
如何理解矩陣特徵值?
預設排序
![]()
看圖學數學,公眾號:matongxue314
2,876 人贊同了該回答
(下面的回答只涉及實數範圍)。
關於特徵值、特徵向量可以講的確實很多,我這裡希望可以給大家建立一個直觀的印象。
先給一個簡短的回答,如果把矩陣看作是運動,對於運動而言,最重要的當然就是運動的速度和方向,那麼(我後面會說明一下限制條件):
- 特徵值就是運動的速度
- 特徵向量就是運動的方向
既然運動最重要的兩方面都被描述了,特徵值、特徵向量自然可以稱為運動(即矩陣)的特徵。
注意,由於矩陣是數學概念,非常抽象,所以上面所謂的運動、運動的速度、運動的方向都是廣義的,在現實不同的應用中有不同的指代。
下面是詳細的回答,我會先從幾何上簡單講解下特徵值、特徵向量的定義指的是什麼,然後再來解釋為什麼特徵值、特徵向量會是運動的速度和方向。
1 幾何意義
說明下,因為線性變換總是在各種基之間變來變去,所以我下面畫圖都會把作圖所用的基和原點給畫出來。
在 下面有個
:
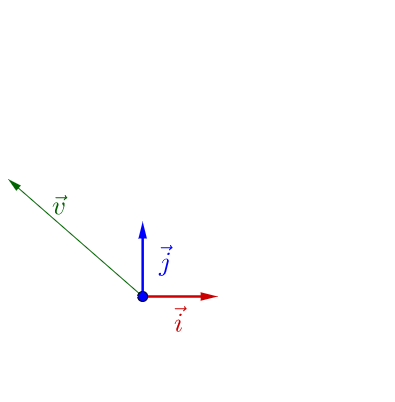
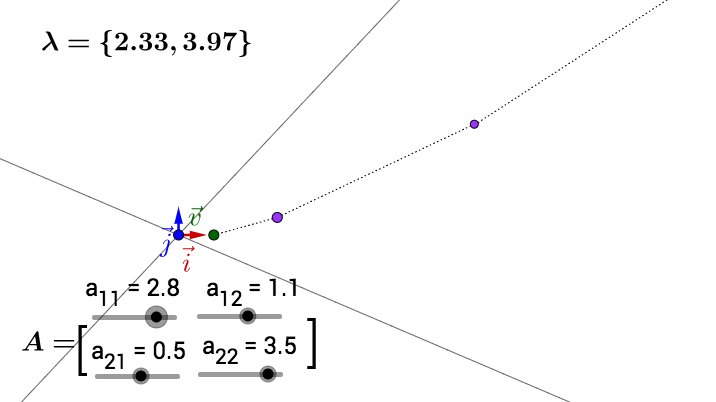
隨便左乘一個矩陣,影象看上去沒有什麼特殊的:
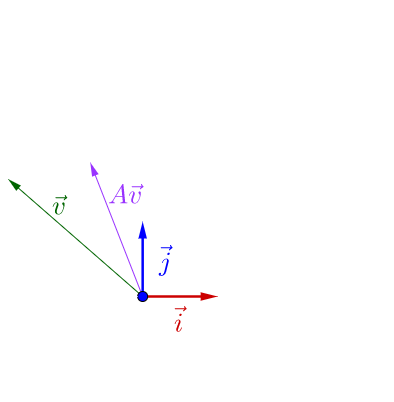
我調整下 的方向,影象看上去有點特殊了:
可以觀察到,調整後的 和
在同一根直線上,只是
的長度相對
的長度變長了。
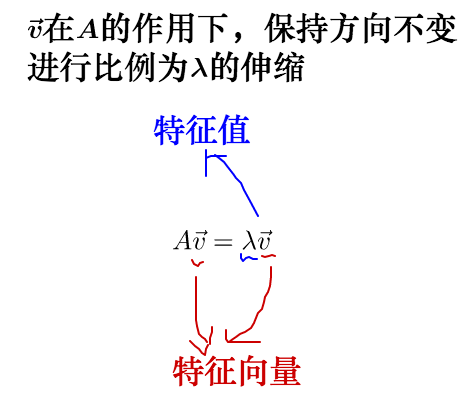
此時,我們就稱 是
的特徵向量,而
的長度是
的長度的
倍,
就是特徵值。
從而,特徵值與特徵向量的定義式就是這樣的:
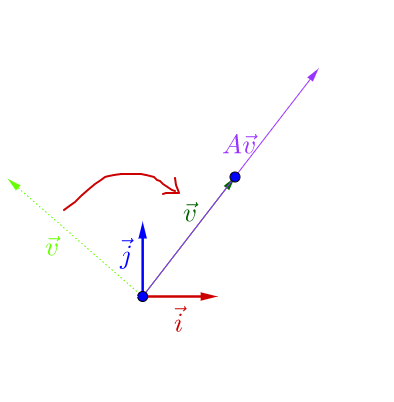
其實之前的 不止一個特徵向量,還有一個特徵向量:
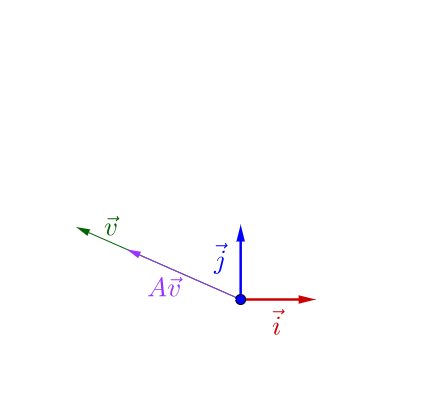
容易從 相對於
是變長了還是縮短看出,這兩個特徵向量對應的特徵
值,一個大於1,一個小於1。
從特徵向量和特徵值的定義式還可以看出,特徵向量所在直線上的向量都是特徵向量:
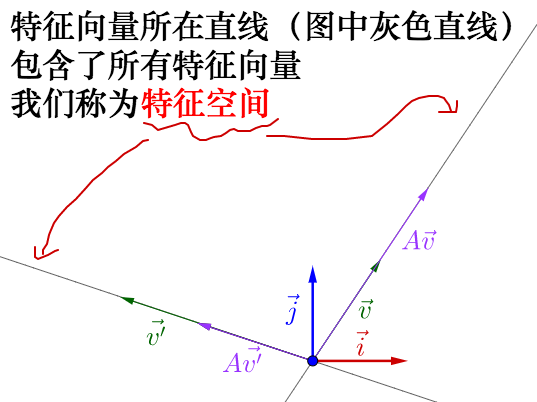
你可以自己動手試試,可以改變 的位置,以及矩陣
的值(特徵空間會隨著矩陣改變而改變):
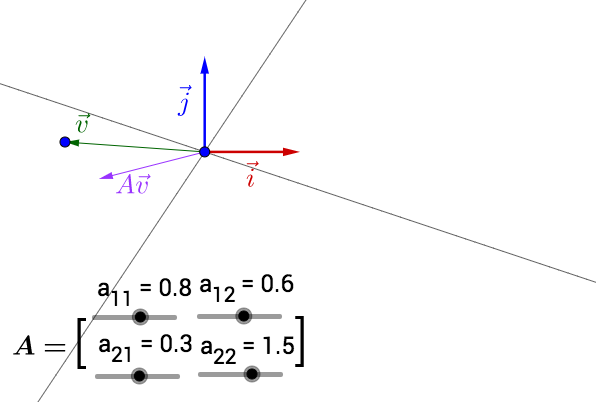
其中有些值構成的矩陣沒有畫出特徵空間,可能是因為它的特徵值、特徵向量是複數,也可能是不存在。
下面就要說下,特徵值、特徵向量與運動的關係
2 運動的速度與方向
2.1 從調色談起
