
邏輯迴歸中如何應用梯度下降演算法與損失函式
前面一篇部落格介紹了關於梯度下降演算法來由以及說明了為什麼梯度的負方向就是梯度下降最快方向,本文將會在上文的知識下簡述在邏輯迴歸(Logistic Regression)中為什麼可以使用以及如何使用梯度下降演算法。
梯度下降演算法是個比較簡單容易理解的演算法,就像吳老師或很多資料上記載的一樣:每次從新起點尋找一個到達目的地最快的方向並移動一定距離,以此重複直到終點。對於目標函式是凸函式,則可以到達全域性最優點(非凸函式則可能到達區域性最優點)。
很多人聽完介紹或者看完圖片就能理解其思想,但對於其中的數學原理或公式推導則比較迷茫,由此前面一篇文章專門對梯度下降演算法的由來做了介紹,其中的思想簡略表達就是:
通過區域性線性相似的原理求得一階泰勒展開式,利用遞降的思想轉化展開式中的部分公式,再利用兩向量相乘最小值的餘弦思想求得公式中的值,最後得出公式。
正文:
本文將不再敘述梯度下降原始由來的公式推導,而講述其具體的方法在邏輯迴歸中的使用。
對於一般的簡單資料點,我們也可以使用線性迴歸來預測,將作為分界點,但是這樣也會存在誤分的情況,並且還會出現負值的情況 。
Sigmoid函式:
所以我們通過引入Sigmoid函式將值壓縮到 ,且
作為分界點。
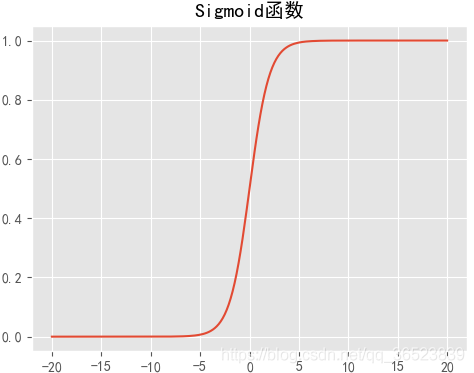
點處發生階躍變化,所以我們可以考慮將兩者結合起來,把線性迴歸的擬合結果通過Sigmoid函式壓縮到
。如果線性函式的
值越大,那概率也就越接近與
由此我們可以定義以下公式:
預測值:
Sigmoid壓縮:
一般情況,,
表示截距項,(為了滿足公式方便計算,一般會新增一列不會影響結果的
)。下面將兩個公式結合:
對數損失函式:
接下來就是重點了,在利用係數向量與特徵
求得結果時,如何度量該結果的可信程度?這裡就要使用到損失函式,我們用損失函式衡量預測值和真實值差異,不同於線性迴歸的最小二乘法,邏輯迴歸中通常使用對數損失函式,下面解釋。
並且這裡強調一點,可能有人一直搞不清楚邏輯迴歸中哪裡用到了梯度下降演算法,或者邏輯迴歸中是如何使用梯度下降演算法的。現在就是答案了,邏輯迴歸中我們使用梯度下降來最優化損失函式,當該函式值最小,即擬合效果最佳 。
現在來說說為什麼不使用平方損失函式?通過數學上的解釋:設定損失函式的目的是接下來通過最優化方法求得損失函式的最小值,損失最小即代表模型最優。在最優化求解中,只有凸函式才能求得全域性最小值,非凸函式往往得到的是區域性最優。然而,平方損失函式用於邏輯迴歸求解時得到的是非凸函式,即大多數情況下無法求得全域性最優。所以,這裡使用了對數損失函式避免這個問題。
所以我們對對數損失函式求偏導,得到梯度方向(過程省略):
(矩陣中即每條樣本的每個特徵與對應誤差矩陣相乘,再除樣本數)
有了梯度方向後,又要引入一個概念 ——步長,由於上面求得的只是最值的移動方向,而並沒有距離上的移動,所以引入一個引數,步長
一般又叫學習率,該值太大區域性線性近似就不成立,偏差較大;該值太小收斂太慢,導致一個長時間的訓練。所以後續調參需要注意該值的選擇。
有了學習率與梯度方向,現在就可以通過多次迭代使用梯度下降來優化對數損失函式,過程如下:
程式碼示例:
上面將部分概念與公式給出,下面利用程式碼來敘述:
# Sigmoid 函式
def sigmoid(z):
sigmoid = 1.0 / (1.0 + np.exp(-z))
return sigmoid
# 對數損失函式
def loss(h, y):
loss = (-y * np.log(h) - (1 - y) * np.log(1 - h)).mean()
return loss
# 梯度方向
def gradient(X, h, y):
gradient = np.dot(X.T, (h - y)) / y.shape[0]
return gradient
# 邏輯迴歸過程
def Logistic_Regression(x, y, lr=0.05, count=200):
intercept = np.ones((x.shape[0], 1)) # 初始化截距為 1
x = np.concatenate((intercept, x), axis=1)
w = np.zeros(x.shape[1]) # 初始化引數為 0
for i in range(count): # 梯度下降迭代
z = np.dot(x, w) # 線性函式
h = sigmoid(z)
g = gradient(x, h, y) # 計算梯度
w -= lr * g # 通過學習率 lr 計算步長並執行梯度下降
l = loss(h, y) # 計算損失函式值
return l, w # 返回迭代後的梯度和引數
l,w = Logistic_Regression(x, y, lr, count) # x特徵矩陣,y目標值參考文章: