
機器學習中“批量梯度下降”公式推導
之前在看批量梯度下降的時候,看到代價函式J(w)的求導過程中,一直搞不明白它是怎麼推匯出來的,今天終於把它推匯出來了。(注:下面文字中加粗的字母即為向量)
原始的代價函式如下所示:
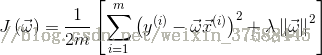
J(w)就是代價函式,其中w 是需要求出的引數向量,m 表示為訓練樣本個數,(x(i), y(i))就是其中的一個訓練樣本點,前面的求和項是實際值和預測值的誤差總和,後面的lamda 項為正則項,暫且理解為懲罰項,這個是為了避免overfitting的。
之後對J(w) 求導,可得如下公式:
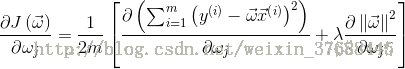
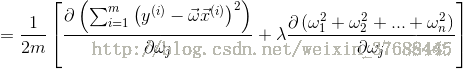
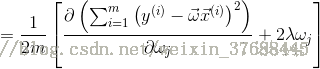
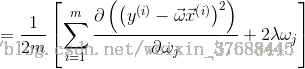
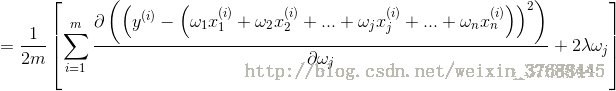
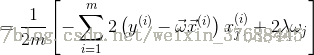
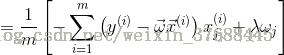
上述式子就是最終結果了,看到網上有很多的人都把中括號中的求和項的正負號顛倒了,所以說想在這裡確認一下。
之後更新步長(或者學習率learning rate),迭代之類的云云網上已經說了很多了,在這裡就不一一贅述了,只是把自己覺得不懂的地方寫下來,希望能夠幫助大家理解批量梯度下降以及之後的隨機梯度下降。
相關推薦
機器學習中“批量梯度下降”公式推導
之前在看批量梯度下降的時候,看到代價函式J(w)的求導過程中,一直搞不明白它是怎麼推匯出來的,今天終於把它推匯出來了。(注:下面文字中加粗的字母即為向量) 原始的代價函式如下所示: J(w)就是代價函式,其中w 是需要求出的引數向量,m 表示為訓練樣本個
講透機器學習中的梯度下降
本文始發於個人公眾號:TechFlow,原創不易,求個關注 在之前的文章當中,我們一起推導了線性迴歸的公式,今天我們繼續來學習上次沒有結束的內容。 上次我們推導完了公式的時候,曾經說過由於有許多的問題,比如最主要的複雜度問題。隨著樣本和特徵數量的增大,通過公式求解的時間會急劇增大,並且如果特徵為空,還會出現
學習中的梯度下降Ⅱ-學習率
減少 自動 cnblogs 需要 學習 ges com 技術 聲明 調試梯度下降。用x軸上的叠代數繪制一個圖。現在測量成本函數,J(θ)隨叠代次數下降。如果J(θ)不斷增加,那麽你可能需要減少α。 自動收斂試驗。如果該聲明收斂(θ)小於E在一次叠代中減少,其中E是一些小
【機器學習】對梯度下降算法的進一步理解
獨立 com 線性回歸 執行 ont 執行過程 wid 簡單的 技術 單一變量的線性回歸 讓我們依然以房屋為例,如果輸入的樣本特征是房子的尺寸,我們需要研究房屋尺寸和房屋價格之間的關系,假設我們的回歸模型訓練集如下 其中我們用 m表示訓練集實例中的實例數量, x代表特
吳恩達機器學習視訊筆記——梯度下降簡化技巧
房價預測 多個因素作用下,即θ有多個的情況下,如何得到假設函式。 第二行的訓練樣本,用矩陣進行表示如下: 同樣,假設函式在4個變數的情況下,其表示方法為: 有n個因素作用的情況下(即預設X0 = 1):
機器學習中的梯度消失、爆炸原因及其解決方法(筆記1)
前言 本文主要深入介紹深度學習中的梯度消失和梯度爆炸的問題以及解決方案。本文分為三部分,第一部分主要直觀的介紹深度學習中為什麼使用梯度更新,第二部分主要介紹深度學習中梯度消失及爆炸的原因,第三部分對提出梯度消失
【機器學習】基於梯度下降法的自線性迴歸模型
回顧 關於梯度下降法 以及線性迴歸的介紹,我們知道了: 線性迴歸的損失函式為: J (
【機器學習三】梯度下降法K-means優化演算法
K-means演算法延伸 對於之前的一篇文章中說過K-means雖然效果可以,但是對給定的K值敏感,簇中心位置敏感以及計算量大。所以針對以上兩點有了一些優化的方法。 對於給定的K值偏大或者偏小都將影響聚類效果。而由於對於需要聚類的資料本身沒有一個y值即分類值,這正是需要演算法最後得出的。所以
【機器學習二】梯度下降法KMeans