我有一管不知道顏色的顏料,而且這管顏料有點特殊,我不能直接擠出來看顏色,只能通過調色來觀察:

為了分辨出它是什麼顏色(記得它只能通過調色來辨別):
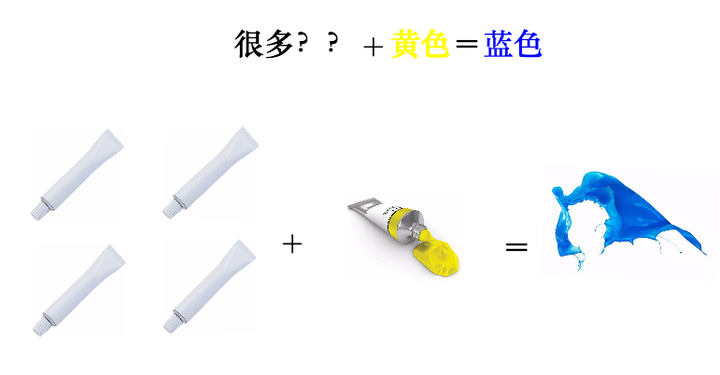
因為反覆混合之後,這管顏料的特徵就凸顯了出來,所以我們判斷,這管顏料應該是藍色。
說這個幹什麼?矩陣也有類似的情況。
2.2 矩陣的混合
一般來說,矩陣我們可以看作某種運動,而二維向量可以看作平面上的一個點(或者說一個箭頭)。對於點我們是可以觀察的,但是運動我們是不能直接觀察的。
就好像,跑步這個動作,我們不附加到具體的某個事物上是觀察不到的,我們只能觀察到:人跑步、豬跑步、老虎跑步、......,然後從中總結出跑步的特點。
就好像之前舉的不能直接觀察的顏料一樣,要觀察矩陣所代表的運動,需要把它附加到向量上才觀察的出來:
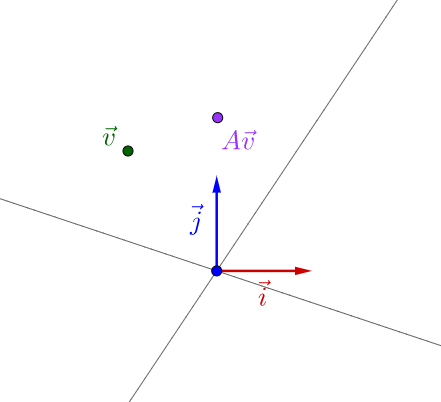
似乎還看不出什麼。但是如果我反覆運用矩陣乘法的話:
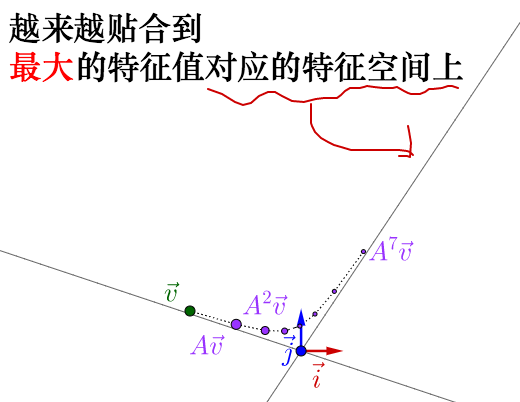
就像之前顏料混合一樣,反覆運用矩陣乘法,矩陣所代表的運動的最明顯的特徵,即速度最大的方向,就由最大特徵值對應的特徵向量展現了出來。
至於別的特徵值對應的是什麼速度,我後面會解釋,這裡先跳過。
可以自己動手試試,我把 值也標註出來了,可以關注下最大
值對於運動的影響:
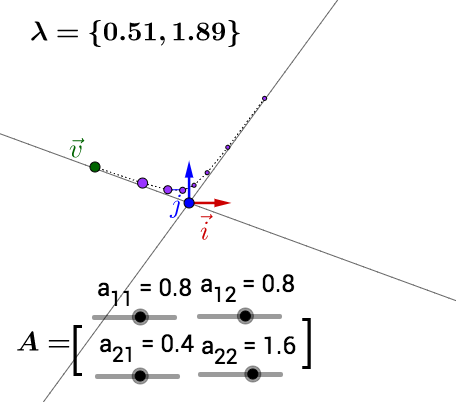
順便說下,對於複數的特徵值、特徵向量,在上面就沒有畫出特徵空間,但可以觀察到反覆運用矩陣乘法的結果是圍繞著原點在旋轉。關於複數特徵值和特徵向量這裡就不展開來說了。
2.3 燒一壺斐波那契的水
上面說的運動太抽象了,我來舉一個具體點的例子:燒水。
比如說我想燒一壺水,水的溫度按照斐波那契數列升高,即下一秒的溫度 與當前溫度
以及上一秒的溫度
的關係為:
要繼續計算下去,我只需要 以及
就可以繼續算下去。因此我可以寫成下面的式子:
因此燒水這個運動我們可以抽象為矩陣 ,反覆進行這個運動就可以燒開這壺水,根據斐波那契數列,讓我們從
點開始(感興趣的話,可以通過之前的互動調整下引數,可以得到下面的結果):

就可以看出,這壺水的溫度會沿著的特徵值最大的特徵向量方向飛快增長,我估計要不了多久,在理想的情況下,溫度就會突破百萬度、千萬度、億萬度,然後地球說不定就爆炸了。我們就說這個矩陣不穩定。
所以說,不要燒斐波那契的水。
實際上歷史也是這樣,尤拉在研究剛體的運動時發現,有一個方向最為重要,後來拉格朗日發現,哦,原來就是特徵向量的方向。
我們知道特徵值、特徵向量有什麼特點之後,下一步就想知道,為什麼會這樣?
