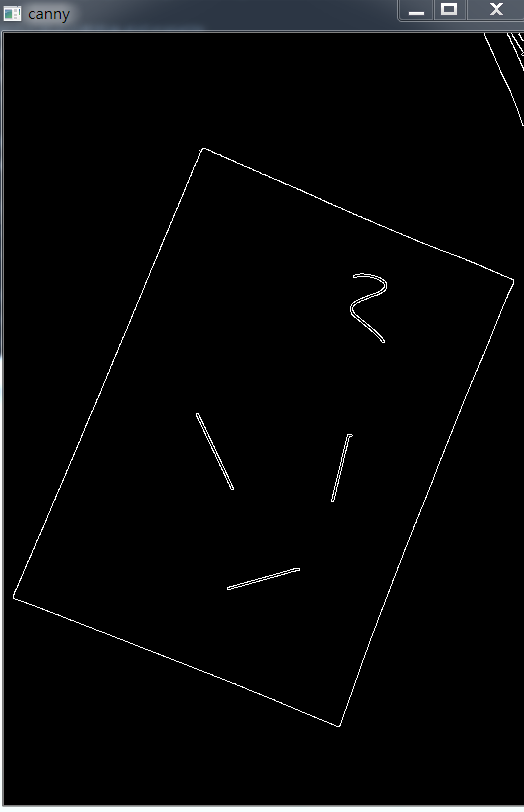
edge = cv2.Canny(gray, 50, 250, apertureSize=3)
# cv2.imshow('canny', edge)
#
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# 通過霍夫變換得到A4紙邊緣
# 可以看到A4紙外還有一些線,可以通過霍夫變換去掉這些先
lines = cv2.HoughLinesP(edge, 1, np.pi/180, 100, minLineLength=90, maxLineGap=10)
# 下面輸出的四個點分別為四個頂點
for x1, y1, x2, y2 in lines[0]:
print((x1, y1), (x2, y2))
for x1, y1, x2, y2 in lines[1]:
print((x1, y1), (x2, y2))
# (9, 564) (140, 254)
# (355, 636) (421, 464)
# 繪製邊緣
for x1, y1, x2, y2 in lines[0]:
cv2.line(gray, (x1, y1), (x2, y2), (0, 255, 0), 2)
# cv2.imshow('hough', gray)
#
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# 根據四個頂點設定影象透視變換矩陣
pos1 = np.float32([[140, 254], [421, 464], [9, 564], [355, 636]])
pos2 = np.float32([[0, 0], [170, 0], [0, 250], [170, 250]])
M = cv2.getPerspectiveTransform(pos1, pos2)
# 影象透視變換
result = cv2.warpPerspective(img, M, (170, 250))
cv2.imshow('result', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
Canny處理的結果:
hough變換後的結果:

我最終得到的結果:

效果不好, 原因大概是在網上拿到的圖片是截圖別人部落格的圖片,而且不是原畫素,邊界不明顯,所以處理之後會存在問題。如果需要看透視變換好的例子,我上面有部落格地址。
我的程式碼:
# _*_ coding:utf-8_*_
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 讀取圖片
img = cv2.imread('paper.jpg')
print(img.shape) # paper1 (511, 297, 3) paper (772, 520, 3)
# 獲取影象大小
rows, cols = img.shape[:2]
# 將原影象高斯模糊
img = cv2.GaussianBlur(img, (3, 3), 0)
# 然後進行灰度化處理
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 邊緣檢測(檢測出影象的邊緣資訊)
# threshold1 表示第一個滯後性閾值 threshold2表示第二個滯後性閾值
# apertureSize 表示應用Sobel運算元的孔徑大小,其預設值為3
edge = cv2.Canny(gray, 50, 200, apertureSize=3)
# cv2.imshow('canny', edge)
#
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# 通過霍夫變換得到A4紙邊緣
# 可以看到A4紙外還有一些線,可以通過霍夫變換去掉這些先
lines = cv2.HoughLinesP(edge, 1, np.pi/180, 30, minLineLength=60, maxLineGap=10)
# 下面輸出的四個點分別為四個頂點
for x1, y1, x2, y2 in lines[0]:
print((x1, y1), (x2, y2))
for x1, y1, x2, y2 in lines[1]:
print((x1, y1), (x2, y2))
# (9, 564) (140, 254)
# (355, 636) (421, 464)x
# 繪製邊緣
for x1, y1, x2, y2 in lines[0]:
cv2.line(gray, (x1, y1), (x2, y2), (0, 0, 255), 2)
# lines = cv2.HoughLines(edge, 1, np.pi/180, 150)
# # 提取為二維
# lines1 = lines[:, 0, :]
# for rho, theta in lines1[:]:
# a, b = np.cos(theta), np.sin(theta)
# x0, y0 = a*rho, b*rho
# x1, y1 = int(x0 + 1000*(-b)), int(y0 + 1000*(a))
# x2, y2 = int(x0 - 1000*(-b)), int(y0 - 1000*(a))
# print(x1, x2, y1, y2)
# cv2.line(gray, (x1, y1), (x2, y2), (0, 0, 255), 2)
# cv2.imshow('hough', gray)
#
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# 根據四個頂點設定影象透視變換矩陣
pos1 = np.float32([[168, 187], [509, 246], [9, 563], [399, 519]])
pos2 = np.float32([[0, 0], [170, 0], [0, 220], [170, 220]])
M = cv2.getPerspectiveTransform(pos1, pos2)
# 影象透視變換
result = cv2.warpPerspective(img, M, (170, 250))
cv2.imshow('result', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
9,影象幾何變換總結
最後補充影象幾何變換所有程式碼,完整程式碼如下:
# encoding:utf-8
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 讀取圖片
img = cv2.imread('liu.jpg')
image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 影象平移矩陣
M = np.float32([[1, 0, 80], [0, 1, 30]])
rows, cols = image.shape[:2]
img1 = cv2.warpAffine(image, M, (cols, rows))
# 影象縮小
img2 = cv2.resize(image, (200, 100))
# 影象放大
img3 = cv2.resize(image, None, fx=1.1, fy=1.1)
# 繞影象的中心旋轉
# 源影象的高、寬 以及通道數
rows, cols, channel = image.shape
# 函式引數:旋轉中心 旋轉度數 scale
M = cv2.getRotationMatrix2D((cols / 2, rows / 2), 30, 1)
# 函式引數:原始影象 旋轉引數 元素影象寬高
img4 = cv2.warpAffine(image, M, (cols, rows))
# 影象翻轉
img5 = cv2.flip(image, 0) # 引數=0以X軸為對稱軸翻轉
img6 = cv2.flip(image, 1) # 引數>0以Y軸為對稱軸翻轉
# 影象的仿射
pts1 = np.float32([[50, 50], [200, 50], [50, 200]])
pts2 = np.float32([[10, 100], [200, 50], [100, 250]])
M = cv2.getAffineTransform(pts1, pts2)
img7 = cv2.warpAffine(image, M, (rows, cols))
# 影象的透射
pts1 = np.float32([[56, 65], [238, 52], [28, 237], [239, 240]])
pts2 = np.float32([[0, 0], [200, 0], [0, 200], [200, 200]])
M = cv2.getPerspectiveTransform(pts1, pts2)
img8 = cv2.warpPerspective(image, M, (200, 200))
# 迴圈顯示圖形
titles = ['source', 'shift', 'reduction', 'enlarge', 'rotation', 'flipX', 'flipY', 'affine', 'transmission']
images = [image, img1, img2, img3, img4, img5, img6, img7, img8]
for i in range(9):
plt.subplot(3, 3, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
結果如下:

參考文獻:https://blog.csdn.net/Eastmount/article/details/82454335
https://blog.csdn.net/Eastmount/article/details/88679772
https://www.cnblogs.com/wangguchangqing/p/4039095.html
https://www.cnblogs.com/wangguchangqing/p/4045150.html
二值化參考文獻: https://blog.csdn.net/whl970831/article/details/99706730
https://blog.csdn.net/t6_17/article/details/7872