KMeans聚類的思想: 給定一個有M個物件的資料集,構建一個具有k個簇的模型,其中k<=M。滿 足以下條件: • 每個簇至少包含一個物件 • 每個物件屬於且僅屬於一個簇 • 將滿足上述條件的k個簇成為一個合理的聚類劃分 • 基本思想:對於給定的類別數目k,首先給定初始劃分,通過迭代改
機器學習1:梯度下降(Gradient Descent)
分別求解損失函式L(w,b)對w和b的偏導數,對於w,當偏導數絕對值較大時,w取值移動較大,反之較小,通過不斷迭代,在偏導數絕對值接近於0時,移動值也趨近於0,相應的最小值被找到。 η選取一個常數引數,前面的負號表示偏導數為負數時(即梯度下降時),w向增大的地方移動。 對於非單調函式,
入門|詳解機器學習中的梯度消失、爆炸原因及其解決方法
前言: 本文主要深入介紹深度學習中的梯度消失和梯度爆炸的問題以及解決方案。本文分為三部分,第一部分主要直觀的介紹深度學習中為什麼使用梯度更新,第二部分主要介紹深度學習中梯度消失及爆炸的原因,第三部分對提出梯度消失及爆炸的解決方案。有基礎的同鞋可以跳著閱讀。 其中,梯度
深度學習中的梯度下降優化演算法綜述
1 簡介 梯度下降演算法是最常用的神經網路優化演算法。常見的深度學習庫也都包含了多種演算法進行梯度下降的優化。但是,一般情況下,大家都是把梯度下降系列演算法當作是一個用於進行優化的黑盒子,不瞭解它們的優勢和劣勢。 本文旨在幫助讀者構建各種優化演算法的直觀理解,以幫助你在訓練神經網
Andrew Ng機器學習筆記2——梯度下降法and最小二乘擬合
今天正式開始學習機器學習的演算法,老師首先舉了一個例項:已知某地區的房屋面積與價格的一個數據集,那麼如何預測給定房屋面積的價格呢?我們大部分人可以想到的就是將畫出房屋面積與價格的散點圖,然後擬合出價格關於面積的曲線,那麼對於一個已知的房屋面積,就可以在擬合的曲線上得到預測的
logstic迴歸損失函式及梯度下降公式推導
Logistic迴歸cost函式的推導過程。演算法求解使用如下的cost函式形式: 梯度下降演算法 對於一個函式,我們要找它的最小值,有多種演算法,這裡我們選擇比較容易用程式碼實現和符合機器學習步驟的梯度下降演算法。 先來看看梯度下降演算法中,自變數的迭代
機器學習筆記之梯度下降法
梯度下降法/批量梯度下降法BGD 梯度下降法是一種基於搜尋的最優化方法,即通過不斷地搜尋找到函式的最小值.並不是機器學習專屬的方法.但是在機器學習演算法中求解損失函式的最小值時很常用. 還記得之前說過的機器學習演算法的普遍套路嗎? 定義一個合理的損失函式 優化這個損失函式,求解最小值.
【八】機器學習之路——梯度下降法python實現
前面的部落格線性迴歸python實現講了如何用python裡sklearn自帶的linearRegression()函式來擬合數據的實現方式。今天咱們來介紹下,如何用梯度下降法擬合數據。 還記得梯度下降法是怎麼做的嗎?忘記的同學可以回頭看下前面的部落格
吳恩達機器學習筆記10-梯度下降法實踐1-特征縮放
alt style span 技術分享 嘗試 最簡 學習 梯度下降法 實踐 在我們面對多維特征問題的時候,我們要保證這些特征都具有相近的尺度,這將幫助梯度下降算法更快地收斂。 以房價問題為例,假設我們使用兩個特征,房屋的尺寸和房間的數量,尺寸的值為 0-2000 平方
吳恩達機器學習筆記11-梯度下降法實踐2-學習率
測試 根據 圖片 提前 size 技術分享 次數 梯度下降 mage 梯度下降算法收斂所需要的叠代次數根據模型的不同而不同,我們不能提前預知,我們可以繪制叠代次數和代價函數的圖表來觀測算法在何時趨於收斂。 也有一些自動測試是否收斂的方法,例如將代價函數的變化值與某
機器學習--線性迴歸--梯度下降的實現
## 機器學習--線性單元迴歸--單變數梯度下降的實現 ### 【線性迴歸】 ```text 如果要用一句話來解釋線性迴歸是什麼的話,那麼我的理解是這樣子的: **線性迴歸,是從大量的資料中找出最優的線性(y=ax+b)擬合函式,通過資料確定函式中的未知引數,進而進行後續操作(預測) **迴歸的概念是從統
Stanford機器學習課程(Andrew Ng) Week 1 Parameter Learning --- 線性迴歸中的梯度下降法
本節將梯度下降與代價函式結合,並擬合到線性迴歸的函式中 這是我們上兩節課得到的函式,包括: 梯度下降的公式 用於擬合的線性假設和h(x) 平方誤差代價函式 J