3 特徵值分解
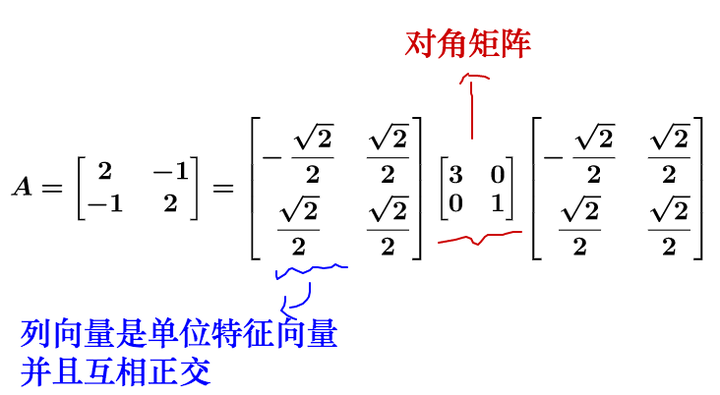
我們知道,對於矩陣可以對角化的話,可以通過相似矩陣進行下面這樣的特徵值分解:
其中為對角陣,
的列向量是單位化的特徵向量。
說的有點抽象,我們拿個具體的例子來講:
對於方陣而言,矩陣不會進行維度的升降,所以矩陣代表的運動實際上只有兩種:
- 旋轉
- 拉伸
最後的運動結果就是這兩種的合成。
我們再回頭看下剛才的特徵值分解,實際上把運動給分解開了:
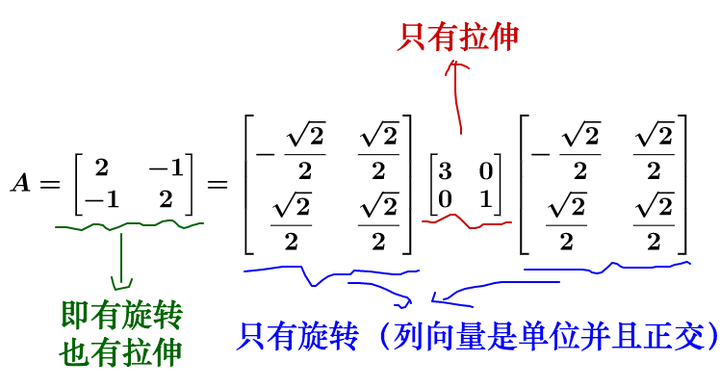
我們來看看在幾何上的表現是什麼,因此相似矩陣的講解涉及到基的變換,所以大家注意觀察基:
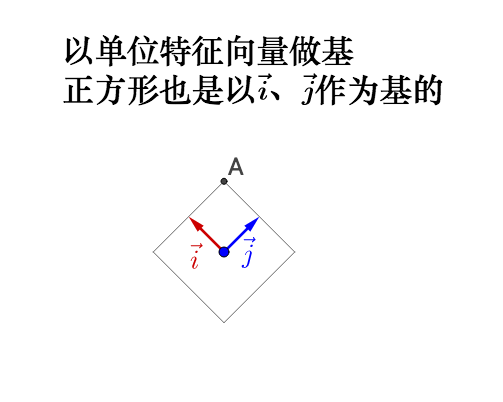
左乘 :
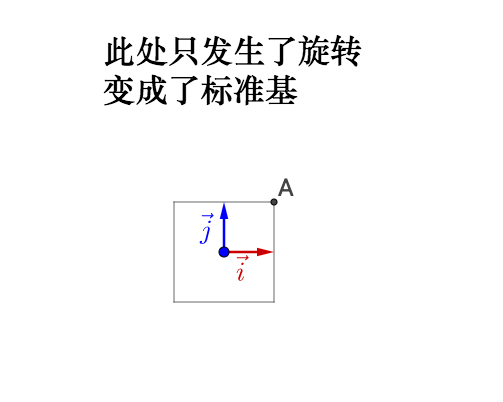
如果旋轉前的基不正交,旋轉之後變為了標準基,那麼實際會產生伸縮,所以之前說的正交很重要。
繼續左乘對角矩陣 :
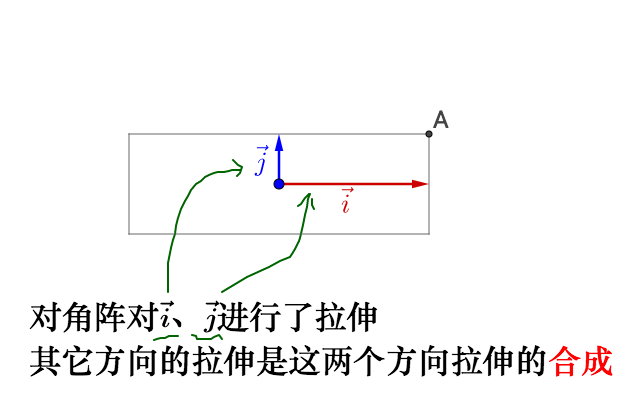
相當於,之前的旋轉是指明瞭拉伸的方向,所以我們理解了:
- 特徵值就是拉伸的大小
- 特徵向量指明瞭拉伸的方向
回到我們之前說的運動上去,特徵值就是運動的速度,特徵向量就是運動的方向,而其餘方向的運動就由特徵向量方向的運動合成。所以最大的特徵值對應的特徵向量指明瞭運動速度的最大方向。
但是,重申一下,上面的推論有一個重要的條件,特徵向量正交,這樣變換後才能保證變換最大的方向在基方向。如果特徵向量不正交就有可能不是變化最大的方向,比如:
所以我們在實際應用中,都要去找正交基。但是特徵向量很可能不是正交的,那麼我們就需要奇異值分解了,這裡就不展開了。
大家可以再回頭去操作一下之前的動圖,看看不正交的情況下有什麼不一樣。
左乘 :
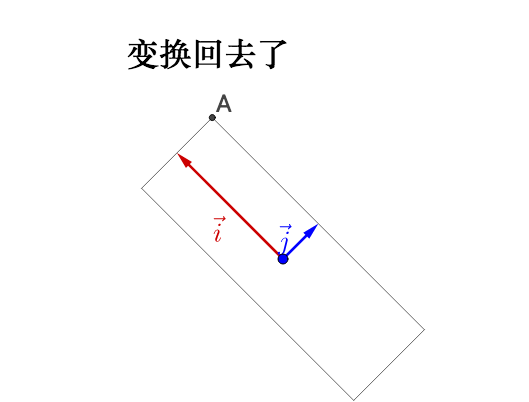
說明下,如果大家把這個文章和之前提到的我寫的“相似矩陣”的文章參照來看的話,“相似矩陣”那篇文章裡面我把影象的座標系換了,所以看著影象沒有變換(就好像直角座標系到極座標系下,影象是不會變換的)。而這裡我把影象的座標系給旋轉、拉伸了,所以看著影象變換了(就好像換元,會導致影象變換)。這其實是看待矩陣乘法的兩種視角,是等價的,但是顯示到影象上就有所不同。
4 特徵值、特徵向量的應用
4.1 控制系統
之前的燒水系統是不穩定的。
的,系統最終會趨於穩定:
4.2 圖片壓縮
比如說,有下面這麼一副的圖片(方陣才有特徵值,所以找了張正方形的圖):

這個圖片可以放到一個矩陣裡面去,就是把每個畫素的顏色值填入到一個的
矩陣中。
根據之前描述的有:
其中, 是對角陣,對角線上是從大到小排列的特徵值。
我們在中只保留前面50個的特徵值(也就是最大的50個,其實也只佔了所有特徵值的百分之十),其它的都填0,重新計算矩陣後,恢復為下面這樣的影象:

效果還可以,其實一兩百個特徵值之和可能就佔了所有特徵值和的百分之九十了,其他的特徵值都可以丟棄了。
贊同 2.9K168 條評論
分享
收藏感謝收起
![]()
電氣工程,科幻迷
108 人贊同了該回答
前面的回答比較專業化,而且好像沒說特徵值是虛數的情況,並不是只有特徵向量的伸縮。作為工科線代水平,我說下自己的理解。矩陣特徵值是對特徵向量進行伸縮和旋轉程度的度量,實數是隻進行伸縮,虛數是隻進行旋轉,複數就是有伸縮有旋轉。其實最重要的是特徵向量,從它的定義可以看出來,特徵向量是在矩陣變換下只進行“規則”變換的向量,這個“規則”就是特徵值。推薦教材linear algebra and its application
贊同 10818 條評論
分享
收藏感謝
![]()
低頭玩手機相當於在脖子上掛兩個大鐵球。
1,332 人贊同了該回答
補充:答主現在用到的多數是對稱矩陣或酉矩陣的情況,有思維定勢了,寫了半天才發現主要講的是對稱矩陣,這答案就當科普用了。特徵值在很多領域應該都有自己的用途,它的物理意義到了本科高年級或者研究生階段涉及到具體問題的時候就容易理解了,剛學線性代數的話,確實抽象。
——————————————————以下為正文——————————————————
從線性空間的角度看,在一個定義了內積的線性空間裡,對一個N階對稱方陣進行特徵分解,就是產生了該空間的N個標準正交基,然後把矩陣投影到這N個基上。N個特徵向量就是N個標準正交基,而特徵值的模則代表矩陣在每個基上的投影長度。 特徵值越大,說明矩陣在對應的特徵向量上的方差越大,功率越大,資訊量越多。
應用到最優化中,意思就是對於R的二次型,自變數在這個方向上變化的時候,對函式值的影響最大,也就是該方向上的方向導數最大。 應用到資料探勘中,意思就是最大特徵值對應的特徵向量方向上包含最多的資訊量,如果某幾個特徵值很小,說明這幾個方向資訊量很小,可以用來降維,也就是刪除小特徵值對應方向的資料,只保留大特徵值方向對應的資料,這樣做以後資料量減小,但有用資訊量變化不大。
——————————————————舉兩個栗子——————————————————
應用1 二次型最優化問題
二次型,其中R是已知的二階矩陣,R=[1,0.5;0.5,1],x是二維列向量,x=[x1;x2],求y的最小值。
求解很簡單,講一下這個問題與特徵值的關係。 對R特徵分解,特徵向量是[-0.7071;0.7071]和[0.7071;0.7071],對應的特徵值分別是0.5和1.5。 然後把y的等高線圖畫一下
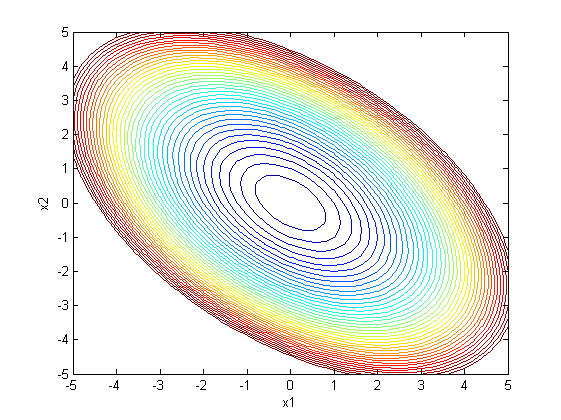
從圖中看,函式值變化最快的方向,也就是曲面最陡峭的方向,歸一化以後是[0.7071;0.7071],嗯哼,這恰好是矩陣R的一個特徵值,而且它對應的特徵向量是最大的。因為這個問題是二階的,只有兩個特徵向量,所以另一個特徵向量方向就是曲面最平滑的方向。這一點在分析最優化演算法收斂效能的時候需要用到。 二階問題比較直觀,當R階數升高時,也是一樣的道理。
應用2 資料降維
原資料有13維,但這之中含有冗餘,減少資料量最直接的方法就是降維。
做法:把資料集賦給一個178行13列的矩陣R,減掉均值並歸一化,它的協方差矩陣,C是13行13列的矩陣,對C進行特徵分解,對角化
,其中U是特徵向量組成的矩陣,D是特徵之組成的對角矩陣,並按由大到小排列。然後,另
,就實現了資料集在特徵向量這組正交基上的投影。嗯,重點來了,R’中的資料列是按照對應特徵值的大小排列的,後面的列對應小特徵值,去掉以後對整個資料集的影響比較小。比如,現在我們直接去掉後面的7列,只保留前6列,就完成了降維。這個降維方法叫PCA(Principal Component Analysis)。
下面看結果:
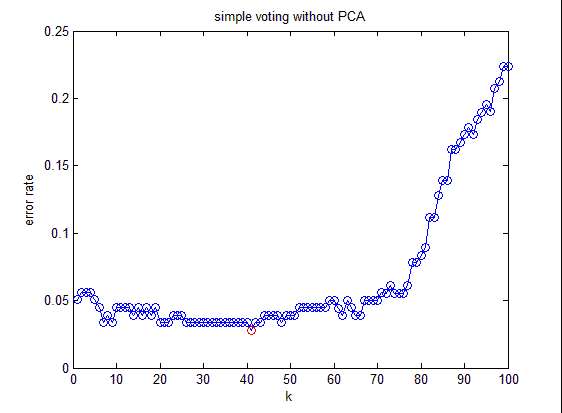
這是不降維時候的分類錯誤率。
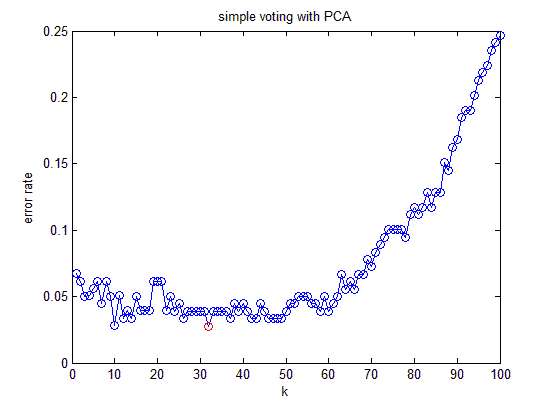
這是降維以後的分類錯誤率。
結論:降維以後分類錯誤率與不降維的方法相差無幾,但需要處理的資料量減小了一半(不降維需要處理13維,降維後只需要處理6維)。
贊同 1.3K113 條評論
分享
收藏感謝收起
![]()
神奇的矩陣
600 人贊同了該回答
想要理解特徵值,首先要理解矩陣相似。什麼是矩陣相似呢?從定義角度就是:存在可逆矩陣P滿足B=則我們說A和B是相似的。讓我們來回顧一下之前得出的重要結論:對於同一個線性空間,可以用兩組不同的基
和基
來描述,他們之間的過渡關係是這樣的:
,而對應座標之間的過渡關係是這樣的:
。其中P是可逆矩陣,可逆的意義是我們能變換過去也要能變換回來,這一點很重要。
我們知道,對於一個線性變換,只要你選定一組基,那麼就可以用一個矩陣T1來描述這個線性變換。換一組基,就得到另一個不同的矩陣T2(之所以會不同,是因為選定了不同的基,也就是選定了不同的座標系)。所有這些矩陣都是這同一個線性變換的描述,但又都不是線性變換本身。具體來說,有一個線性變換,我們選擇基
來描述,對應矩陣是
;同樣的道理,我們選擇基
來描述
,,對應矩陣是
;我們知道基
和基
是有聯絡的,那麼他們之間的變換
和
有沒有聯絡呢?
當然有, 和
就是相似的關係,具體的請看下圖:
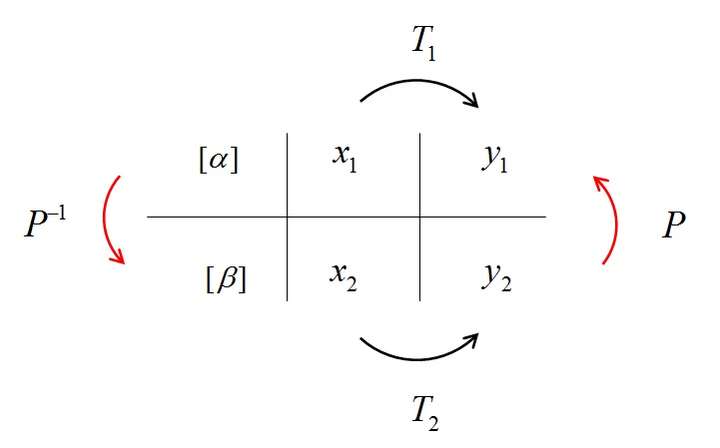
沒錯,所謂相似矩陣,就是同一個線性變換的不同基的描述矩陣。這就是相似變換的幾何意義。
這個發現太重要了。原來一族相似矩陣都是同一個線性變換的描述啊!難怪這麼重要!工科研究生課程中有矩陣論、矩陣分析等課程,其中講了各種各樣的相似變換,比如什麼相似標準型,對角化之類的內容,都要求變換以後得到的那個矩陣與先前的那個矩陣式相似的,為什麼這麼要求?因為只有這樣要求,才能保證變換前後的兩個矩陣是描述同一個線性變換的。就像訊號處理(積分變換)中將訊號(函式)進行拉氏變換,在複數域處理完了之後又進行拉式反變換,回到實數域一樣。訊號處理中是主要是為了將複雜的卷積運算變成乘法運算。其實這樣的變換還有好多,有興趣可以看積分變換的教材。
為什麼這樣做呢?矩陣的相似變換可以把一個比較醜的矩陣變成一個比較美的矩陣,而保證這兩個矩陣都是描述了同一個線性變換。至於什麼樣的矩陣是“美”的,什麼樣的是“醜”的,我們說對角陣是美的。線上性代數中,我們會看到,如果把複雜的矩陣變換成對角矩陣,作用完了之後再變換回來,這種轉換很有用處,比如求解矩陣的n次冪!而學了矩陣論之後你會發現,矩陣的n次冪是工程中非常常見的運算。這裡順便說一句,將矩陣對角化在控制工程和機械振動領域具有將複雜方程解耦的妙用!總而言之,相似變換是為了簡化計算!
從另一個角度理解矩陣就是:矩陣主對角線上的元素表示自身和自身的關係,其他位置的元素aij表示i位置和j位置元素之間的相互關係。那麼好,特徵值問題其實就是選取了一組很好的基,就把矩陣 i位置和j位置元素之間的相互關係消除了。而且因為是相似變換,並沒有改變矩陣本身的特性。因此矩陣對角化才如此的重要!
特徵向量的引入是為了選取一組很好的基。空間中因為有了矩陣,才有了座標的優劣。對角化的過程,實質上就是找特徵向量的過程。如果一個矩陣在複數域不能對角化,我們還有辦法把它化成比較優美的形式——Jordan標準型。高等代數理論已經證明:一個方陣在複數域一定可以化成Jordan標準型。這一點有興趣的同學可以看一下高等代數後或者矩陣論。
經過上面的分析相信你已經可以得出如下結論了:座標有優劣,於是我們選取特徵向量作為基底,那麼一個線性變換最核心的部分就被揭露出來——當矩陣表示線性變換時,特徵值就是變換的本質!特徵值的幾何意義前面的答主已經用很多圖解釋過了,接下來我們分析一下特徵值的物理意義:特徵值英文名eigen value。“特徵”一詞譯自德語的eigen,由希爾伯特在1904年首先在這個意義下使用(赫爾曼·馮·亥姆霍茲在更早的時候也在類似意義下使用過這一概念)。eigen一詞可翻譯為“自身的”,“特定於...的”,“有特徵的”或者“個體的”—這強調了特徵值對於定義特定的變換上是很重要的。它還有好多名字,比如譜,本徵值。為什麼會有這麼多名字呢?
原因就在於他們應用的領域不同,中國人為了區分,給特不同的名字。你看英文文獻就會發現,他們的名字都是同一個。當然,特徵值的思想不僅僅侷限於線性代數,它還延伸到其他領域。在數學物理方程的研究領域,我們就把特徵值稱為本徵值。如在求解薛定諤波動方程時,在波函式滿足單值、有限、連續性和歸一化條件下,勢場中運動粒子的總能量(正)所必須取的特定值,這些值就是正的本徵值。
前面我們討論特徵值問題面對的都是有限維度的特徵向量,下面我們來看看特徵值對應的特徵向量都是無限維函式的例子。這時候的特徵向量我們稱為特徵函式,或者本證函式。這還要從你熟悉的微分方程說起。方程本質是一種約束,微分方程就是在世界上各種各樣的函式中,約束出一類函式。對於一階微分方程
我們發現如果我將變數y用括號[]包圍起來,微分運算的結構和線性代數中特徵值特徵向量的結構,即和
竟是如此相似。這就是一個求解特徵向量的問題啊!只不過“特徵向量”變成函式!我們知道只有
滿足這個式子。這裡出現了神奇的數e,一杯開水放在室內,它溫度的下降是指數形式的;聽說過放射性元素的原子核發生衰變麼?隨著放射的不斷進行,放射強度將按指數曲線下降;化學反應的程序也可以用指數函式描述……類似的現象還有好多。
為什麼選擇指數函式而不選擇其他函式,因為指數函式是特徵函式。為什麼指數函式是特徵?我們從線性代數的特徵向量的角度來解釋。這已經很明顯了就是“特徵向量”。於是,很自然的將線性代數的理論應用到線性微分方程中。那麼指數函式就是微分方程(實際物理系統)的特徵向量。用特徵向量作為基表示的矩陣最為簡潔。就像你把一個方陣經過相似對角化變換,耦合的矩陣就變成不耦合的對角陣一樣。在機械振動裡面所說的模態空間也是同樣的道理。如果你恰巧學過振動分析一類的課程,也可以來和我交流。
同理,用特徵函式解的方程也是最簡潔的,不信你用級數的方法解方程,你會發現方程的解有無窮多項。解一些其他方程的時候(比如貝塞爾方程)我們目前沒有找到特徵函式,於是退而求其次才選擇級數求解,至少級數具有完備性。實數的特徵值代表能量的耗散或者擴散,比如空間中熱量的傳導、化學反應的擴散、放射性元素的衰變等。虛數的特徵值(對應三角函式)代表能量的無損耗交換,比如空間中的電磁波傳遞、振動訊號的動能勢能等。複數的特徵值代表既有交換又有耗散的過程,實際過程一般都是這樣的。復特徵值在電路領域以及振動領域將發揮重要的作用,可以說,沒有複數,就沒有現代的電氣化時代!
對於二階微分方程方程,它的解都是指數形式或者復指數形式。可以通過尤拉公式將其寫成三角函式的形式。復特徵值體現最多的地方是在二階系統,別小看這個方程,整本自動控制原理都在講它,整個振動分析課程也在講它、還有好多課程的基礎都是以這個微分方程為基礎,這裡我就不詳細說了,有興趣可以學習先關課程。說了這麼多隻是想向你傳達一個思想,就是復指數函式式系統的特徵向量!
如果將二階微分方程轉化成狀態空間的形式(具體轉化方法見現代控制理論,很簡單的)
。則一個二階線性微分方程就變成一個微分方程組的形式這時就出現了矩陣A,矩陣可以用來描述一個系統:如果是振動問題,矩陣A的特徵值是虛數,對應系統的固有頻率,也就是我們常說的,特徵值代表振動的譜。如果含有耗散過程,特徵值是負實數,對應指數衰減;特徵值是正實數,對應指數發散過程,這時是不穩定的,說明系統極容易崩潰,如何抑制這種發散就是控制科學研究的內容。
提到振動的譜,突然想到了這個經典的例子:美國數學家斯特讓(G..Strang)在其經典教材《線性代數及其應用》中這樣介紹了特徵值作為頻率的物理意義,他說:"大概最簡單的例子(我從不相信其真實性,雖然據說1831年有一橋樑毀於此因)是一對士兵通過橋樑的例子。傳統上,他們要停止齊步前進而要散步通過。這個理由是因為他們可能以等於橋的特徵值之一的頻率齊步行進,從而將發生共振。就像孩子的鞦韆那樣,你一旦注意到一個鞦韆的頻率,和此頻率相配,你就使頻率蕩得更高。一個工程師總是試圖使他的橋樑或他的火箭的自然頻率遠離風的頻率或液體燃料的頻率;而在另一種極端情況,一個證券經紀人則盡畢生精力於努力到達市場的自然頻率線。特徵值是幾乎任何一個動力系統的最重要的特徵。"
對於一個線性系統,總可以把高階的方程轉化成一個方程組描述,這被稱為狀態空間描述。因此,他們之間是等價的。特徵值還有好多用處,原因不在特徵值本身,而在於特徵值問題和你的物理現象有著某種一致的對應關係。學習特徵值問題告訴你一種解決問題的方法:尋找事物的特徵,然後特徵分解。
最後宣告一下, 本文是在整理孟巖老師的《理解矩陣》和任廣千、胡翠芳老師的《線性代數的幾何意義》基礎上形成的,只是出於一種對數學的愛好!有興趣的讀者建議閱讀原文。也歡迎下載《神奇的矩陣》和《神奇的矩陣第二季》瞭解更多有關線性代數和矩陣的知識。
贊同 600108 條評論
分享
收藏感謝收起
![]()
程式設計師
69 人贊同了該回答
作為一個線性代數考60+的學渣,我是這麼直觀地理解的:
把式子中的
看作一個線性變換,那麼這個定義式就表示對於 向量
而言,經過
變換之後該向量的方向沒有變化(可能會反向),而只是長度變化了(乘以
)。
也就是對於變換來說,存在一些“不變”的量(比如特徵向量
的方向),我想,“特徵”的含義就是“不變”。
而特徵值,如你所見,就是變換
在特徵方向上的伸展係數吧(亂諏了個名詞 :P)。
贊同 695 條評論
分享
收藏感謝
![]()
101 人贊同了該回答
定義很抽象我也一直搞不懂,但是最近開始在影象處理方面具體應用的時候就清晰很多了,用學渣的語言溝通一下吧我們。
拋開學術研究不談,其實根本不會,特徵值eigenvalue和特徵向量eigenvector的一大應用是用於大量資料的降維
比如拿淘寶舉個例子,每個淘寶店鋪有N個統計資料:商品型別,日銷量周銷量月銷量、好評率中評差評率……全淘寶有M家店鋪,那麼伺服器需要記錄的資料就是M*N的矩陣;
這是一個很大的資料,實際上我們可以通過求這個矩陣的特徵向量和對應的特徵值來重新表示這個M*N的矩陣: 我們可以用周銷量來誤差不大的表示日銷量和月銷量(除以七和乘以四),這個時候周銷量就可以當作一個特徵向量,它能夠表示每個店鋪銷量這個空間方向的主要能量(也就是資料),這樣我們就簡略的把一個35維的向量簡化成四維的(30個日銷量加4個周銷量加1個月銷量); 同理我們也可以把好評率中評率差評率用一個好評率來表示(剩餘的百分比預設為差評率),這樣的降維大致上也能反映一個店鋪的誠信度; 這樣通過不斷的降維我們可以提取到某系列資料最主要的幾個特徵向量(對應特徵值最大的),這些向量反映了這個矩陣空間最主要的能量分佈,所以我們可以用這幾個特徵向量來表示整個空間,實現空間的降維。
這個方法叫做Principle Components Analysis,有興趣的同學可以wiki一下。
學渣飄過了
贊同 10119 條評論
分享
收藏感謝
![]()
Make real impact.
收錄於編輯推薦 · 230 人贊同了該回答
各位知友在點贊同之前請看一下評論區。這個例子有待討論。
----------- 我舉一個直觀一點的例子吧...我也喜歡數學的直觀之美。
我們知道,一張影象的畫素(如:320 x 320)到了計算機裡面事實上就是320x320的矩陣,每一個元素都代表這個畫素點的顏色..
如果我們把基於特徵值的應用,如PCA、向量奇異值分解SVD這種東西放到影象處理上,大概就可以提供一個看得到的、直觀的感受。關於SVD的文章可以參考LeftNotEasy的文章:機器學習中的數學(5)-強大的矩陣奇異值分解(SVD)及其應用
簡單的說,SVD的效果就是..用一個規模更小的矩陣去近似原矩陣...
這裡A就是代表影象的原矩陣..其中的
尤其值得關注,它是由A的特徵值從大到小放到對角線上的..也就是說,我們可以選擇其中的某些具有“代表性”的特徵值去近似原矩陣!
左邊的是原始圖片

當我把特徵值的數量減少幾個的時候...後面的影象變“模糊”了..

同樣地...

關鍵的地方來了!如果我們只看到這裡的模糊..而沒有看到計算機(或者說數學)對於人臉的描述,那就太可惜了...我們看到,不論如何模糊,臉部的關鍵部位(我們人類認為的關鍵部位)——五官並沒有變化太多...這能否說:數學揭示了世界的奧祕?
贊同 23037 條評論
分享
收藏感謝收起
![]()
資訊保安愛好者,結果導向的博士狗
28 人贊同了該回答
不過真的是上面那個視訊讓我對特徵值和特徵向量真正有一個直觀的認識. youtube上兩萬多收看, 兩百多點up, 沒有點down的.
贊同 285 條評論
分享
收藏感謝
![]()
優化, 學習
6 人贊同了該回答

references:(1) 式 <matrix analysis> horn
贊同 61 條評論
分享
收藏感謝
![]()
Talk is cheap, show me the formula
61 人贊同了該回答
看了大部分的回答,基本都沒有回答出為什麼要求特徵值。
特徵值和特徵向量是為了研究向量在經過線性變換後的方向不變性而提出的,一個空間裡的元素通過線性變換到另一個相同維數的空間,那麼會有某些向量的方向在變換前後不會改變,方向不變但是這些向量的範數可能會改變,我這裡說的都是實數空間的向量。
定義,定義
為原始空間中的向量,
為變換後空間的向量,簡單起見令
為
階方陣且特徵值
互不相同,對應的特徵向量
線性無關。那麼原始空間中的任何一個向量都可以由A的特徵向量表示,既
那麼在變換到另一個空間時
,這就求完了!
好,下面再說更深層次的含義。
在不同的領域特徵值的大小與特徵向量的方向所表示的含義也不同,但是從數學定義上來看,每一個原始空間中的向量都要變換到新空間中,所以他們之間的差異也會隨之變化,但是為了保持相對位置,每個方向變換的幅度要隨著向量的分散程度進行調整。
你們體會一下拖拽圖片使之放大縮小的感覺。
如果A為樣本的協方差矩陣,特徵值的大小就反映了變換後在特徵向量方向上變換的幅度,幅度越大,說明這個方向上的元素差異也越大,換句話說這個方向上的元素更分散。
贊同 6111 條評論
分享
收藏感謝
![]()
8 人贊同了該回答
推薦一種看法吧,粗略描述如下:
把矩陣看成線性變換,找特徵值就是找這個線性變換下的不變自空間。
然後一些好的矩陣、線性變換,就可以分成好多個簡單的變換了。 不好的矩陣也可以作進一步處理,也能分解。
將複雜的東西變成很多簡單的東西,這是數學很美的一點。
很多應用也是基於這樣的直觀。 有時間再補充一些細節吧。
贊同 82 條評論
分享
收藏感謝
![]()
6 人贊同了該回答
如果把矩陣理解為空間變換的引數,那特徵值和特徵向量可這樣理解:
現在將x(m*1)向量按照A(m*m)矩陣進行空間變換,A矩陣的特徵向量為a1,a2,a3,...,am,特徵值為b1,b2,b3,...,bm。 可以把a1,a2,a3,...,am想象成m維座標系下的m根柱子,每根柱子都相當於一個有刻度的軌道,上邊有一個支點,空間系在這m個支點上,並且會因為支點的變化而變化。支點變化導致空間變化,空間變化導致空間中的向量變化。這個空間中的所有向量,都會隨著任何支點的變化而變化,被拉伸旋轉。
在原始空間的情況下,每根柱子的支點都在刻度1上。現在要對向量b按照A矩陣進行空間變換,則每根柱子上的支點按照b1,b2,b3,...,bm進行伸縮,空間隨之伸縮。而隨著空間在不同維度上不同量的伸縮,向量b也隨之被伸縮旋轉。
特徵向量決定了空間變化時,空間伸縮的不同方向,特徵值決定伸縮的程度。方向和特徵值相配合,使空間中的任何向量都發生了該矩陣所代表的空間變化。
贊同 61 條評論
分享
收藏感謝
![]()
153 人贊同了該回答
特徵值不僅僅是數學上的一個定義或是工具,特徵值是有具體含義的,是完全看得見摸得著的。
1. 比如說一個三維矩陣,理解成線性變換,作用在一個球體上:
三個特徵值決定了 對球體在三個維度上的拉伸/壓縮,把球體塑造成一個橄欖球;
剩下的部分決定了這個橄欖球在三維空間裡面怎麼旋轉。
2. 對於一個微分方程:
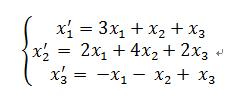
將係數提取出來
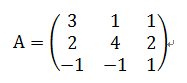
對角化:
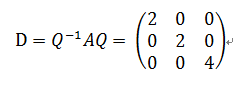
其中
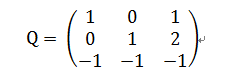
由於
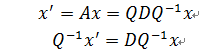
定義
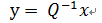
於是有
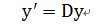
因此y的變化率與特徵值息息相關:
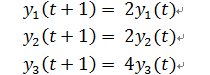
再將y由Q變換回x,我們就能得出x在不同時間的值。x的增長速度就是特徵值λ,Q用來把x旋轉成y。
贊同 15316 條評論
分享
收藏感謝收起
![]()
鵝廠 廣告演算法工程師
27 人贊同了該回答
站線上性變換的角度來看矩陣的話。 矩陣(線性變換)作用在一個向量上無非是將該向量伸縮(包括反向伸縮)與旋轉。 忽略複雜的旋轉變換,只考慮各個方向(特徵方向)伸縮的比例,所提取出的最有用,最關鍵的資訊就是特徵值了。
贊同 278 條評論
分享
收藏感謝
![]()
1 人贊同了該回答
拋個磚
如果某個物理系統的若干變數的關係可用含引數的矩陣表示。引數滿足特徵方程時,齊次形式表明此時的系統變數在輸入為零時可達無窮大,表明系統在該引數下不穩定。故特徵值由系統引數決定,並可反求之。
贊同 1新增評論
分享
收藏感謝
![]()
數學 & 汽車
14 人贊同了該回答
什麼是方陣?方陣就是n維線性空間上的線性變換。那麼我們總要考慮最簡單的情況: